Decentralized Low-Rank Fine-Tuning of Large Language Models
作者: Sajjad Ghiasvand, Mahnoosh Alizadeh, Ramtin Pedarsani
分类: cs.LG
发布日期: 2025-01-26 (更新: 2025-08-21)
💡 一句话要点
提出Dec-LoRA,实现大型语言模型在去中心化环境下的低秩微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 去中心化学习 大型语言模型 参数高效微调 低秩适应 联邦学习 数据隐私 分布式训练
📋 核心要点
- 现有参数高效微调方法通常依赖集中式数据,无法直接应用于分布式、隐私敏感的场景。
- Dec-LoRA基于LoRA,通过去中心化学习实现LLM的微调,无需中央服务器进行参数聚合。
- 实验表明,Dec-LoRA在数据异构和量化约束下,性能与中心化LoRA相当,并提供收敛性理论保证。
📝 摘要(中文)
参数高效微调(PEFT)技术,如低秩适应(LoRA),为大型语言模型(LLM)提供了计算高效的适配方法,但其实际部署通常假设集中式数据和训练环境。然而,现实场景经常涉及分布式、隐私敏感的数据集,需要去中心化解决方案。联邦学习(FL)通过协调客户端之间的模型更新来解决数据隐私问题,但它通常基于通过参数服务器的集中式聚合,这会引入瓶颈和通信约束。相比之下,去中心化学习通过实现客户端之间的直接协作来消除这种依赖性,从而提高分布式环境中的可扩展性和效率。尽管具有优势,但去中心化LLM微调仍未得到充分探索。在这项工作中,我们提出Dec-LoRA,一种基于LoRA的LLM去中心化微调算法。通过对BERT和LLaMA-2模型的大量实验,我们证明Dec-LoRA在各种条件下(包括数据异构和量化约束)实现了与中心化LoRA相当的性能。此外,我们提供了严格的理论保证,证明了我们的算法对于非凸和平滑损失函数收敛到平稳点。这些发现突出了Dec-LoRA在去中心化环境中可扩展LLM微调的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在去中心化环境下的高效微调问题。现有的参数高效微调方法,如LoRA,通常假设数据是集中式的,这在实际应用中存在局限性,尤其是在涉及隐私敏感数据时。联邦学习虽然可以解决隐私问题,但其中心化的参数服务器会带来通信瓶颈和单点故障风险。因此,如何在去中心化的环境中高效地微调LLM是一个重要的挑战。
核心思路:Dec-LoRA的核心思路是利用去中心化学习框架,结合LoRA的参数高效微调能力,实现LLM在各个客户端上的独立微调,并通过客户端之间的直接通信来共享和聚合模型更新,从而避免了对中央服务器的依赖。这种设计旨在提高可扩展性、效率和隐私保护能力。
技术框架:Dec-LoRA的整体框架包括以下几个主要步骤:1) 初始化:所有客户端都拥有相同的预训练LLM和LoRA参数。2) 本地微调:每个客户端使用本地数据独立地微调LoRA参数。3) 去中心化聚合:客户端之间通过某种通信协议(例如, gossip 算法)交换LoRA参数更新,并进行聚合。4) 模型更新:每个客户端使用聚合后的LoRA参数更新本地LLM。重复步骤2-4,直到模型收敛。
关键创新:Dec-LoRA的关键创新在于将LoRA与去中心化学习相结合,提出了一种新的LLM微调算法。与传统的联邦学习相比,Dec-LoRA不需要中央服务器,从而避免了通信瓶颈和单点故障。此外,Dec-LoRA还提供了理论保证,证明了算法在非凸和平滑损失函数下的收敛性。
关键设计:Dec-LoRA的关键设计包括:1) 使用LoRA进行参数高效微调,减少了通信开销。2) 采用Gossip算法进行去中心化参数聚合,保证了算法的可扩展性和鲁棒性。3) 设计了合适的学习率和聚合策略,以保证算法的收敛性。论文还考虑了数据异构性和量化约束对算法性能的影响,并提出了相应的优化策略。
🖼️ 关键图片


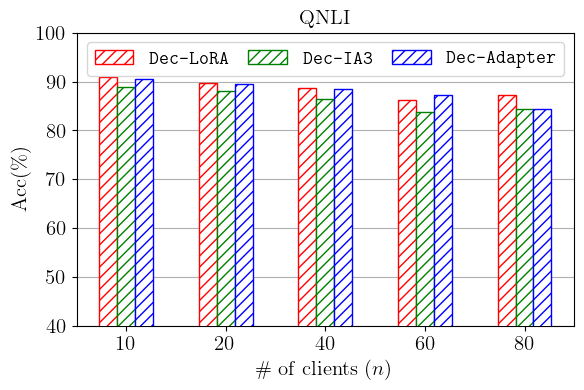
📊 实验亮点
实验结果表明,Dec-LoRA在BERT和LLaMA-2模型上取得了与中心化LoRA相当的性能,即使在数据异构和量化约束条件下也是如此。论文还提供了理论证明,保证了Dec-LoRA在非凸和平滑损失函数下的收敛性。这些结果表明,Dec-LoRA是一种有效的去中心化LLM微调算法,具有良好的可扩展性和鲁棒性。
🎯 应用场景
Dec-LoRA适用于需要保护数据隐私的分布式场景,例如医疗健康、金融服务和自动驾驶等领域。它可以帮助企业在不共享原始数据的情况下,利用各自的数据对LLM进行定制化微调,从而提高模型在特定任务上的性能。此外,Dec-LoRA还可以应用于边缘计算设备,实现LLM的本地部署和推理,降低延迟和带宽需求。
📄 摘要(原文)
While parameter-efficient fine-tuning (PEFT) techniques like Low-Rank Adaptation (LoRA) offer computationally efficient adaptations of Large Language Models (LLMs), their practical deployment often assumes centralized data and training environments. However, real-world scenarios frequently involve distributed, privacy-sensitive datasets that require decentralized solutions. Federated learning (FL) addresses data privacy by coordinating model updates across clients, but it is typically based on centralized aggregation through a parameter server, which can introduce bottlenecks and communication constraints. Decentralized learning, in contrast, eliminates this dependency by enabling direct collaboration between clients, improving scalability and efficiency in distributed environments. Despite its advantages, decentralized LLM fine-tuning remains underexplored. In this work, we propose Dec-LoRA, a decentralized fine-tuning algorithm for LLMs based on LoRA. Through extensive experiments on BERT and LLaMA-2 models, we demonstrate that Dec-LoRA achieves performance comparable to centralized LoRA under various conditions, including data heterogeneity and quantization constraints. Additionally, we provide a rigorous theoretical guarantee proving the convergence of our algorithm to a stationary point for non-convex and smooth loss functions. These findings highlight the potential of Dec-LoRA for scalable LLM fine-tuning in decentralized environments.