FBQuant: FeedBack Quantization for Large Language Models
作者: Yijiang Liu, Hengyu Fang, Liulu He, Rongyu Zhang, Yichuan Bai, Yuan Du, Li Du
分类: cs.LG, cs.CL
发布日期: 2025-01-25 (更新: 2025-05-23)
备注: Accepted to IJCAI 2025
💡 一句话要点
提出FBQuant,利用反馈量化方法优化大语言模型,提升端侧部署精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型量化 边缘设备部署 反馈量化 模型压缩 CUDA优化
📋 核心要点
- 大语言模型端侧部署受限于边缘设备资源,权重仅量化虽能减少内存访问,但精度损失严重。
- FBQuant受负反馈机制启发,确保重构权重在量化范围内,降低过拟合风险,提升量化精度。
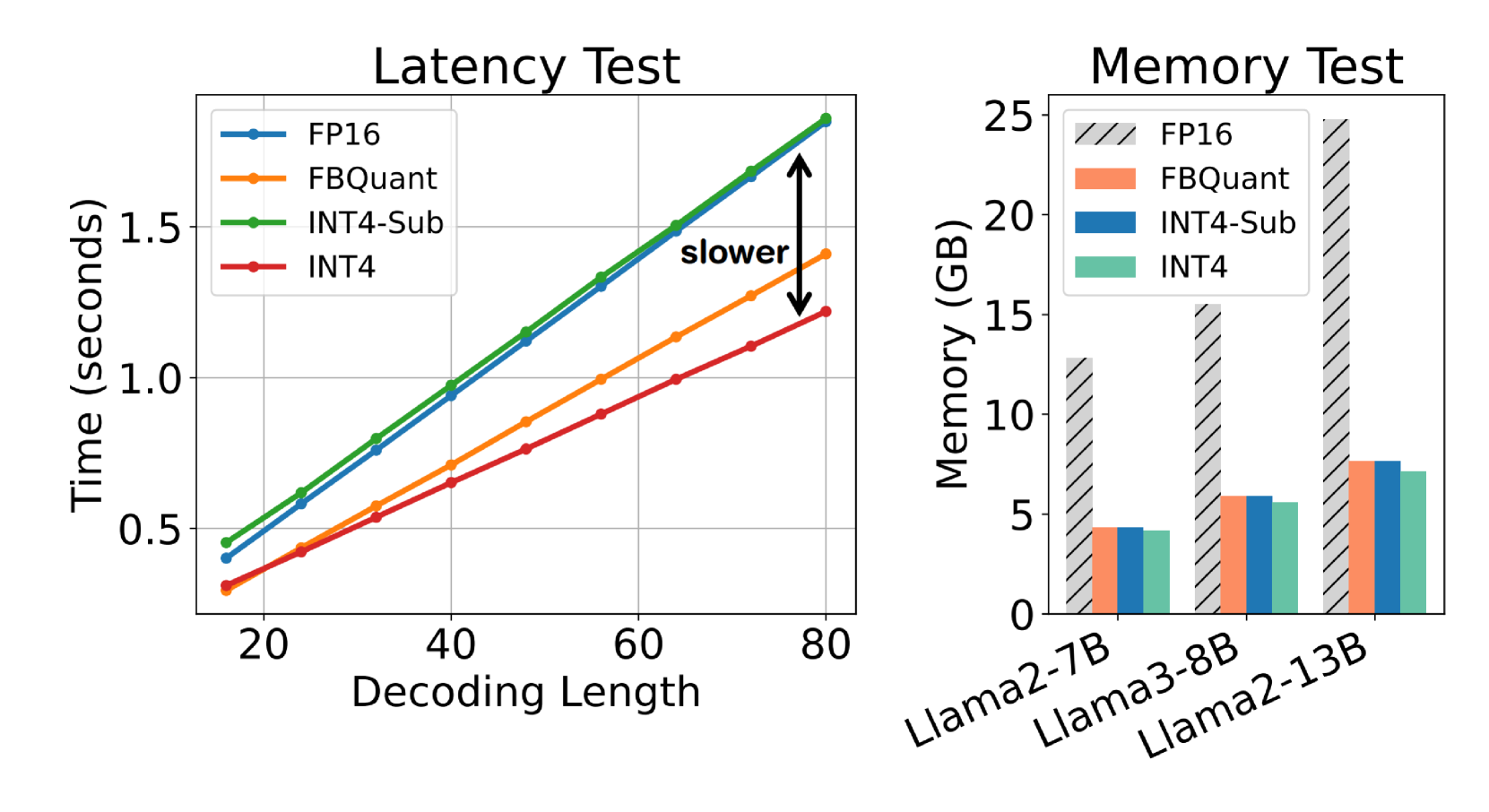
- 通过高效CUDA内核优化,FBQuant有效降低子分支引入的额外延迟,并在多种LLM上验证了其有效性。
📝 摘要(中文)
为了在边缘设备上部署大型语言模型(LLMs),以消除对网络连接的依赖、减少昂贵的API调用并增强用户隐私,本文提出了一种新颖的反馈量化(FBQuant)方法。由于边缘设备计算资源有限,模型量化是关键。虽然权重仅量化能有效减少内存访问,但通常会导致显著的精度下降。通过引入子分支来缓解量化误差的方法展现出潜力,但这些方法缺乏鲁棒的优化策略或依赖于次优目标。FBQuant受到自动控制中负反馈机制的启发,确保重构的权重保持在量化过程的界限内,从而降低过拟合的风险。为了抵消子分支引入的额外延迟,开发了一个高效的CUDA内核,减少了60%的额外推理时间。实验结果表明,FBQuant在各种LLM上都具有效率和有效性。例如,对于3-bit Llama2-7B,FBQuant将zero-shot精度提高了1.2%。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在边缘设备上部署时,由于内存带宽限制导致的权重加载瓶颈问题。现有的权重仅量化方法虽然能有效减少内存访问,但会造成显著的精度下降。而一些通过引入子分支来缓解量化误差的方法,要么缺乏鲁棒的优化策略,要么依赖于次优的目标函数,导致性能提升有限。
核心思路:FBQuant的核心思路是借鉴自动控制中的负反馈机制,将量化过程视为一个控制系统,通过反馈回路来约束重构的权重,使其始终保持在量化范围之内。这种方法能够有效地防止过拟合,并提高量化模型的精度。
技术框架:FBQuant的技术框架主要包括以下几个部分:首先,对原始权重进行量化得到量化后的权重;然后,引入一个子分支,该子分支的作用是学习一个残差,用于补偿量化带来的误差;接着,将量化后的权重和残差相加,得到重构的权重;最后,通过一个反馈回路,将重构的权重反馈到量化器中,用于调整量化参数,从而实现对量化过程的控制。为了加速推理,还设计了高效的CUDA kernel。
关键创新:FBQuant的关键创新在于引入了负反馈机制来控制量化过程。与现有的量化方法相比,FBQuant能够更有效地约束重构的权重,防止过拟合,并提高量化模型的精度。此外,针对子分支引入的额外延迟,论文还设计了高效的CUDA kernel,进一步提升了模型的推理速度。
关键设计:FBQuant的关键设计包括:1) 量化器的选择,论文中使用了多种量化器,包括均匀量化和非均匀量化;2) 子分支的网络结构,论文中使用了简单的线性层作为子分支;3) 反馈回路的设计,论文中使用了比例积分微分(PID)控制器来调整量化参数;4) 损失函数的设计,论文中使用了重构误差作为损失函数,并加入正则化项来防止过拟合。
