Benchmarking Quantum Reinforcement Learning
作者: Nico Meyer, Christian Ufrecht, George Yammine, Georgios Kontes, Christopher Mutschler, Daniel D. Scherer
分类: quant-ph, cs.LG
发布日期: 2025-01-27 (更新: 2025-05-21)
备注: Accepted to the 42nd International Conference on Machine Learning (ICML 2025), Vancouver, British Columbia, Canada. 31 pages, 20 figures, 3 tables
期刊: Proceedings of the 42nd International Conference on Machine Learning, PMLR 267:43934-43964, 2025
💡 一句话要点
提出一种量子强化学习的基准测试方法,用于评估和验证量子算法的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子强化学习 基准测试 统计验证 样本复杂度 量子优势
📋 核心要点
- 强化学习基准测试缺乏统一标准,统计验证困难,阻碍了算法的公平比较和发展。
- 提出基于样本复杂度统计估计器和统计优越性定义的新基准测试方法,用于量化评估QRL算法。
- 实验结果表明,QRL的优势可能不如先前研究所宣称的显著,需要更细致的评估和分析。
📝 摘要(中文)
强化学习(RL)的基准测试和建立适当的统计验证指标仍然是持续存在的挑战,尚未达成共识。量子计算的出现及其在量子强化学习(QRL)中的潜在应用进一步复杂化了基准测试工作。为了实现有效的性能比较并简化当前在该领域的研究,我们提出了一种新的基准测试方法,该方法基于样本复杂度的统计估计器和统计优越性的定义。此外,考虑到QRL,我们的方法对之前关于其优越性的一些说法提出了质疑。我们在一个具有灵活复杂程度的新型基准测试环境中进行了实验。虽然我们仍然发现了可能的优势,但我们的发现总体上更为细致。我们讨论了这些结果的潜在局限性,并探讨了它们对QRL中量子优势的实证研究的影响。
🔬 方法详解
问题定义:现有的强化学习基准测试方法缺乏统一的标准和有效的统计验证指标,使得不同算法之间的性能比较变得困难。尤其是在量子强化学习(QRL)领域,由于量子算法的复杂性和资源限制,如何准确评估其性能并判断其是否优于经典算法是一个关键问题。之前的研究可能存在对QRL优势的过度乐观估计。
核心思路:论文的核心思路是建立一套更加严谨的基准测试方法,该方法基于统计学原理,能够更准确地评估QRL算法的性能,并判断其是否在统计意义上优于经典算法。通过引入样本复杂度的统计估计器和统计优越性的定义,可以量化评估算法的性能,并避免因样本量不足或统计偏差导致的错误结论。
技术框架:该基准测试方法主要包含以下几个阶段:1) 定义具有不同复杂度的基准测试环境;2) 使用统计估计器估计算法的样本复杂度;3) 定义统计优越性的概念,用于判断一个算法是否在统计意义上优于另一个算法;4) 在基准测试环境中运行QRL和经典RL算法,并使用该方法评估它们的性能;5) 分析实验结果,并讨论QRL的潜在优势和局限性。
关键创新:该方法最重要的创新点在于引入了样本复杂度的统计估计器和统计优越性的定义,从而能够更加严谨地评估QRL算法的性能。与传统的基准测试方法相比,该方法能够更好地控制统计误差,并避免因样本量不足或统计偏差导致的错误结论。此外,该方法还提供了一个灵活的基准测试环境,可以根据需要调整环境的复杂度,从而更好地评估算法在不同场景下的性能。
