An Offline Multi-Agent Reinforcement Learning Framework for Radio Resource Management
作者: Eslam Eldeeb, Hirley Alves
分类: cs.MA, cs.LG
发布日期: 2025-01-22
💡 一句话要点
提出离线多智能体强化学习框架,用于无线资源管理,提升用户速率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 多智能体强化学习 无线资源管理 集中式训练分散式执行 无线通信
📋 核心要点
- 在线多智能体强化学习存在安全隐患、数据收集成本高、训练时间长等问题,限制了其在无线资源管理中的应用。
- 论文提出一种离线多智能体强化学习框架,通过离线数据学习优化接入点的调度策略,提升用户速率。
- 实验结果表明,该框架优于传统方法,在总速率和尾速率的加权组合上提升超过15%,CTDE训练范式表现出良好的平衡性。
📝 摘要(中文)
本文提出了一种用于无线资源管理(RRM)的离线多智能体强化学习(MARL)算法,旨在解决在线MARL的安全问题、昂贵的数据收集、漫长的训练周期以及与环境在线交互导致的高信令开销等关键限制。该方法侧重于优化多接入点(AP)的调度策略,以联合最大化用户设备(UE)的总速率和尾速率。论文评估了三种训练范式:集中式、独立式以及集中式训练分散式执行(CTDE)。仿真结果表明,所提出的离线MARL框架优于传统的基线方法,在总速率和尾速率的加权组合方面实现了超过15%的改进。此外,CTDE框架在降低集中式方法的计算复杂度的同时,解决了独立训练的效率低下问题。这些结果突显了离线MARL在为动态无线网络中的资源管理提供可扩展、稳健和高效的解决方案方面的潜力。
🔬 方法详解
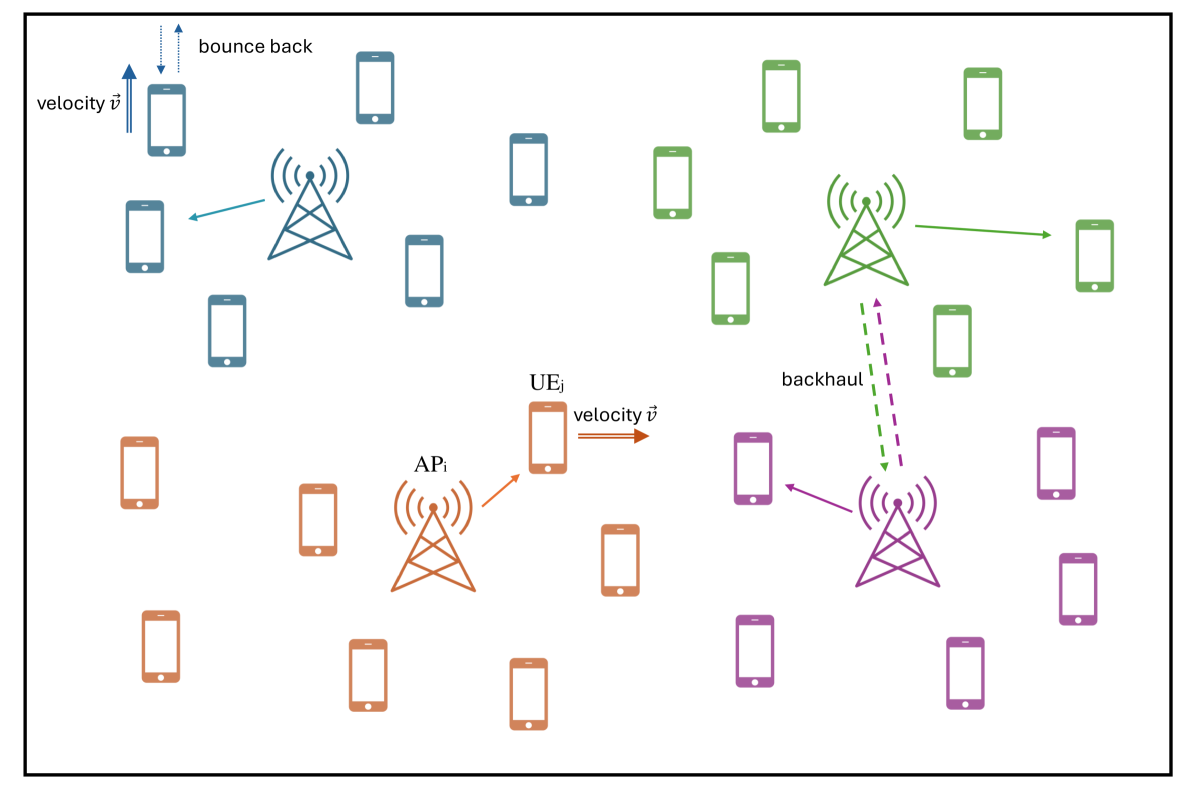
问题定义:论文旨在解决无线资源管理中,如何高效地为多个接入点(AP)分配无线资源,以最大化用户设备(UE)的总速率和尾速率的问题。现有在线多智能体强化学习方法在实际部署中面临安全风险、数据采集成本高昂、训练时间过长以及信令开销过大等问题,限制了其应用。
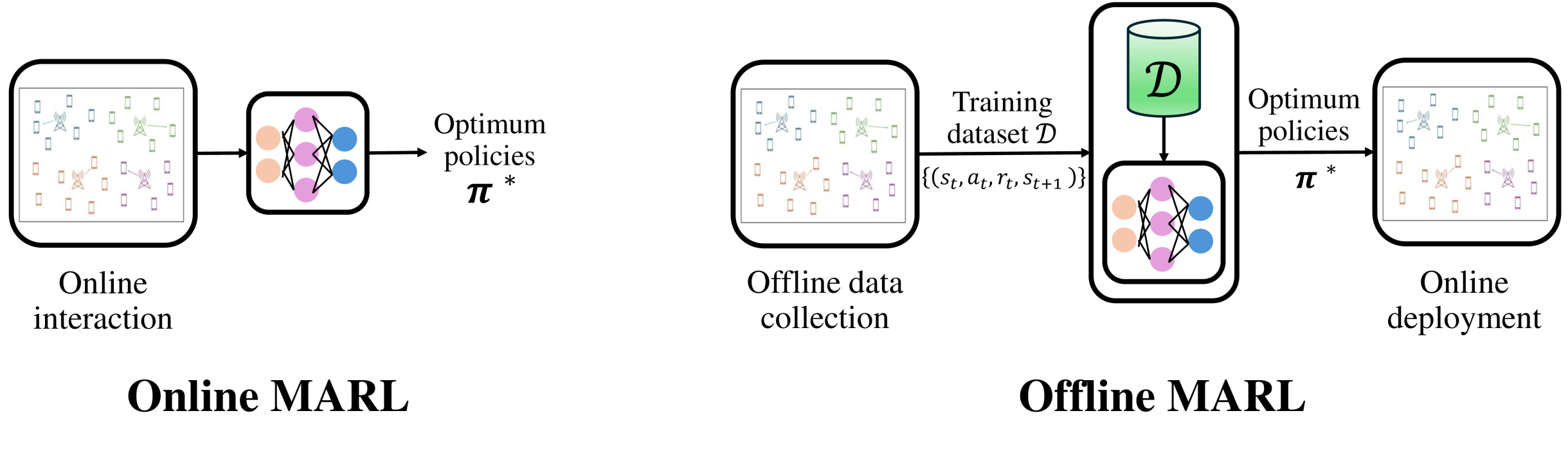
