Locality-aware Fair Scheduling in LLM Serving
作者: Shiyi Cao, Yichuan Wang, Ziming Mao, Pin-Lun Hsu, Liangsheng Yin, Tian Xia, Dacheng Li, Shu Liu, Yineng Zhang, Yang Zhou, Ying Sheng, Joseph Gonzalez, Ion Stoica
分类: cs.DC, cs.LG
发布日期: 2025-01-24
💡 一句话要点
提出 locality-aware 的公平调度算法,提升LLM Serving的吞吐和公平性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Serving 公平调度 前缀局部性 缓存命中率 分布式系统
📋 核心要点
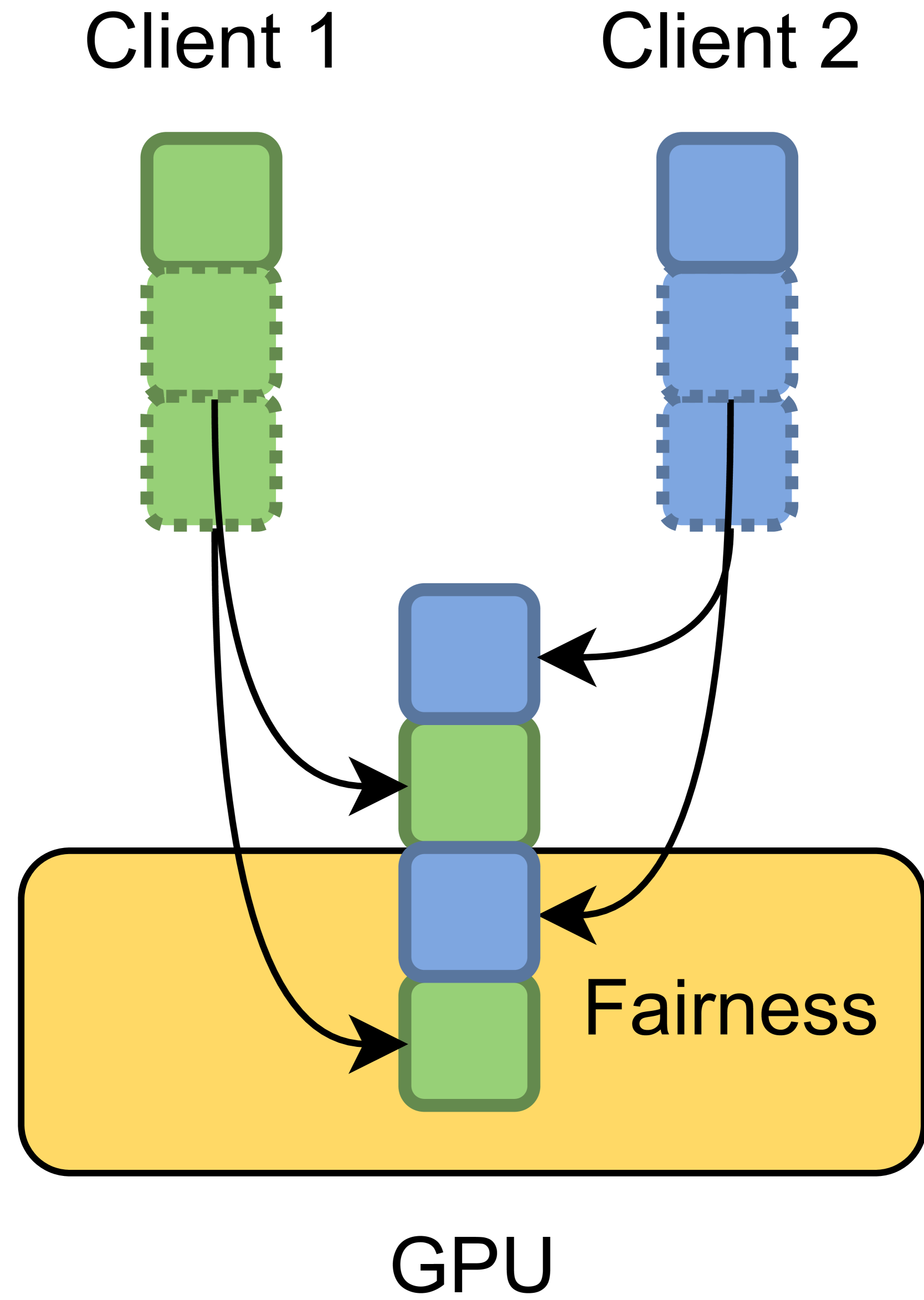
- 现有LLM Serving的公平调度算法忽略了前缀局部性,导致性能下降;而locality-aware算法又缺乏公平性考虑。
- 论文提出Deficit Longest Prefix Match (DLPM)算法,在保证公平性的同时,兼顾前缀局部性,提升吞吐量。
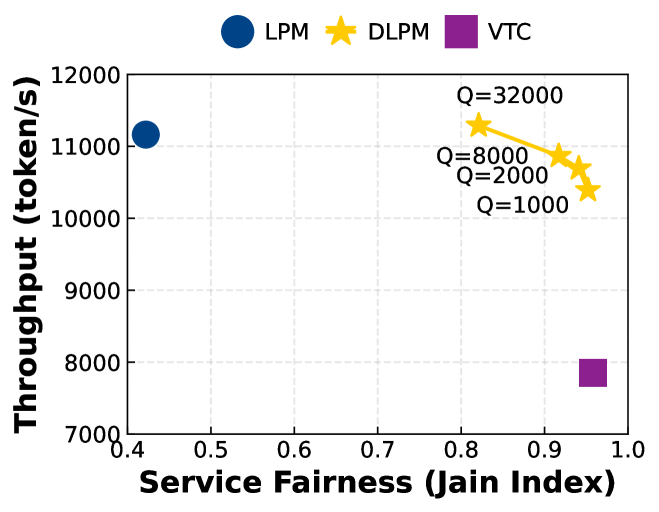
- 实验表明,DLPM和D$^2$LPM在公平性、吞吐量和延迟方面均优于现有算法,吞吐量最高提升2.87倍。
📝 摘要(中文)
大型语言模型(LLM)推理工作负载在各种现代AI应用中占据主导地位,从多轮对话到文档分析。平衡公平性和效率对于管理具有不同前缀模式的各种客户端工作负载至关重要。然而,现有的LLM Serving公平调度算法,如虚拟令牌计数器(VTC),未能考虑前缀局部性,因此性能较差。另一方面,现有LLM Serving框架中的locality-aware调度算法倾向于最大化前缀缓存命中率,而不考虑客户端之间的公平共享。本文介绍了第一个locality-aware公平调度算法,即Deficit Longest Prefix Match(DLPM),它可以在保证公平性的前提下保持高度的前缀局部性。我们还介绍了一种新算法,Double Deficit LPM(D$^2$LPM),它扩展了DLPM用于分布式设置,可以在公平性、局部性和负载平衡之间找到平衡点。大量的评估表明,DLPM和D$^2$LPM在确保公平性的同时,保持了较高的吞吐量(比VTC高2.87倍)和较低的单客户端延迟(比最先进的分布式LLM Serving系统低7.18倍)。
🔬 方法详解
问题定义:现有LLM Serving的公平调度算法,如VTC,没有考虑前缀局部性,导致缓存命中率低,性能差。而现有的locality-aware调度算法,如LPM,只关注缓存命中率,忽略了不同客户端之间的公平性,导致某些客户端的请求被过度延迟。因此,如何在保证公平性的前提下,提高LLM Serving的吞吐量和降低延迟是一个关键问题。
核心思路:论文的核心思路是将公平调度和locality-aware调度结合起来。通过引入Deficit的概念,优先调度那些由于前缀匹配失败而导致“亏欠”的请求,从而保证公平性。同时,优先选择具有最长前缀匹配的请求,以提高缓存命中率,提升吞吐量。
技术框架:论文提出了两种算法:DLPM和D$^2$LPM。DLPM适用于单机环境,D$^2$LPM是DLPM的扩展,适用于分布式环境。两种算法都包含请求队列、前缀缓存管理和调度器三个主要模块。请求队列负责接收和存储客户端的请求。前缀缓存管理负责维护和更新前缀缓存。调度器根据DLPM或D$^2$LPM算法选择下一个要执行的请求。在分布式环境中,D$^2$LPM还包括负载均衡模块,负责将请求分配到不同的服务器上。
关键创新:论文的关键创新在于提出了Deficit Longest Prefix Match (DLPM)算法,该算法是第一个locality-aware的公平调度算法。DLPM通过引入Deficit的概念,将公平调度和locality-aware调度结合起来,从而在保证公平性的前提下,提高了LLM Serving的吞吐量和降低了延迟。D$^2$LPM进一步将DLPM扩展到分布式环境,并考虑了负载均衡问题。
