Large Vision-Language Models for Knowledge-Grounded Data Annotation of Memes
作者: Shiling Deng, Serge Belongie, Peter Ebert Christensen
分类: cs.LG
发布日期: 2025-01-23
备注: 18 pages, 5 figures, 13 tables, GitHub repository: https://github.com/Seefreem/meme_text_retrieval_p1
💡 一句话要点
提出ClassicMemes-50-templates数据集与知识驱动的Meme标注框架,并改进CLIP模型用于Meme-文本检索。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: Meme分析 视觉-语言模型 知识驱动标注 跨模态检索 CLIP模型 数据集构建 社交媒体分析
📋 核心要点
- 现有Meme研究侧重情感分类等,忽略了深层理解和Meme-文本检索,缺乏大规模数据集支持。
- 利用大型视觉-语言模型构建知识驱动的自动标注流程,生成高质量的图像和Meme标题。
- 提出Meme-文本检索CLIP模型(mtrCLIP),通过跨模态嵌入显著提升Meme检索性能。
📝 摘要(中文)
Meme已成为一种强大的交流形式,它整合了视觉和文本元素来传达幽默、讽刺和文化信息。现有的研究主要集中在情感分类、Meme生成、传播、解释、比喻语言和社会语言学等方面,但往往忽略了更深层次的Meme理解和Meme-文本检索。为了解决这些差距,本研究引入了ClassicMemes-50-templates (CM50),这是一个大规模数据集,包含超过33,000个Meme,围绕50个流行的Meme模板构建。我们还提出了一个自动化的知识驱动的标注流程,利用大型视觉-语言模型来生成高质量的图像标题、Meme标题和文学手法标签,克服了手动标注的劳动密集型需求。此外,我们提出了一个Meme-文本检索CLIP模型(mtrCLIP),它利用跨模态嵌入来增强Meme分析,显著提高了检索性能。我们的贡献包括:(1)一个用于大规模Meme研究的新数据集,(2)一个可扩展的Meme标注框架,以及(3)一个用于Meme-文本检索的微调CLIP模型,所有这些都旨在促进对Meme的大规模理解和分析。
🔬 方法详解
问题定义:现有Meme研究主要集中在情感分类、生成等方面,缺乏对Meme深层语义理解和Meme-文本检索的关注。手动标注Meme数据成本高昂,阻碍了大规模Meme研究的开展。
核心思路:利用大型视觉-语言模型强大的知识表示和生成能力,构建自动化的知识驱动的Meme标注流程,降低标注成本,提高标注质量。通过跨模态学习,提升Meme和文本之间的关联性,从而改善Meme-文本检索性能。
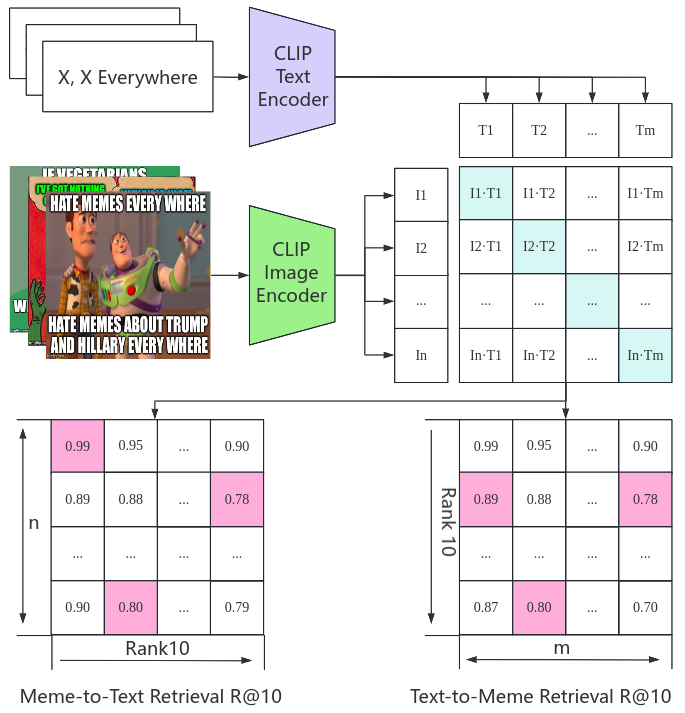
技术框架:该研究主要包含三个部分:1) 构建大规模Meme数据集ClassicMemes-50-templates (CM50);2) 开发基于大型视觉-语言模型的自动标注框架,包括图像标题生成、Meme标题生成和文学手法标签生成;3) 提出Meme-文本检索CLIP模型(mtrCLIP),用于提升Meme-文本检索性能。
关键创新:1) 提出了一个大规模的Meme数据集CM50,为Meme研究提供了数据基础。2) 利用大型视觉-语言模型构建了自动化的知识驱动的Meme标注框架,显著降低了标注成本。3) 提出了mtrCLIP模型,通过跨模态学习,提升了Meme-文本检索性能。
关键设计:在自动标注框架中,使用了预训练的视觉-语言模型(具体模型未知)进行微调,以生成高质量的图像和Meme标题。在mtrCLIP模型中,采用了跨模态对比学习的方法,优化Meme和文本的嵌入表示,损失函数和网络结构等细节未知。
🖼️ 关键图片


📊 实验亮点
研究者构建了包含超过33,000个Meme的大规模数据集CM50。提出的mtrCLIP模型在Meme-文本检索任务上取得了显著的性能提升,具体提升幅度未知,但表明了跨模态嵌入在Meme分析中的有效性。自动标注框架降低了人工标注成本,提高了标注效率。
🎯 应用场景
该研究成果可应用于社交媒体内容分析、舆情监控、网络安全等领域。通过对Meme的深入理解,可以更好地识别和过滤不良信息,提升网络内容质量。此外,该研究还可以促进跨文化交流和理解,帮助人们更好地理解不同文化背景下的Meme。
📄 摘要(原文)
Memes have emerged as a powerful form of communication, integrating visual and textual elements to convey humor, satire, and cultural messages. Existing research has focused primarily on aspects such as emotion classification, meme generation, propagation, interpretation, figurative language, and sociolinguistics, but has often overlooked deeper meme comprehension and meme-text retrieval. To address these gaps, this study introduces ClassicMemes-50-templates (CM50), a large-scale dataset consisting of over 33,000 memes, centered around 50 popular meme templates. We also present an automated knowledge-grounded annotation pipeline leveraging large vision-language models to produce high-quality image captions, meme captions, and literary device labels overcoming the labor intensive demands of manual annotation. Additionally, we propose a meme-text retrieval CLIP model (mtrCLIP) that utilizes cross-modal embedding to enhance meme analysis, significantly improving retrieval performance. Our contributions include:(1) a novel dataset for large-scale meme study, (2) a scalable meme annotation framework, and (3) a fine-tuned CLIP for meme-text retrieval, all aimed at advancing the understanding and analysis of memes at scale.