Divergence-Augmented Policy Optimization
作者: Qing Wang, Yingru Li, Jiechao Xiong, Tong Zhang
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-01-25
备注: 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada
💡 一句话要点
提出DAPO方法,通过散度增强策略优化,提升离线数据复用下的强化学习性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 策略优化 离策略学习 Bregman散度 数据复用
📋 核心要点
- 传统策略梯度方法在离策略数据复用时存在收敛过早和不稳定的问题,限制了强化学习的效率。
- 论文提出DAPO方法,通过在策略更新中引入行为策略和当前策略之间的Bregman散度来约束策略更新幅度。
- 在Atari游戏上的实验表明,DAPO在数据稀缺场景下,显著优于其他先进的深度强化学习算法。
📝 摘要(中文)
在深度强化学习中,策略优化方法需要处理函数逼近和离策略数据复用等问题。标准的策略梯度方法在处理离策略数据时表现不佳,容易导致过早收敛和不稳定。本文提出了一种在复用离策略数据时稳定策略优化的方法。其核心思想是在行为策略(生成数据的策略)和当前策略之间引入Bregman散度,以确保使用离策略数据时策略更新的小幅和安全。Bregman散度计算的是两个策略的状态分布之间的差异,而不仅仅是动作概率,从而形成了一种散度增强的公式。在Atari游戏上的实验结果表明,在数据稀缺、需要复用离策略数据的场景下,我们的方法能够比其他最先进的深度强化学习算法取得更好的性能。
🔬 方法详解
问题定义:深度强化学习中的策略优化方法,尤其是在离策略学习场景下,面临着数据效率低下的问题。直接使用离策略数据进行策略更新容易导致策略不稳定,甚至崩溃,因为行为策略和目标策略的差异可能很大。现有的策略梯度方法难以有效利用这些离策略数据,导致学习效率低下。
