HumorReject: Decoupling LLM Safety from Refusal Prefix via A Little Humor
作者: Zihui Wu, Haichang Gao, Jiacheng Luo, Zhaoxiang Liu
分类: cs.LG, cs.CR
发布日期: 2025-01-23 (更新: 2025-11-10)
🔗 代码/项目: GITHUB
💡 一句话要点
HumorReject:通过幽默而非拒绝前缀提升大语言模型的安全性
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型安全 幽默回应 前缀注入攻击 数据驱动方法 鲁棒性 用户体验 拒绝策略
📋 核心要点
- 现有大语言模型依赖拒绝前缀保证安全性,易受前缀注入攻击,且存在过度防御问题。
- HumorReject通过数据驱动的方式,使用幽默作为间接拒绝策略,解耦安全性和拒绝前缀。
- 实验表明,HumorReject能有效解决过度防御问题,并对多种攻击表现出更强的鲁棒性。
📝 摘要(中文)
大型语言模型(LLMs)通常依赖显式的拒绝前缀来实现安全性,这使得它们容易受到前缀注入攻击。我们引入了HumorReject,这是一种新颖的数据驱动方法,通过使用幽默作为一种间接的拒绝策略,将LLM的安全性与拒绝前缀解耦,从而重新构想LLM的安全性。HumorReject不是直接拒绝有害指令,而是以符合语境的幽默回应,从而自然地化解潜在的危险请求。我们的方法有效地解决了常见的“过度防御”问题,同时展示了对各种攻击向量的卓越鲁棒性。我们的研究结果表明,在实现有效的LLM安全性方面,改进训练数据设计与对齐算法本身同样重要。代码和数据集可在https://github.com/wooozihui/HumorReject获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在安全性方面对显式拒绝前缀的过度依赖问题。现有方法容易受到前缀注入攻击,攻击者可以通过操纵输入前缀绕过安全机制。此外,LLMs常常出现“过度防御”现象,即对无害的请求也进行拒绝,影响用户体验。
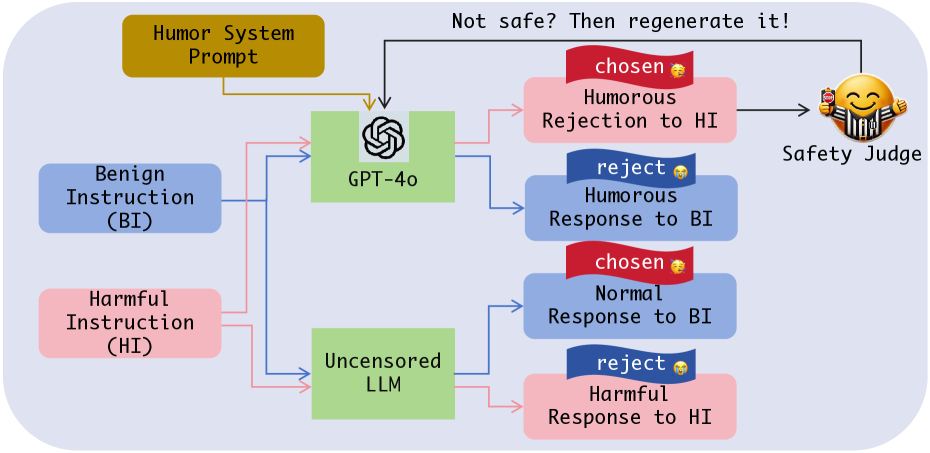
核心思路:HumorReject的核心思路是利用幽默作为一种间接的拒绝策略,将LLM的安全性与拒绝前缀解耦。通过训练LLM以幽默的方式回应潜在的有害请求,而不是直接拒绝,从而避免了对拒绝前缀的依赖,提高了模型的鲁棒性和用户体验。这种方法旨在使模型在保证安全性的同时,更加自然和人性化。
技术框架:HumorReject的技术框架主要包括以下几个阶段:1) 数据收集与构建:构建包含有害指令和对应幽默回应的数据集。2) 模型训练:使用构建的数据集对LLM进行微调,使其学会以幽默的方式回应有害请求。3) 评估:评估模型在安全性、鲁棒性和用户体验方面的表现。具体流程是,给定一个用户输入,模型首先判断其是否潜在有害。如果判断为有害,则生成一个幽默的回应;否则,模型正常回应用户请求。
关键创新:HumorReject最重要的技术创新点在于其将幽默引入LLM安全领域,并将其作为一种间接的拒绝策略。与传统的依赖拒绝前缀的方法不同,HumorReject通过幽默回应来化解潜在的危险请求,从而避免了对拒绝前缀的依赖,提高了模型的鲁棒性和用户体验。这种方法不仅能够有效防御前缀注入攻击,还能够减少“过度防御”现象。