关键设计:论文中,样本复杂度的统计估计器具体实现方式未知,但其目的是估计算法达到特定性能所需的样本数量。统计优越性的定义基于假设检验,用于判断一个算法的性能是否显著优于另一个算法。基准测试环境的设计需要考虑环境的复杂度、状态空间和动作空间的大小等因素。具体的参数设置、损失函数和网络结构取决于所使用的QRL和经典RL算法。
🖼️ 关键图片

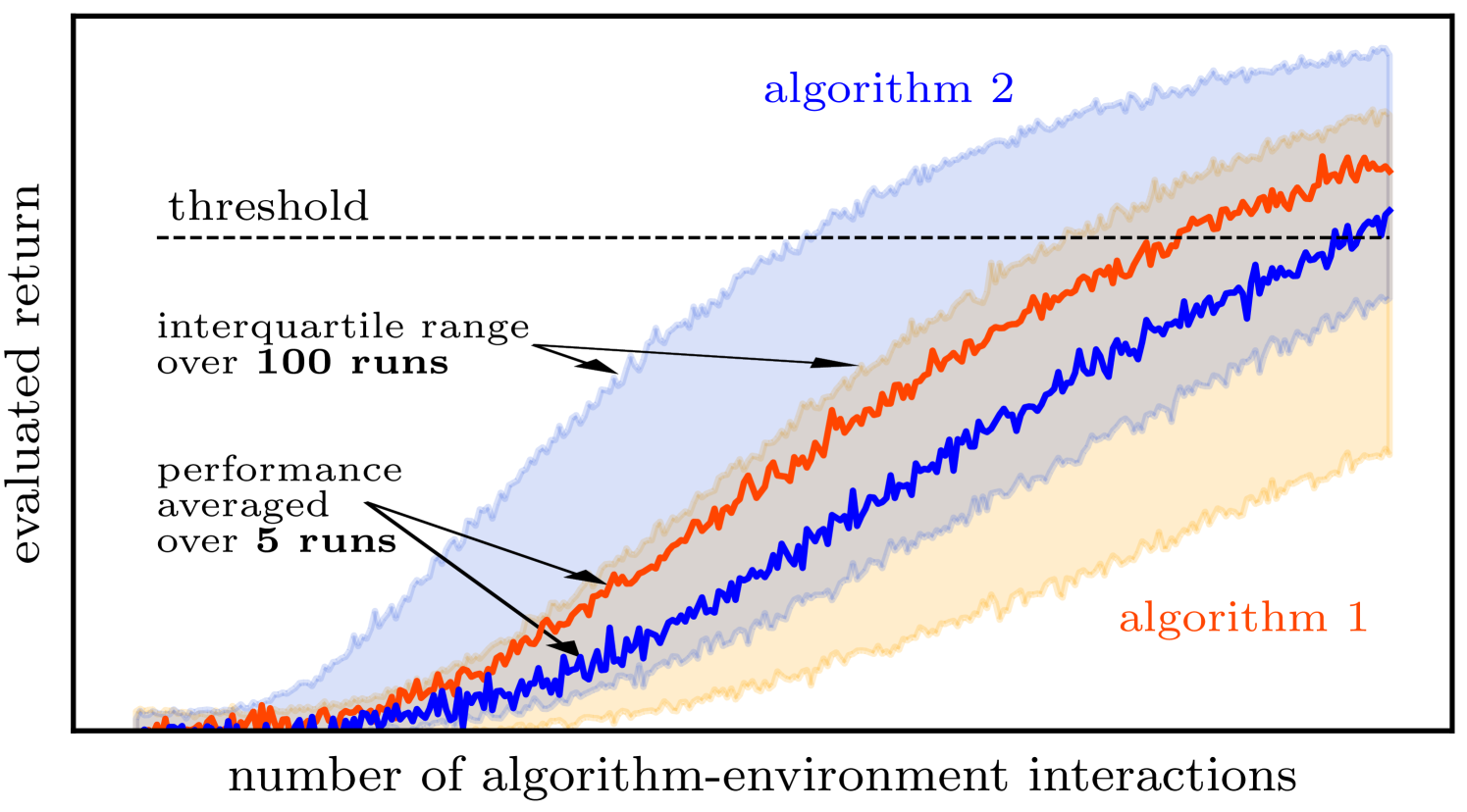

📊 实验亮点
实验结果表明,尽管QRL在某些情况下可能表现出优势,但其优势可能不如先前研究所宣称的显著。该研究强调了在评估QRL算法时,需要采用更加严谨的统计方法,并考虑样本复杂度和统计误差的影响。该研究为QRL的未来研究方向提供了新的视角,并为量子优势的实证研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于量子强化学习算法的评估与优化,加速量子算法在金融、交通、控制等领域的实际应用。通过更准确的性能评估,可以更好地识别具有实际优势的量子算法,并指导算法设计和硬件开发,最终推动量子计算在解决实际问题中的应用。
📄 摘要(原文)
Benchmarking and establishing proper statistical validation metrics for reinforcement learning (RL) remain ongoing challenges, where no consensus has been established yet. The emergence of quantum computing and its potential applications in quantum reinforcement learning (QRL) further complicate benchmarking efforts. To enable valid performance comparisons and to streamline current research in this area, we propose a novel benchmarking methodology, which is based on a statistical estimator for sample complexity and a definition of statistical outperformance. Furthermore, considering QRL, our methodology casts doubt on some previous claims regarding its superiority. We conducted experiments on a novel benchmarking environment with flexible levels of complexity. While we still identify possible advantages, our findings are more nuanced overall. We discuss the potential limitations of these results and explore their implications for empirical research on quantum advantage in QRL.