关键设计:DLPM算法的关键设计在于Deficit的计算和更新。每个客户端都有一个Deficit值,表示该客户端由于前缀匹配失败而导致的“亏欠”。调度器优先选择Deficit值最高的客户端的请求。当一个请求被调度执行后,其所属客户端的Deficit值会相应减少。同时,调度器会根据前缀匹配的长度来更新所有客户端的Deficit值,从而保证公平性。D$^2$LPM算法的关键设计在于如何将请求分配到不同的服务器上,以实现负载均衡。D$^2$LPM采用了一种基于令牌的负载均衡策略,每个服务器都有一定数量的令牌,客户端需要消耗令牌才能将请求发送到该服务器。令牌的数量会根据服务器的负载情况进行动态调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DLPM算法在单机环境下,吞吐量比VTC算法高2.87倍。D$^2$LPM算法在分布式环境下,单客户端延迟比最先进的分布式LLM Serving系统低7.18倍。这些结果表明,DLPM和D$^2$LPM算法在保证公平性的前提下,显著提高了LLM Serving的性能。
🎯 应用场景
该研究成果可应用于各种需要大规模LLM推理服务的场景,例如在线客服、智能助手、文档分析、代码生成等。通过提高LLM Serving的吞吐量和降低延迟,可以提升用户体验,并降低运营成本。未来,该研究可以进一步扩展到支持更多类型的LLM模型和更复杂的应用场景。
📄 摘要(原文)
Large language model (LLM) inference workload dominates a wide variety of modern AI applications, ranging from multi-turn conversation to document analysis. Balancing fairness and efficiency is critical for managing diverse client workloads with varying prefix patterns. Unfortunately, existing fair scheduling algorithms for LLM serving, such as Virtual Token Counter (VTC), fail to take prefix locality into consideration and thus suffer from poor performance. On the other hand, locality-aware scheduling algorithms in existing LLM serving frameworks tend to maximize the prefix cache hit rate without considering fair sharing among clients. This paper introduces the first locality-aware fair scheduling algorithm, Deficit Longest Prefix Match (DLPM), which can maintain a high degree of prefix locality with a fairness guarantee. We also introduce a novel algorithm, Double Deficit LPM (D$^2$LPM), extending DLPM for the distributed setup that can find a balance point among fairness, locality, and load-balancing. Our extensive evaluation demonstrates the superior performance of DLPM and D$^2$LPM in ensuring fairness while maintaining high throughput (up to 2.87$\times$ higher than VTC) and low per-client (up to 7.18$\times$ lower than state-of-the-art distributed LLM serving system) latency.