Technology Mapping with Large Language Models
作者: Minh Hieu Nguyen, Hien Thu Pham, Hiep Minh Ha, Ngoc Quang Hung Le, Jun Jo
分类: cs.IR, cs.DB, cs.ET, cs.LG
发布日期: 2025-01-25
备注: Technical Report
💡 一句话要点
提出STARS框架,利用大语言模型进行精准的企业技术栈图谱构建。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 技术图谱 大语言模型 语义检索 企业技术栈 Sentence-BERT
📋 核心要点
- 传统技术图谱构建依赖关键词搜索,无法有效处理海量异构数据,新兴技术难以被发现。
- STARS框架利用大语言模型和Sentence-BERT,从非结构化数据中提取技术信息,构建企业技术图谱。
- 实验结果表明,STARS显著提升了技术检索的准确率,为跨行业技术图谱构建提供有效方案。
📝 摘要(中文)
在当今快速发展的商业环境中,深入了解企业使用的技术栈对于建立合作关系、发现市场机会和制定战略决策至关重要。然而,传统的技术图谱构建方法通常依赖于关键词搜索,难以应对海量和多样化的数据,并且常常无法捕捉到新兴技术。为了克服这些挑战,我们提出了STARS(语义技术和检索系统),这是一个新颖的框架,它利用大型语言模型(LLM)和Sentence-BERT来精确定位非结构化内容中的相关技术,构建全面的公司概况,并根据每家公司技术在其运营中的重要性对其进行排序。通过将实体提取与思维链提示相结合,并采用语义排序,STARS提供了一种精确的方法来绘制企业技术组合图谱。实验结果表明,STARS显著提高了检索准确率,为跨行业技术图谱构建提供了一种通用且高性能的解决方案。
🔬 方法详解
问题定义:论文旨在解决传统技术图谱构建方法在处理海量非结构化数据时,无法准确识别和排序企业所使用技术的问题。现有方法依赖关键词搜索,容易遗漏新兴技术,且难以评估技术的重要性。
核心思路:论文的核心思路是利用大型语言模型(LLM)的语义理解能力,从非结构化文本中提取技术实体,并结合Sentence-BERT进行语义排序,从而构建更全面、更准确的企业技术图谱。这种方法能够捕捉到关键词搜索无法识别的潜在技术,并根据技术在企业运营中的重要性进行排序。