核心思路:论文的核心思路是利用离线数据进行多智能体强化学习,避免与真实环境的直接交互,从而解决在线学习的安全性和效率问题。通过预先收集的无线网络数据,训练智能体学习最优的资源分配策略,并在实际部署中直接应用。
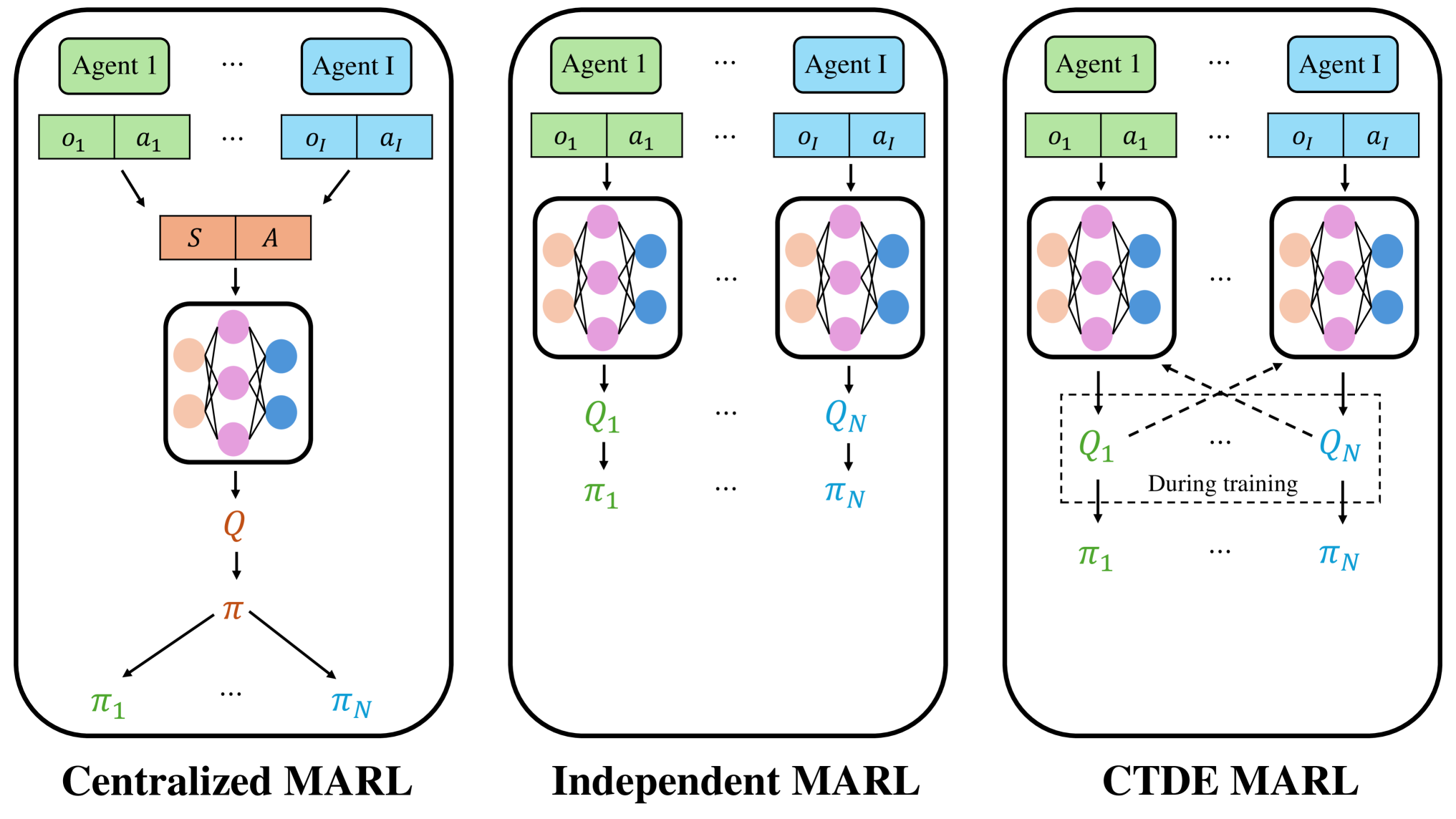
技术框架:该框架主要包含离线数据收集、多智能体强化学习训练和分散式执行三个阶段。首先,收集无线网络环境的历史数据,例如信道状态信息、用户需求等。然后,利用这些离线数据,采用集中式或独立式训练方法训练多个智能体,每个智能体负责一个接入点的资源调度。最后,在实际部署中,每个接入点根据训练好的策略独立地进行资源分配。
关键创新:该论文的关键创新在于将离线多智能体强化学习应用于无线资源管理。与传统的在线学习方法相比,离线学习避免了与真实环境的交互,降低了风险和成本。此外,论文还比较了集中式、独立式和CTDE三种训练范式,为实际应用提供了选择。
关键设计:论文中,智能体的目标是最大化用户设备的总速率和尾速率的加权组合。具体而言,可以使用深度Q网络(DQN)或Actor-Critic等算法进行训练。对于CTDE范式,可以使用MADDPG等算法,在训练阶段利用全局信息,而在执行阶段仅依赖局部观测。损失函数的设计需要考虑速率的公平性和效率,例如可以使用比例公平性准则。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的离线MARL框架在总速率和尾速率的加权组合方面,相比传统基线方法实现了超过15%的性能提升。此外,集中式训练分散式执行(CTDE)框架在计算复杂度和性能之间取得了良好的平衡,为实际部署提供了可行的解决方案。
🎯 应用场景
该研究成果可应用于各种无线通信场景,例如蜂窝网络、Wi-Fi网络和物联网等。通过离线学习优化资源分配策略,可以显著提升网络性能,改善用户体验,并降低运营成本。未来,该方法有望应用于更复杂的无线网络环境,例如异构网络和动态频谱接入等。
📄 摘要(原文)
Offline multi-agent reinforcement learning (MARL) addresses key limitations of online MARL, such as safety concerns, expensive data collection, extended training intervals, and high signaling overhead caused by online interactions with the environment. In this work, we propose an offline MARL algorithm for radio resource management (RRM), focusing on optimizing scheduling policies for multiple access points (APs) to jointly maximize the sum and tail rates of user equipment (UEs). We evaluate three training paradigms: centralized, independent, and centralized training with decentralized execution (CTDE). Our simulation results demonstrate that the proposed offline MARL framework outperforms conventional baseline approaches, achieving over a 15\% improvement in a weighted combination of sum and tail rates. Additionally, the CTDE framework strikes an effective balance, reducing the computational complexity of centralized methods while addressing the inefficiencies of independent training. These results underscore the potential of offline MARL to deliver scalable, robust, and efficient solutions for resource management in dynamic wireless networks.