Utilizing Evolution Strategies to Train Transformers in Reinforcement Learning
作者: Matyáš Lorenc, Roman Neruda
分类: cs.LG, cs.NE
发布日期: 2025-01-23 (更新: 2025-07-30)
💡 一句话要点
利用进化策略训练Transformer强化学习智能体,解决复杂环境下的策略优化问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 进化策略 强化学习 Transformer 决策Transformer 黑盒优化
📋 核心要点
- 传统强化学习方法在训练复杂模型时面临挑战,例如样本效率低和对超参数敏感。
- 本文提出使用进化策略直接优化Transformer策略网络,无需梯度信息,更易于并行化。
- 实验表明,进化策略能够有效训练Decision Transformer,在MuJoCo和Atari游戏中取得良好性能。
📝 摘要(中文)
本文探讨了进化策略在强化学习中训练基于Transformer架构的智能体的能力。我们使用OpenAI的高度并行化进化策略,在MuJoCo Humanoid locomotion环境和Atari游戏环境中训练Decision Transformer,测试了这种黑盒优化技术训练相对较大和复杂模型的能力(与之前文献中测试的模型相比)。实验结果表明,所研究的进化策略通常能够取得良好的效果,并成功生成高性能的智能体,展示了进化算法在处理此类复杂模型训练方面的能力。
🔬 方法详解
问题定义:论文旨在解决在复杂强化学习环境中,如何高效训练基于Transformer的策略网络的问题。传统基于梯度的方法在训练大型Transformer模型时,计算成本高昂,且对超参数调整敏感。此外,探索-利用的平衡也是一个挑战。
核心思路:论文的核心思路是利用进化策略(Evolution Strategies, ES)作为一种黑盒优化方法,直接优化Transformer策略网络的参数。ES通过维护一个种群,并根据适应度(例如,智能体在环境中的累积奖励)选择和变异种群中的个体,从而逐步优化策略。这种方法不需要计算梯度,因此更易于并行化,并且对超参数的鲁棒性更强。
技术框架:整体框架包括以下几个主要步骤:1) 初始化一个包含多个Transformer策略网络(个体)的种群。2) 每个个体在环境中进行一定数量的episode交互,并计算其适应度。3) 根据适应度对种群进行选择,选择适应度高的个体。4) 对选择出的个体进行变异,生成新的个体,形成新的种群。5) 重复步骤2-4,直到达到预定的训练迭代次数或性能指标。论文使用了OpenAI的进化策略实现,该实现具有高度并行化的特点。
关键创新:最重要的技术创新点在于将进化策略应用于训练基于Transformer的策略网络。以往的研究较少探索使用进化策略直接优化如此复杂的模型。与传统的基于梯度的方法相比,进化策略不需要计算梯度,因此可以避免梯度消失或爆炸等问题,并且更易于并行化。
