E-Gen: Leveraging E-Graphs to Improve Continuous Representations of Symbolic Expressions
作者: Hongbo Zheng, Suyuan Wang, Neeraj Gangwar, Nickvash Kani
分类: cs.LG, cs.CL, cs.SC
发布日期: 2025-01-24 (更新: 2025-03-09)
🔗 代码/项目: GITHUB
💡 一句话要点
E-Gen:利用E-图改进符号表达式的连续表示
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学表达式嵌入 E-图 数据增强 对比学习 数学语言处理
📋 核心要点
- 现有数学表达式嵌入方法受限于训练数据的规模和多样性,难以充分捕捉表达式的语义信息。
- E-Gen提出了一种基于e-图的数据集生成方案,能够合成大规模且多样化的数学表达式数据集,从而克服数据限制。
- 实验表明,使用E-Gen生成的数据集训练的嵌入模型在数学语言处理任务上优于现有方法,甚至超越了大型语言模型。
📝 摘要(中文)
向量表示在自然语言处理(NLP)领域取得了显著进展,之前的研究主要集中在使用数学等价公式的数学表达式嵌入技术。然而,这些方法受到训练数据规模和多样性的限制。为了解决这些限制,我们提出了E-Gen,一种新颖的基于e-图的数据集生成方案,可以合成大规模和多样化的数学表达式数据集,在规模和算子多样性方面超越了以往的方法。我们利用该数据集,采用两种策略训练嵌入模型:(1)生成数学上等价的表达式,(2)使用对比学习显式地将等价表达式分组。我们在同分布和异分布的数学语言处理任务上评估这些嵌入,并将它们与先前的方法进行比较。最后,我们证明了我们基于嵌入的方法在多个任务上优于最先进的大型语言模型(LLM),突出了优化数学数据模态嵌入方法的必要性。源代码和数据集可在https://github.com/MLPgroup/E-Gen获取。
🔬 方法详解
问题定义:现有数学表达式嵌入方法面临数据规模和多样性不足的挑战。这些方法难以覆盖所有可能的数学表达式及其等价形式,导致模型泛化能力受限,尤其是在处理分布外(out-of-distribution)数据时表现不佳。此外,现有方法可能无法有效区分数学上等价但形式不同的表达式。
核心思路:E-Gen的核心思路是利用e-图(equality graphs)来高效生成大量数学上等价的表达式。通过在e-图上应用不同的规则进行重写,可以系统地生成各种形式的等价表达式,从而显著扩充训练数据集的规模和多样性。此外,论文还采用对比学习,显式地将等价表达式分组,从而增强模型对数学等价性的感知。
技术框架:E-Gen的整体框架包括以下几个主要阶段:1) 使用e-图生成大规模数学表达式数据集;2) 使用生成的数据集训练嵌入模型,包括基于等价表达式生成和对比学习两种策略;3) 在各种数学语言处理任务上评估嵌入模型的性能。对比学习部分,模型学习将等价的表达式映射到嵌入空间中相近的位置,而非等价的表达式则映射到较远的位置。
关键创新:E-Gen的关键创新在于其基于e-图的数据集生成方案。与以往方法相比,E-Gen能够更高效、更系统地生成大规模且多样化的数学表达式数据集,从而显著提升嵌入模型的性能。此外,对比学习策略的引入,进一步增强了模型对数学等价性的理解。
关键设计:E-Gen使用e-图来表示数学表达式及其等价形式。e-图的节点表示表达式,边表示表达式之间的等价关系。通过在e-图上应用不同的重写规则,可以生成新的等价表达式。对比学习损失函数的设计旨在最小化等价表达式之间的距离,同时最大化非等价表达式之间的距离。具体的损失函数形式未知,需要在论文中查找。
🖼️ 关键图片
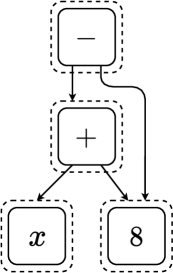
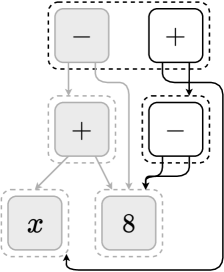
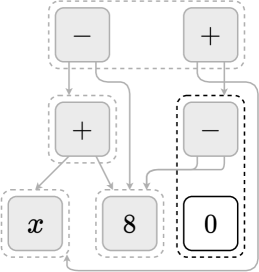
📊 实验亮点
实验结果表明,使用E-Gen生成的数据集训练的嵌入模型在同分布和异分布的数学语言处理任务上均优于现有方法。更重要的是,该方法在某些任务上甚至超越了最先进的大型语言模型,证明了针对数学数据模态优化嵌入方法的有效性。具体的性能提升幅度未知,需要在论文中查找。
🎯 应用场景
E-Gen的研究成果可广泛应用于数学公式识别、数学问题求解、科学文献理解等领域。高质量的数学表达式嵌入能够提升相关任务的性能,例如公式检索、公式相似度计算、以及基于公式的知识推理。此外,该方法还可以应用于其他符号表达式的处理,例如程序代码分析和逻辑推理。
📄 摘要(原文)
Vector representations have been pivotal in advancing natural language processing (NLP), with prior research focusing on embedding techniques for mathematical expressions using mathematically equivalent formulations. While effective, these approaches are constrained by the size and diversity of training data. In this work, we address these limitations by introducing E-Gen, a novel e-graph-based dataset generation scheme that synthesizes large and diverse mathematical expression datasets, surpassing prior methods in size and operator variety. Leveraging this dataset, we train embedding models using two strategies: (1) generating mathematically equivalent expressions, and (2) contrastive learning to explicitly group equivalent expressions. We evaluate these embeddings on both in-distribution and out-of-distribution mathematical language processing tasks, comparing them against prior methods. Finally, we demonstrate that our embedding-based approach outperforms state-of-the-art large language models (LLMs) on several tasks, underscoring the necessity of optimizing embedding methods for the mathematical data modality. The source code and datasets are available at https://github.com/MLPgroup/E-Gen.