Zero-Shot Decision Tree Construction via Large Language Models
作者: Lucas Carrasco, Felipe Urrutia, Andrés Abeliuk
分类: cs.LG, cs.CL
发布日期: 2025-01-27
💡 一句话要点
提出一种基于大语言模型的零样本决策树构建方法,无需训练数据。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 决策树 大语言模型 知识驱动 可解释性
📋 核心要点
- 传统决策树构建依赖大量标注数据,面临数据稀缺时的挑战。
- 利用大语言模型(LLM)的预训练知识,无需训练数据即可构建决策树。
- 实验表明,该零样本决策树方法性能优于基线,并与监督方法具竞争力。
📝 摘要(中文)
本文提出了一种新颖的算法,利用大语言模型(LLM)以零样本方式构建决策树,该方法基于分类与回归树(CART)的原则。传统的决策树归纳方法严重依赖于带标签的数据,通过诸如信息增益或基尼指数等标准递归地划分数据。相比之下,我们提出了一种利用LLM中嵌入的预训练知识来构建决策树的方法,而无需训练数据。我们的方法利用LLM执行决策树构建所必需的操作,包括属性离散化、概率计算以及基于概率的基尼指数计算。我们表明,这些零样本决策树可以优于基线零样本方法,并在表格数据集上实现与监督数据驱动的决策树相比具有竞争力的性能。通过这种方法构建的决策树提供了透明且可解释的模型,在解决数据稀缺问题的同时保持了可解释性。这项工作在低数据机器学习中建立了一个新的基线,为数据驱动的树构建提供了一种基于原则、知识驱动的替代方案。
🔬 方法详解
问题定义:论文旨在解决在缺乏标注数据的情况下构建决策树的问题。传统决策树算法,如CART,依赖于信息增益或基尼指数等指标来划分节点,需要大量的标注数据进行训练。当数据稀缺时,这些算法的性能会显著下降。
核心思路:论文的核心思路是利用大语言模型(LLM)中蕴含的丰富知识,直接进行决策树的构建,而无需额外的训练数据。通过提示工程,引导LLM完成属性离散化、概率计算和基尼指数计算等任务,从而实现零样本决策树的构建。
技术框架:该方法主要包含以下几个阶段:1) 属性离散化:利用LLM将连续属性离散化为多个区间。2) 概率计算:使用LLM计算每个离散属性值下,样本属于不同类别的概率。3) 基尼指数计算:基于LLM计算的概率,计算每个属性划分的基尼指数。4) 决策树构建:根据基尼指数选择最优划分属性,递归地构建决策树。
关键创新:该方法最重要的创新点在于利用LLM的预训练知识,实现了零样本决策树的构建。与传统方法相比,该方法无需训练数据,可以直接应用于数据稀缺的场景。此外,该方法构建的决策树具有良好的可解释性,易于理解和分析。
关键设计:在属性离散化阶段,需要设计合适的提示语,引导LLM将连续属性划分为合理的区间。在概率计算阶段,需要设计合适的提示语,引导LLM准确估计样本属于不同类别的概率。基尼指数的计算公式与传统CART算法相同。决策树的停止生长条件可以根据实际情况进行调整,例如设置最大深度或最小样本数。
🖼️ 关键图片

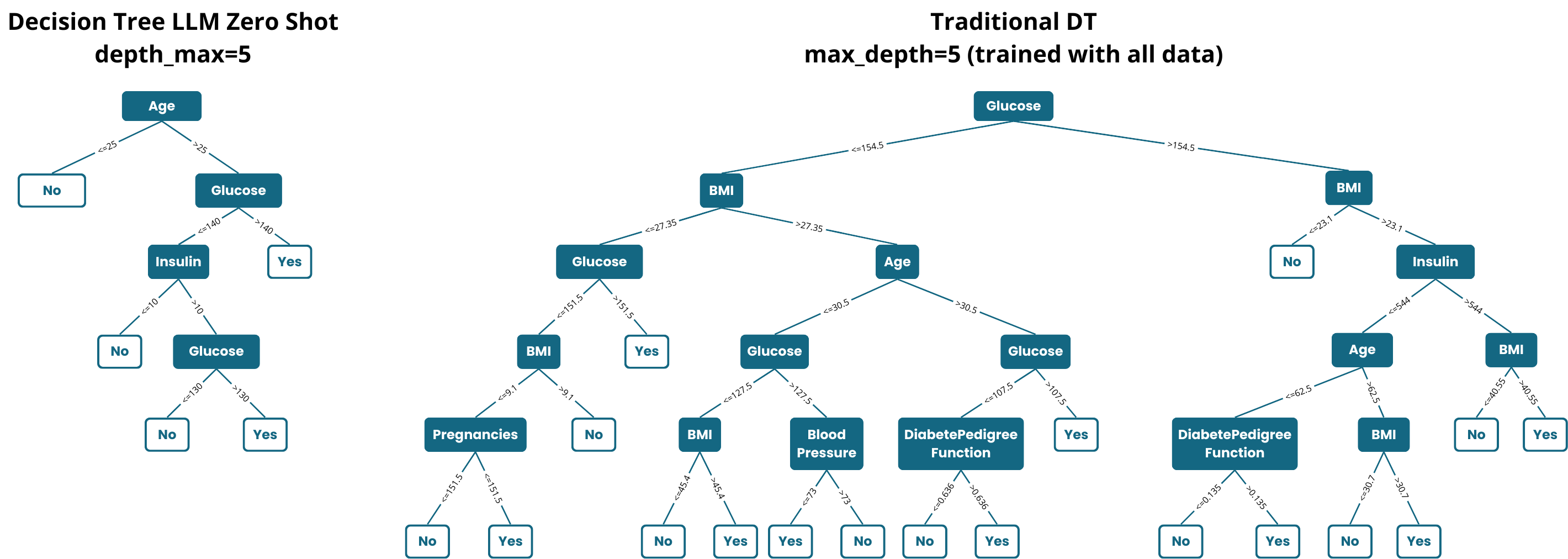
📊 实验亮点
实验结果表明,该零样本决策树方法在多个表格数据集上取得了良好的性能。与基线零样本方法相比,该方法取得了显著的性能提升。此外,该方法在某些数据集上甚至可以与监督数据驱动的决策树方法相媲美,证明了该方法的有效性和潜力。
🎯 应用场景
该研究成果可应用于数据稀缺的领域,例如医疗诊断、金融风控等。在这些领域,获取大量标注数据往往成本高昂或难以实现。该方法可以利用LLM的知识,快速构建可解释的决策模型,辅助决策,具有重要的实际应用价值和潜力。未来,该方法可以进一步扩展到其他机器学习任务中,例如规则提取、知识发现等。
📄 摘要(原文)
This paper introduces a novel algorithm for constructing decision trees using large language models (LLMs) in a zero-shot manner based on Classification and Regression Trees (CART) principles. Traditional decision tree induction methods rely heavily on labeled data to recursively partition data using criteria such as information gain or the Gini index. In contrast, we propose a method that uses the pre-trained knowledge embedded in LLMs to build decision trees without requiring training data. Our approach leverages LLMs to perform operations essential for decision tree construction, including attribute discretization, probability calculation, and Gini index computation based on the probabilities. We show that these zero-shot decision trees can outperform baseline zero-shot methods and achieve competitive performance compared to supervised data-driven decision trees on tabular datasets. The decision trees constructed via this method provide transparent and interpretable models, addressing data scarcity while preserving interpretability. This work establishes a new baseline in low-data machine learning, offering a principled, knowledge-driven alternative to data-driven tree construction.