关键设计:论文使用了Decision Transformer作为策略网络,这是一种基于Transformer的序列建模方法,可以将强化学习问题转化为序列预测问题。具体来说,Decision Transformer将状态、动作和奖励作为序列输入,并预测下一个动作。论文没有详细说明具体的参数设置,但提到了使用了OpenAI的进化策略实现,这意味着使用了高斯变异和适应度排名选择等技术。
🖼️ 关键图片

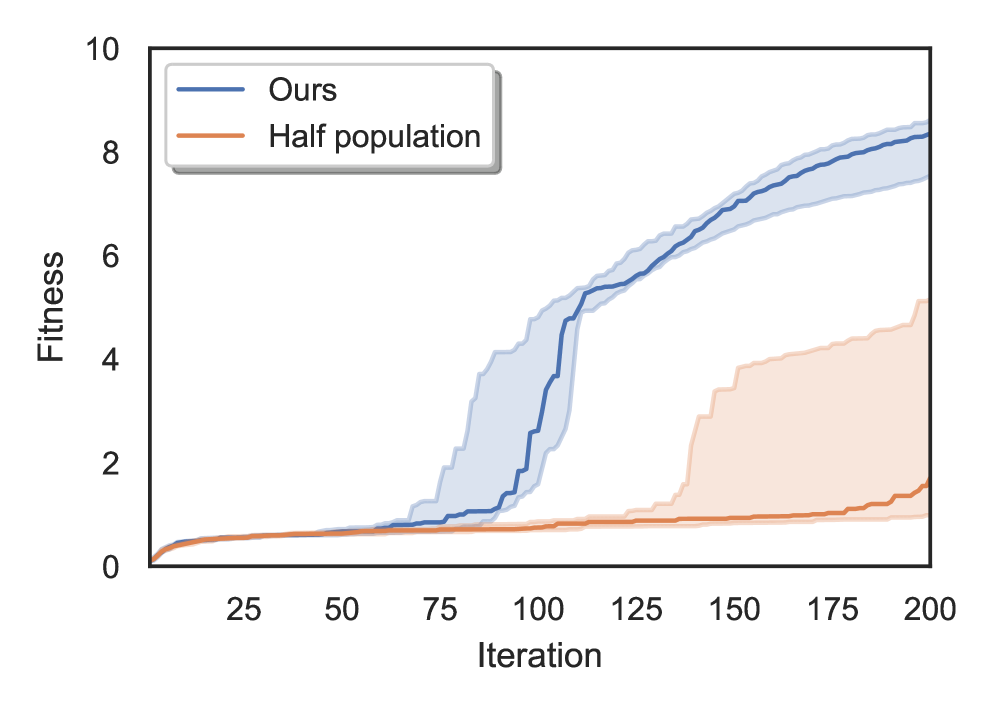
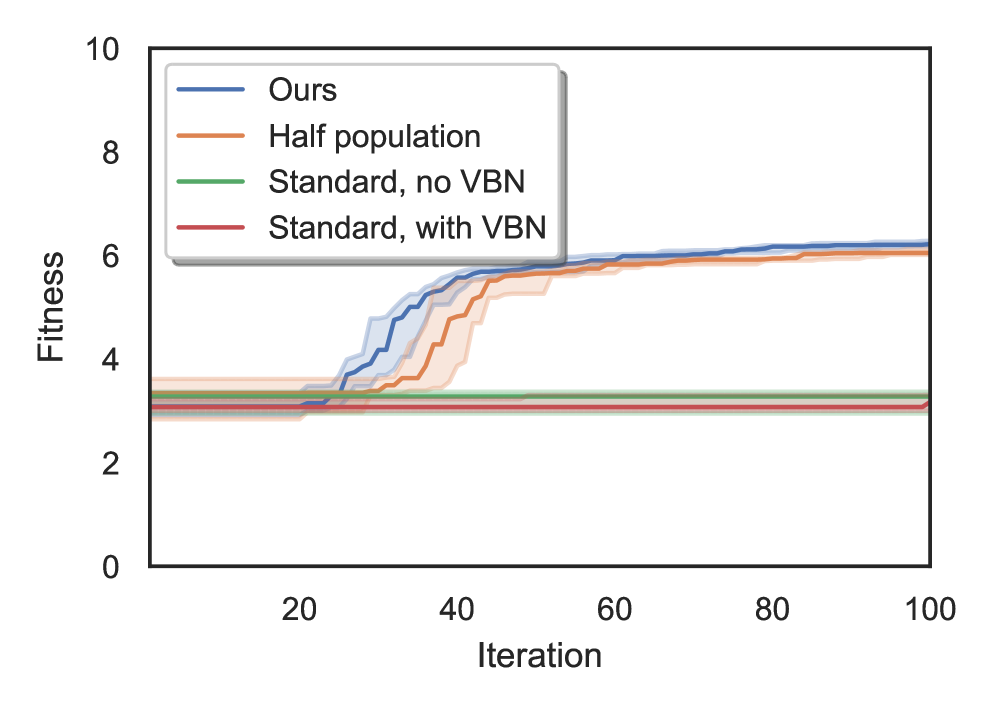
📊 实验亮点
实验结果表明,进化策略能够成功训练Decision Transformer,在MuJoCo Humanoid locomotion环境和Atari游戏中取得良好的性能。虽然论文没有给出具体的性能数据和对比基线,但强调了进化策略在训练复杂模型方面的有效性,并指出其能够生成高性能的智能体。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。进化策略在训练复杂模型方面的潜力,为解决高维、非线性强化学习问题提供了一种新的思路。未来,可以将该方法扩展到更复杂的环境和任务中,例如多智能体协作、元学习等。
📄 摘要(原文)
We explore the capability of evolution strategies to train an agent with a policy based on a transformer architecture in a reinforcement learning setting. We performed experiments using OpenAI's highly parallelizable evolution strategy to train Decision Transformer in the MuJoCo Humanoid locomotion environment and in the environment of Atari games, testing the ability of this black-box optimization technique to train even such relatively large and complicated models (compared to those previously tested in the literature). The examined evolution strategy proved to be, in general, capable of achieving strong results and managed to produce high-performing agents, showcasing evolution's ability to tackle the training of even such complex models.