核心思路:论文的核心思路是通过引入一个正则化项来约束策略的更新幅度,确保策略更新的“安全性”。具体来说,就是在策略优化过程中,加入一个Bregman散度项,用于衡量当前策略和生成离策略数据的行为策略之间的差异。通过最小化这个散度,可以防止策略更新过于激进,从而提高学习的稳定性和效率。
技术框架:DAPO方法的核心在于修改了策略优化的目标函数。原始的策略优化目标是最大化累积奖励。DAPO在此基础上增加了一个正则化项,即行为策略和当前策略之间的Bregman散度。整体流程如下: 1. 使用行为策略收集离策略数据。 2. 利用这些数据更新当前策略,更新的目标函数包含累积奖励和Bregman散度项。 3. 重复以上步骤,直到策略收敛。
关键创新:DAPO的关键创新在于使用状态分布的Bregman散度,而不是仅仅使用动作概率的散度。传统的策略约束方法通常只关注动作概率的差异,而忽略了状态分布的差异。DAPO认为,状态分布的差异更能反映策略的整体行为差异,因此使用状态分布的Bregman散度能够更有效地约束策略更新。
关键设计:Bregman散度的具体形式需要根据具体问题进行选择。论文中可能使用了某种特定的Bregman散度,例如平方欧几里得距离或KL散度。此外,正则化系数的选择也很重要,需要通过实验进行调整,以平衡奖励最大化和策略稳定性之间的关系。具体的网络结构和优化算法(例如Adam)的选择也会影响最终的性能。
🖼️ 关键图片
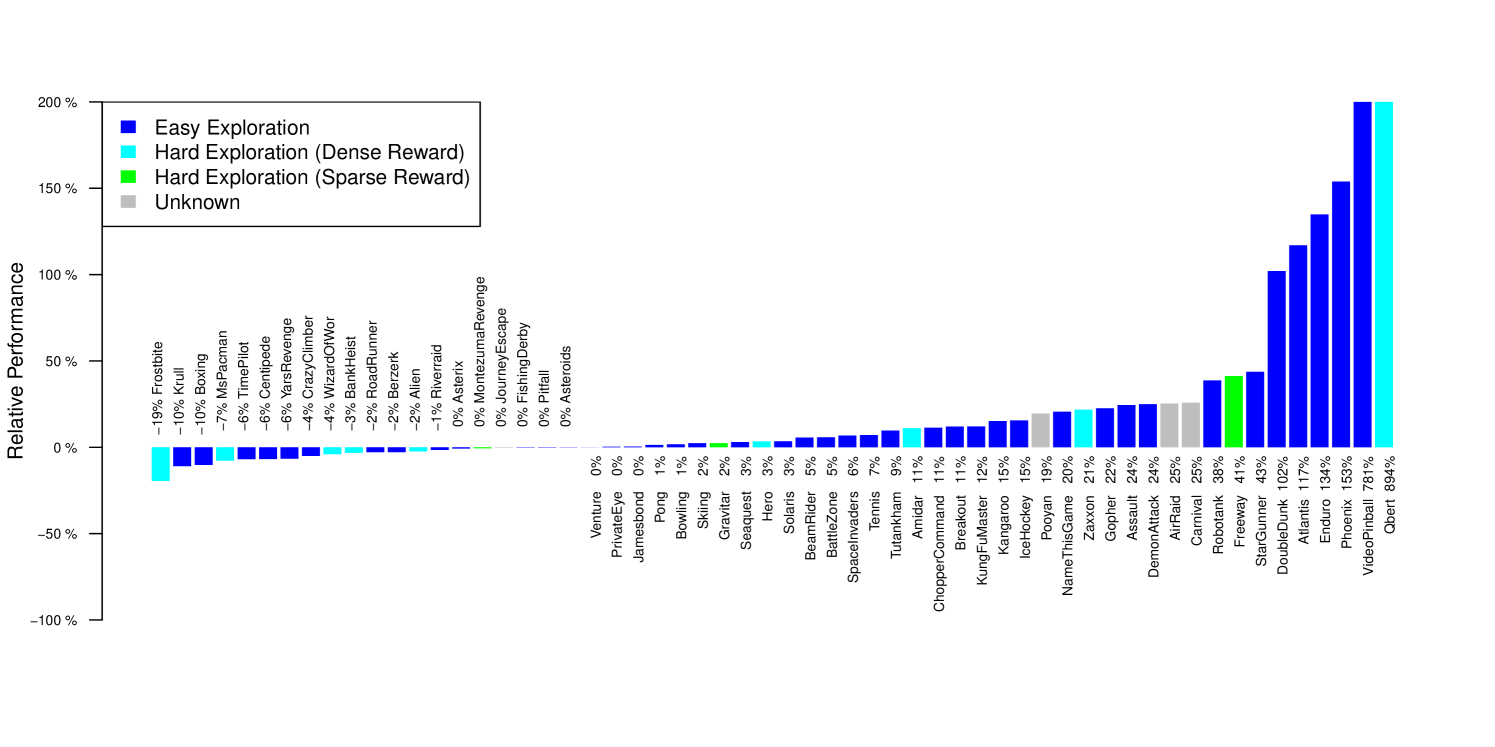

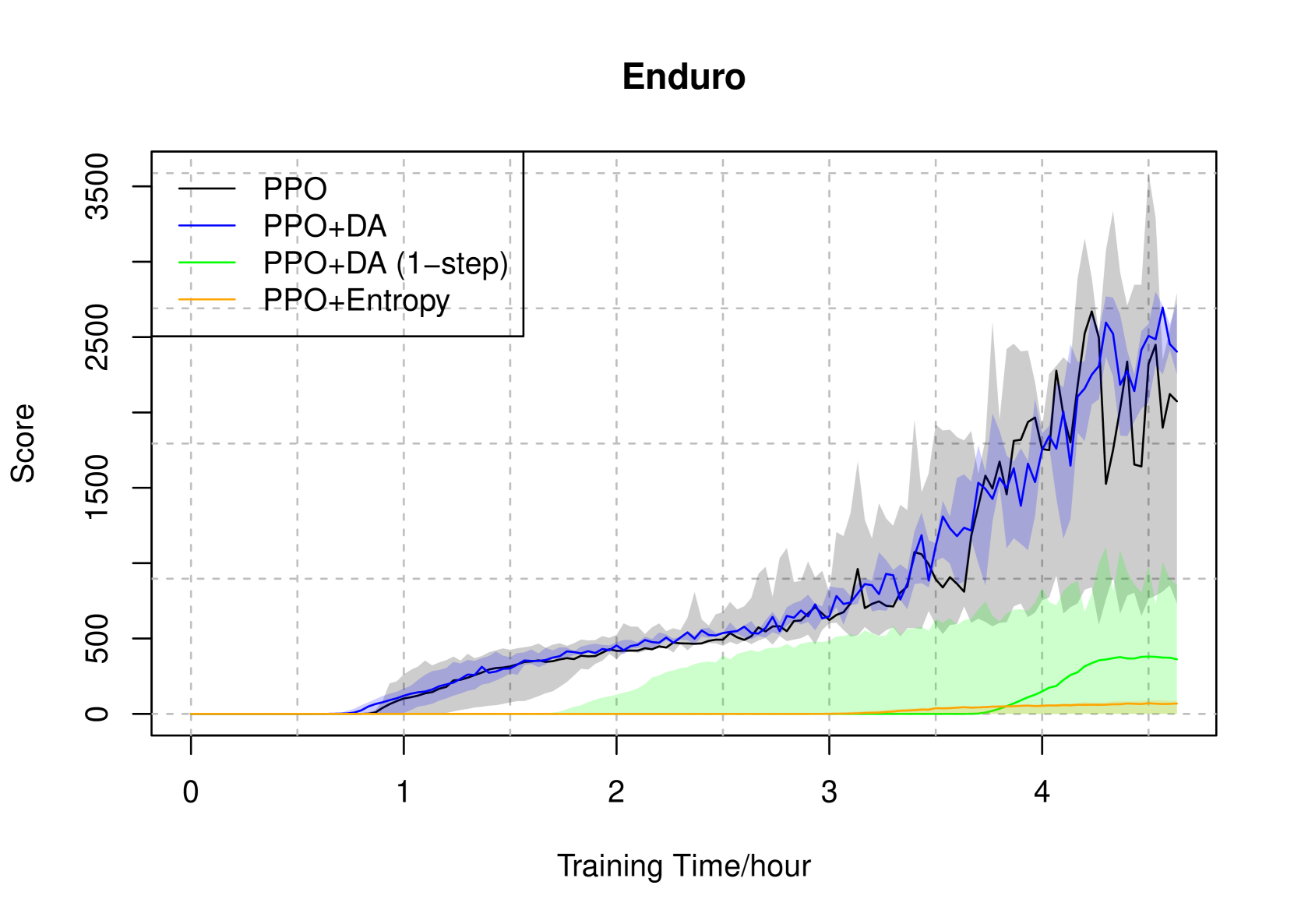
📊 实验亮点
论文在Atari游戏上进行了实验,结果表明DAPO方法在数据稀缺的场景下显著优于其他先进的深度强化学习算法。具体的性能提升幅度未知,但摘要中明确指出DAPO能够取得更好的性能,表明其在离策略数据复用方面具有明显的优势。
🎯 应用场景
DAPO方法在数据收集成本高昂或环境探索受限的强化学习场景中具有广泛的应用前景,例如机器人控制、自动驾驶、推荐系统等。通过有效利用离策略数据,DAPO可以显著提高学习效率,降低训练成本,加速智能体的开发和部署。该方法也有助于解决强化学习中的探索-利用平衡问题,提高智能体的鲁棒性和泛化能力。
📄 摘要(原文)
In deep reinforcement learning, policy optimization methods need to deal with issues such as function approximation and the reuse of off-policy data. Standard policy gradient methods do not handle off-policy data well, leading to premature convergence and instability. This paper introduces a method to stabilize policy optimization when off-policy data are reused. The idea is to include a Bregman divergence between the behavior policy that generates the data and the current policy to ensure small and safe policy updates with off-policy data. The Bregman divergence is calculated between the state distributions of two policies, instead of only on the action probabilities, leading to a divergence augmentation formulation. Empirical experiments on Atari games show that in the data-scarce scenario where the reuse of off-policy data becomes necessary, our method can achieve better performance than other state-of-the-art deep reinforcement learning algorithms.