关键设计:HumorReject的关键设计在于数据集的构建和模型微调。数据集需要包含各种类型的有害指令和对应的高质量幽默回应。在模型微调方面,可以使用标准的监督学习方法,例如交叉熵损失函数。此外,还可以使用一些正则化技术,例如dropout和权重衰减,以防止过拟合。具体的参数设置需要根据实际情况进行调整。
🖼️ 关键图片

📊 实验亮点
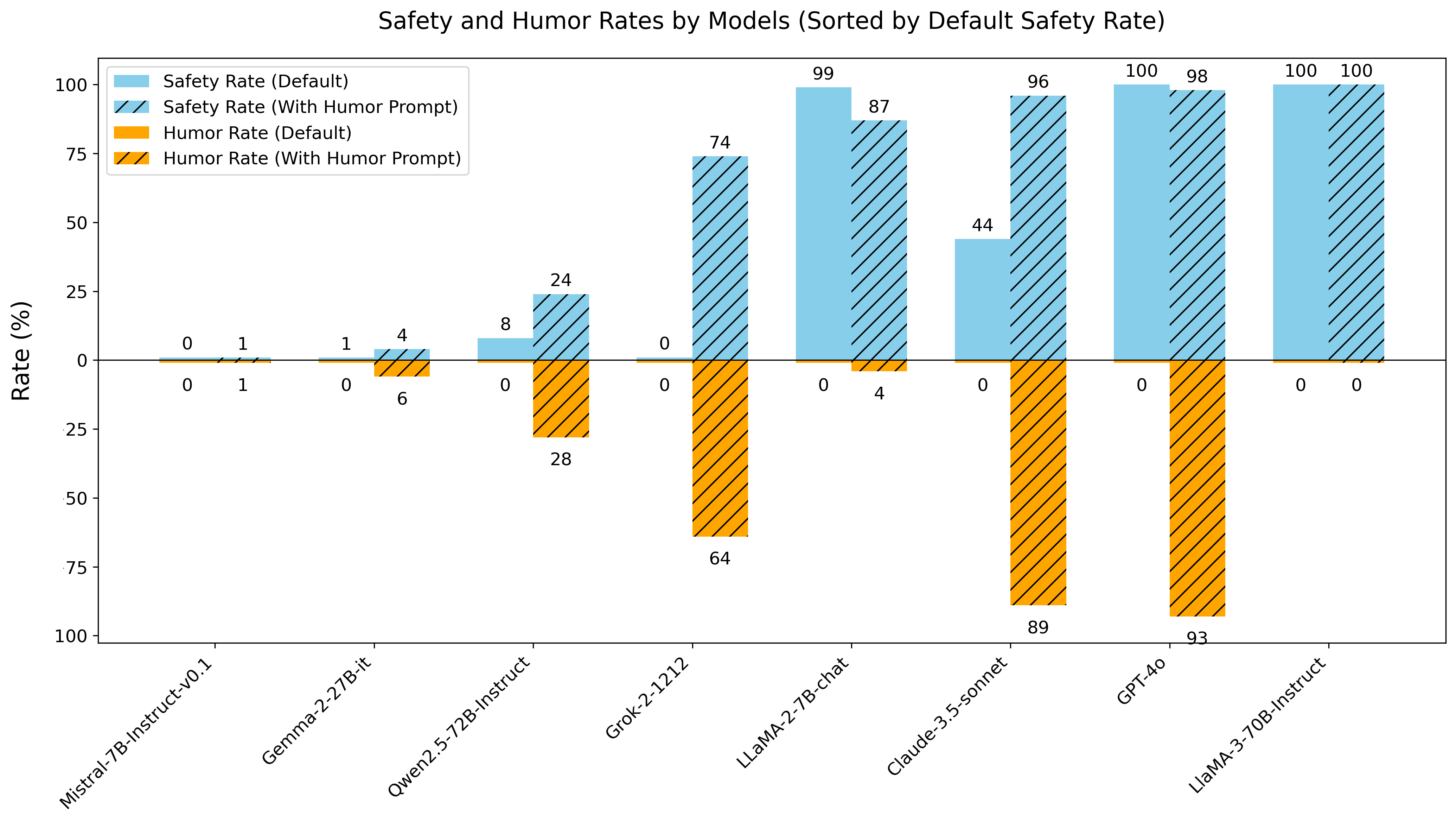
实验结果表明,HumorReject在防御前缀注入攻击方面表现出卓越的鲁棒性,显著降低了攻击成功率。同时,HumorReject有效解决了“过度防御”问题,在保证安全性的前提下,提高了用户体验。具体性能数据未知,但论文强调了数据驱动方法在提升LLM安全性方面的潜力。
🎯 应用场景
HumorReject具有广泛的应用前景,可用于提升聊天机器人、智能助手等应用的安全性与用户体验。通过幽默化解潜在的危险请求,不仅能有效防御攻击,还能使交互过程更加自然流畅。未来,该技术有望应用于内容审核、舆情分析等领域,构建更安全、友好的AI系统。
📄 摘要(原文)
Large Language Models (LLMs) commonly rely on explicit refusal prefixes for safety, making them vulnerable to prefix injection attacks. We introduce HumorReject, a novel data-driven approach that reimagines LLM safety by decoupling it from refusal prefixes through humor as an indirect refusal strategy. Rather than explicitly rejecting harmful instructions, HumorReject responds with contextually appropriate humor that naturally defuses potentially dangerous requests. Our approach effectively addresses common "over-defense" issues while demonstrating superior robustness against various attack vectors. Our findings suggest that improvements in training data design can be as important as the alignment algorithm itself in achieving effective LLM safety. The code and dataset are available at https://github.com/wooozihui/HumorReject.