🖼️ 关键图片


📊 实验亮点
FBQuant在多种LLM上进行了实验验证,结果表明其能够显著提高量化模型的精度。例如,对于3-bit Llama2-7B模型,FBQuant将zero-shot精度提高了1.2%。此外,通过高效的CUDA内核优化,FBQuant能够有效降低子分支引入的额外延迟,减少了60%的额外推理时间。
🎯 应用场景
FBQuant技术可广泛应用于各种需要端侧部署的大语言模型应用场景,例如智能手机上的AI助手、离线翻译、智能家居设备等。通过降低模型大小和提高推理速度,FBQuant使得这些应用能够在资源受限的设备上高效运行,同时保护用户隐私,减少对网络连接的依赖。
📄 摘要(原文)
Deploying Large Language Models (LLMs) on edge devices is increasingly important, as it eliminates reliance on network connections, reduces expensive API calls, and enhances user privacy. However, on-device deployment is challenging due to the limited computational resources of edge devices. In particular, the key bottleneck stems from memory bandwidth constraints related to weight loading. Weight-only quantization effectively reduces memory access, yet often induces significant accuracy degradation. Recent efforts to incorporate sub-branches have shown promise for mitigating quantization errors, but these methods either lack robust optimization strategies or rely on suboptimal objectives. To address these gaps, we propose FeedBack Quantization (FBQuant), a novel approach inspired by negative feedback mechanisms in automatic control. FBQuant inherently ensures that the reconstructed weights remain bounded by the quantization process, thereby reducing the risk of overfitting. To further offset the additional latency introduced by sub-branches, we develop an efficient CUDA kernel that decreases 60% of extra inference time. Comprehensive experiments demonstrate the efficiency and effectiveness of FBQuant across various LLMs. Notably, for 3-bit Llama2-7B, FBQuant improves zero-shot accuracy by 1.2%.