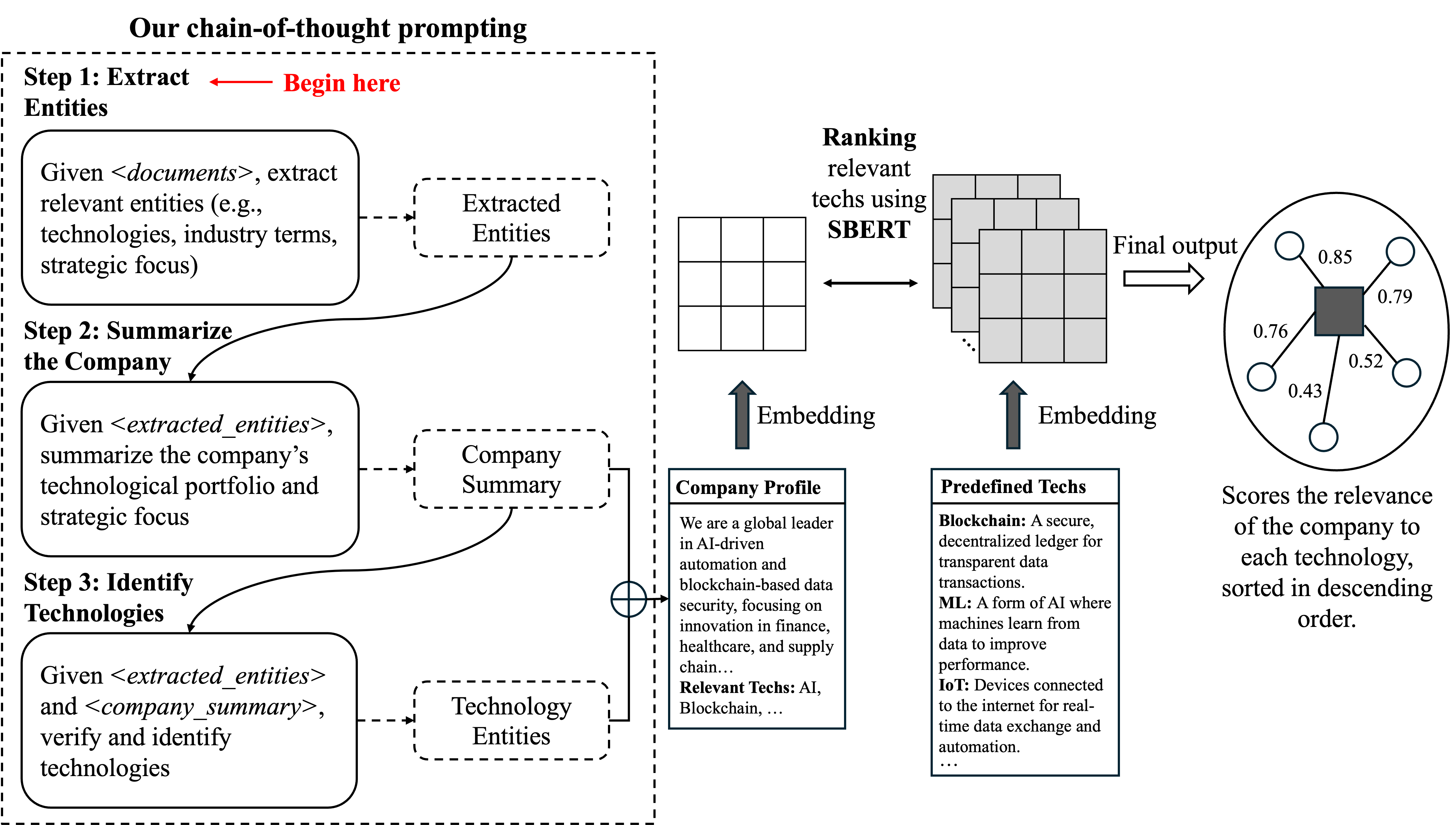
技术框架:STARS框架包含以下主要模块:1) 数据收集与预处理:收集企业相关的非结构化文本数据,如新闻报道、博客文章、专利文档等,并进行清洗和格式化。2) 实体提取:利用LLM和Chain-of-Thought prompting从文本中提取技术实体。3) 语义嵌入:使用Sentence-BERT将提取的技术实体和企业信息嵌入到语义空间中。4) 语义排序:根据技术实体与企业信息的语义相似度,对技术实体进行排序,评估其重要性。5) 技术图谱构建:将提取的技术实体及其重要性信息整合到企业技术图谱中。
关键创新:STARS的关键创新在于将LLM的语义理解能力与Sentence-BERT的语义排序能力相结合,从而实现更精准的技术实体提取和排序。与传统的关键词搜索方法相比,STARS能够捕捉到更广泛的技术信息,并根据技术在企业运营中的重要性进行排序,从而提供更具价值的技术图谱。
关键设计:论文中使用了Chain-of-Thought prompting来提高LLM的实体提取能力。具体来说,通过引导LLM逐步推理,可以更准确地识别文本中的技术实体。此外,论文还使用了Sentence-BERT来计算技术实体与企业信息之间的语义相似度,从而评估技术的重要性。具体的参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
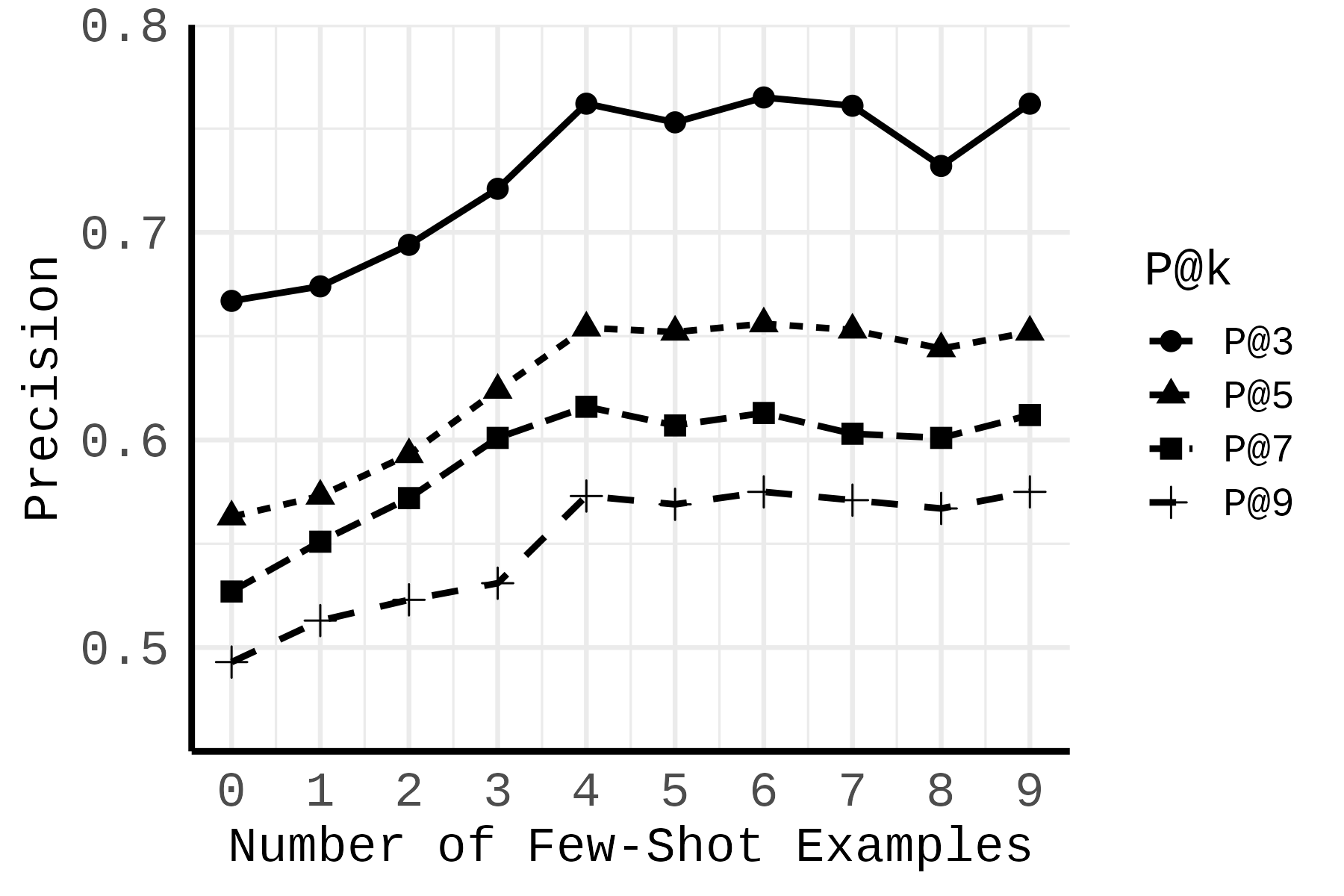
实验结果表明,STARS在技术检索准确率方面显著优于传统的关键词搜索方法。具体性能数据和对比基线在摘要中未给出,属于未知信息。但结论明确指出STARS能够提供一种通用且高性能的跨行业技术图谱构建解决方案。
🎯 应用场景
该研究成果可应用于市场分析、竞争情报、投资决策等领域。企业可以利用STARS了解竞争对手的技术栈,发现潜在的合作机会,并制定更有效的技术战略。投资者可以利用STARS评估企业的技术实力,从而做出更明智的投资决策。该研究还有助于推动技术创新和产业升级。
📄 摘要(原文)
In today's fast-evolving business landscape, having insight into the technology stacks that organizations use is crucial for forging partnerships, uncovering market openings, and informing strategic choices. However, conventional technology mapping, which typically hinges on keyword searches, struggles with the sheer scale and variety of data available, often failing to capture nascent technologies. To overcome these hurdles, we present STARS (Semantic Technology and Retrieval System), a novel framework that harnesses Large Language Models (LLMs) and Sentence-BERT to pinpoint relevant technologies within unstructured content, build comprehensive company profiles, and rank each firm's technologies according to their operational importance. By integrating entity extraction with Chain-of-Thought prompting and employing semantic ranking, STARS provides a precise method for mapping corporate technology portfolios. Experimental results show that STARS markedly boosts retrieval accuracy, offering a versatile and high-performance solution for cross-industry technology mapping.