M3PT: A Transformer for Multimodal, Multi-Party Social Signal Prediction with Person-aware Blockwise Attention
作者: Yiming Tang, Abrar Anwar, Jesse Thomason
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-01-23 (更新: 2025-02-03)
🔗 代码/项目: GITHUB
💡 一句话要点
提出M3PT:用于多模态多人社交信号预测的Transformer模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 社交信号预测 Transformer 分块注意力 人机交互
📋 核心要点
- 现有方法为多人交互中的社交信号预测构建特定任务模型,泛化性差。
- M3PT采用因果Transformer架构,通过模态和时间分块注意力掩码处理多模态和多参与者数据。
- 在HHCD数据集上的实验表明,M3PT利用多模态信息能有效提升咬合时机和说话状态的预测精度。
📝 摘要(中文)
理解多人对话中的社交信号对于人机交互和人工智能至关重要。这些信号包括身体姿势、头部姿势、语音以及特定情境下的活动,如用餐时的取食和咀嚼。以往的多人交互研究倾向于为预测社交信号构建特定任务的模型。本文提出了M3PT,一种因果Transformer架构,具有模态和时间分块注意力掩码,可以同时处理多个参与者的多个社交线索及其时间交互。在Human-Human Commensality Dataset (HHCD)上训练和评估M3PT,结果表明使用多种模态可以提高咬合时机和说话状态的预测性能。
🔬 方法详解
问题定义:论文旨在解决多人场景下多模态社交信号预测问题。现有方法通常针对特定任务构建模型,缺乏通用性,难以同时处理多种模态和多个参与者之间的复杂交互关系。
核心思路:论文的核心思路是利用Transformer架构强大的序列建模能力,通过引入模态和时间分块注意力掩码,使模型能够有效地处理多模态输入,并捕捉多个参与者之间的时间依赖关系。这种设计允许模型同时学习不同模态和不同参与者的社交信号,从而实现更准确的预测。
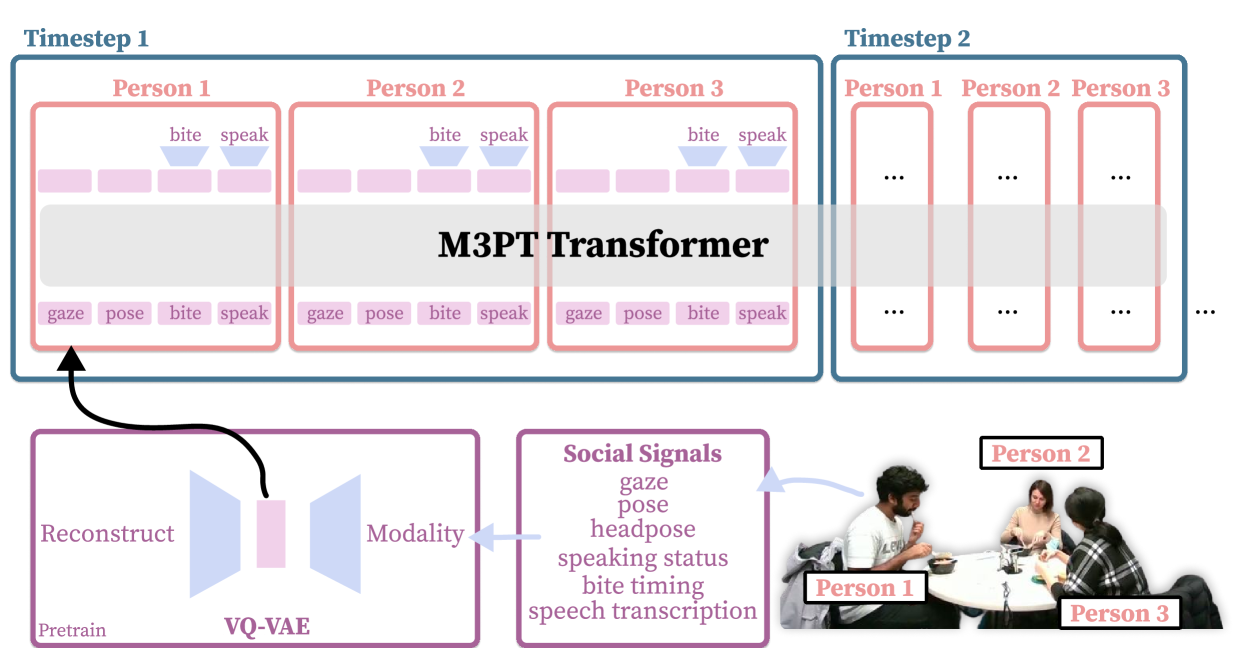
技术框架:M3PT是一个因果Transformer模型,其整体架构包括以下几个主要模块:1) 输入嵌入层:将不同模态的输入数据(如身体姿势、头部姿势、语音等)嵌入到统一的向量空间中。2) 分块注意力层:使用模态和时间分块注意力掩码,限制模型只能关注过去的信息,并控制不同模态和参与者之间的信息交互。3) Transformer编码器层:堆叠多个Transformer编码器层,进一步提取输入序列的特征。4) 输出预测层:根据提取的特征,预测目标社交信号(如咬合时机、说话状态等)。
关键创新:M3PT的关键创新在于提出了模态和时间分块注意力掩码。这种掩码机制允许模型在处理多模态输入时,有选择地关注不同模态的信息,并控制不同参与者之间的时间依赖关系。与传统的注意力机制相比,分块注意力掩码可以更好地捕捉社交互动中的复杂关系,并提高模型的预测精度。
关键设计:M3PT的关键设计包括:1) 使用因果掩码确保模型只能利用过去的信息进行预测。2) 设计模态分块注意力掩码,允许模型关注特定模态的信息,例如,在预测咬合时机时,模型可以更关注身体姿势和头部姿势等视觉信息。3) 设计时间分块注意力掩码,限制模型只能关注特定时间窗口内的信息,从而捕捉时间依赖关系。4) 损失函数采用交叉熵损失函数,用于训练模型预测目标社交信号。
🖼️ 关键图片
📊 实验亮点
实验结果表明,M3PT在HHCD数据集上取得了显著的性能提升。通过融合多种模态的信息,M3PT在咬合时机和说话状态预测任务上均优于基线模型。具体而言,多模态输入相比单模态输入,在咬合时机预测上F1值提升了约5%,在说话状态预测上准确率提升了约3%。这些结果验证了M3PT的有效性。
🎯 应用场景
M3PT可应用于人机交互、社交机器人、智能会议系统等领域。例如,在人机交互中,机器人可以利用M3PT预测人类的社交信号,从而做出更自然、更符合人类习惯的反应。在智能会议系统中,M3PT可以用于分析参与者的行为,提高会议效率和参与度。该研究有助于提升机器对人类社交行为的理解能力,促进更自然的人机协作。
📄 摘要(原文)
Understanding social signals in multi-party conversations is important for human-robot interaction and artificial social intelligence. Social signals include body pose, head pose, speech, and context-specific activities like acquiring and taking bites of food when dining. Past work in multi-party interaction tends to build task-specific models for predicting social signals. In this work, we address the challenge of predicting multimodal social signals in multi-party settings in a single model. We introduce M3PT, a causal transformer architecture with modality and temporal blockwise attention masking to simultaneously process multiple social cues across multiple participants and their temporal interactions. We train and evaluate M3PT on the Human-Human Commensality Dataset (HHCD), and demonstrate that using multiple modalities improves bite timing and speaking status prediction. Source code: https://github.com/AbrarAnwar/masked-social-signals/.