Rethinking the Bias of Foundation Model under Long-tailed Distribution
作者: Jiahao Chen, Bin Qin, Jiangmeng Li, Hao Chen, Bing Su
分类: cs.LG, cs.CV, stat.ML
发布日期: 2025-01-27 (更新: 2025-08-08)
备注: Published as a conference paper in ICML 2025
🔗 代码/项目: GITHUB
💡 一句话要点
针对长尾分布下预训练模型偏差,提出基于因果学习的解耦方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长尾学习 预训练模型 因果学习 后门调整 模型偏差 数据不平衡 参数不平衡
📋 核心要点
- 现有方法忽略了预训练模型在长尾数据上训练时产生的偏差,导致下游任务性能受限。
- 提出基于因果学习的后门调整方法,解耦输入样本和标签之间的虚假相关性,学习真实因果效应。
- 实验表明,该方法在多个长尾数据集上取得了显著的性能提升,平均提升约1.67%。
📝 摘要(中文)
长尾学习因其在实际应用中的重要性而受到越来越多的关注。在各种方法中,随着预训练模型的出现,微调范式受到了广泛关注。然而,大多数现有方法主要侧重于利用来自这些模型的知识,而忽略了它们所依赖的不平衡训练数据所带来的固有偏差。本文研究了预训练中的这种不平衡如何影响长尾下游任务。具体来说,我们发现预训练模型在下游任务中继承的不平衡偏差表现为参数不平衡和数据不平衡。在微调过程中,我们观察到参数不平衡起着更关键的作用,而数据不平衡可以使用现有的重平衡策略来缓解。此外,我们发现与数据不平衡不同,当前的重平衡技术(例如调整 logits)无法有效解决参数不平衡。为了同时解决这两种不平衡,我们基于因果学习构建了我们的方法,并将不完整的语义因素视为混淆因素,这带来了输入样本和标签之间的虚假相关性。为了解决这种负面影响,我们提出了一种新颖的后门调整方法,该方法学习输入样本和标签之间的真实因果效应,而不仅仅是拟合数据中的相关性。值得注意的是,我们在每个数据集上实现了约 1.67% 的平均性能提升。
🔬 方法详解
问题定义:论文旨在解决预训练模型在长尾分布数据上进行预训练后,在下游长尾任务中表现出的偏差问题。现有方法主要关注如何利用预训练模型的知识,而忽略了预训练数据本身的不平衡性对模型的影响。这种不平衡性导致模型在参数和数据层面都存在偏差,影响了下游任务的泛化能力。
核心思路:论文的核心思路是将预训练数据的不平衡性视为一种因果混淆,即存在一个不完整的语义因素(混淆因子)导致输入样本和标签之间产生虚假相关性。为了消除这种虚假相关性,论文采用因果学习中的后门调整方法,旨在学习输入样本和标签之间的真实因果效应,而不是简单地拟合数据中的相关性。
技术框架:该方法基于因果学习框架,主要包含以下几个步骤:1) 识别混淆因子:将预训练数据的不平衡性视为混淆因子,它同时影响输入样本和标签。2) 后门调整:通过后门调整方法,消除混淆因子对输入样本和标签之间因果关系的影响。具体来说,通过干预混淆因子,使得输入样本和标签之间的关系不再受到混淆因子的影响,从而学习到真实的因果效应。3) 模型微调:利用学习到的真实因果效应,对预训练模型进行微调,以适应下游长尾任务。
关键创新:该论文的关键创新在于将因果学习引入到长尾学习中,并提出了一种新颖的后门调整方法来解决预训练模型中的偏差问题。与现有方法不同,该方法不是简单地调整 logits 或采用重采样等策略,而是从因果关系的角度出发,消除混淆因子对模型的影响,从而学习到更鲁棒的特征表示。
关键设计:论文中后门调整的具体实现细节未知,摘要中没有详细说明如何进行干预以及如何消除混淆因子的影响。这部分是理解该方法的核心,需要查阅论文全文才能了解。
🖼️ 关键图片
📊 实验亮点
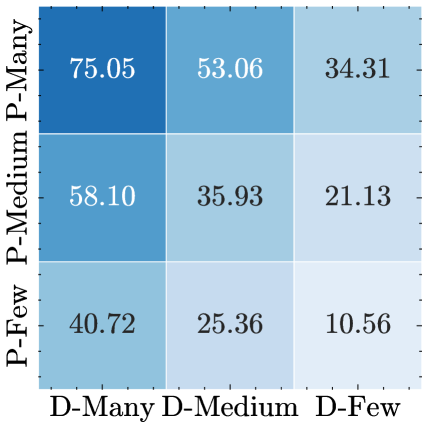
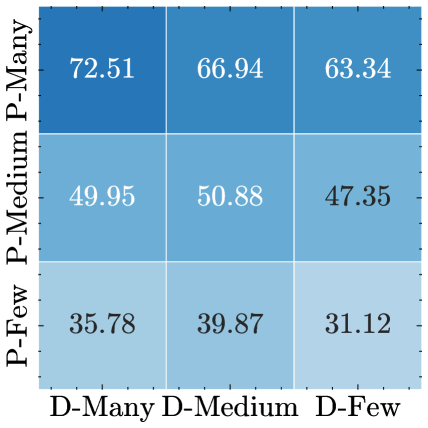
实验结果表明,该方法在多个长尾数据集上取得了显著的性能提升,平均提升约1.67%。这表明该方法能够有效地消除预训练模型中的偏差,并提高模型在下游任务中的性能。具体的实验设置、数据集和对比基线未知,需要查阅论文全文才能了解。
🎯 应用场景
该研究成果可应用于各种存在长尾分布的数据集,例如图像识别、自然语言处理等领域。通过消除预训练模型中的偏差,可以提高模型在实际应用中的泛化能力和鲁棒性,尤其是在数据不平衡的情况下。该方法有助于提升人工智能系统在现实世界中的表现,例如在医疗诊断、金融风控等领域。
📄 摘要(原文)
Long-tailed learning has garnered increasing attention due to its practical significance. Among the various approaches, the fine-tuning paradigm has gained considerable interest with the advent of foundation models. However, most existing methods primarily focus on leveraging knowledge from these models, overlooking the inherent biases introduced by the imbalanced training data they rely on. In this paper, we examine how such imbalances from pre-training affect long-tailed downstream tasks. Specifically, we find the imbalance biases inherited in foundation models on downstream task as parameter imbalance and data imbalance. During fine-tuning, we observe that parameter imbalance plays a more critical role, while data imbalance can be mitigated using existing re-balancing strategies. Moreover, we find that parameter imbalance cannot be effectively addressed by current re-balancing techniques, such as adjusting the logits, during training, unlike data imbalance. To tackle both imbalances simultaneously, we build our method on causal learning and view the incomplete semantic factor as the confounder, which brings spurious correlations between input samples and labels. To resolve the negative effects of this, we propose a novel backdoor adjustment method that learns the true causal effect between input samples and labels, rather than merely fitting the correlations in the data. Notably, we achieve an average performance increase of about $1.67\%$ on each dataset. Code is available: https://github.com/JiahaoChen1/Pre-train-Imbalance