GANQ: GPU-Adaptive Non-Uniform Quantization for Large Language Models
作者: Pengxiang Zhao, Xiaoming Yuan
分类: cs.LG, cs.AI, math.OC
发布日期: 2025-01-22 (更新: 2025-06-09)
💡 一句话要点
提出GANQ以解决大语言模型的量化与效率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 非均匀量化 GPU优化 推理效率 深度学习
📋 核心要点
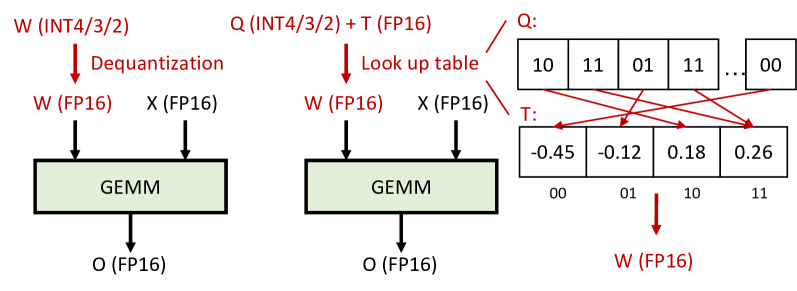
- 现有方法在处理大语言模型时,缺乏对混合精度矩阵乘法的支持,导致去量化效率低下。
- 本文提出的GANQ框架通过GPU自适应优化算法实现分层后训练的非均匀量化,显著减少量化误差。
- 实验结果显示,GANQ在3比特和4比特量化中,相较于基线模型,困惑度显著降低,推理速度提升达2.57倍。
📝 摘要(中文)
大语言模型(LLMs)在部署时面临显著的资源需求挑战。虽然低比特量化权重可以减少内存使用并提高推理效率,但当前硬件缺乏对混合精度通用矩阵乘法(mpGEMM)的原生支持,导致去量化实现效率低下。此外,均匀量化方法往往无法充分捕捉权重分布,导致性能下降。为此,本文提出了GANQ(GPU自适应非均匀量化),这是一个针对硬件高效查找表基础的mpGEMM的分层后训练非均匀量化框架。GANQ通过利用无训练的GPU自适应优化算法有效减少分层量化误差,从而实现了优越的量化性能。大量实验表明,GANQ在3比特和4比特量化中,相较于FP16基线,能够显著降低困惑度差距,并在单个NVIDIA RTX 4090 GPU上实现高达2.57倍的速度提升,推动了LLM部署中的内存和推理效率。
🔬 方法详解
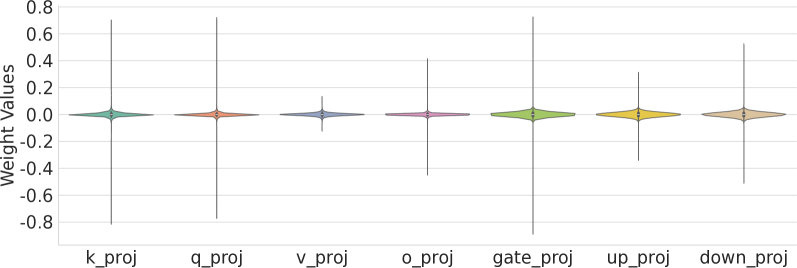
问题定义:本文旨在解决大语言模型在部署过程中由于资源需求高而导致的效率低下问题。现有的均匀量化方法无法有效捕捉权重分布,导致性能下降,同时缺乏对混合精度通用矩阵乘法的支持使得去量化实现效率低下。
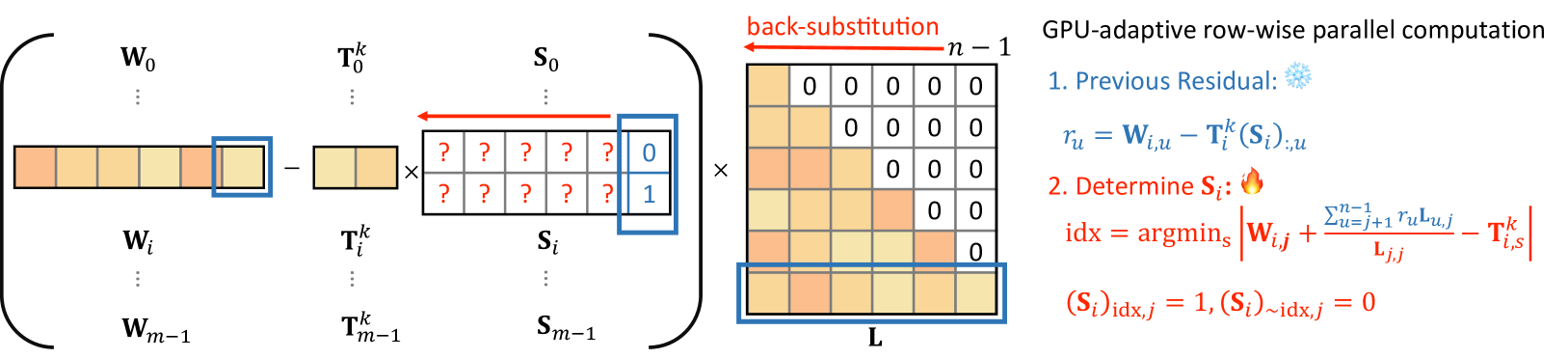
核心思路:GANQ框架通过引入GPU自适应优化算法,进行分层后训练的非均匀量化,旨在减少量化误差并提高推理效率。该方法不依赖于额外的训练过程,降低了实现复杂性。
技术框架:GANQ的整体架构包括数据预处理、非均匀量化算法和GPU自适应优化模块。首先对模型权重进行分析,然后应用非均匀量化策略,最后通过GPU优化算法调整量化参数以最小化误差。
关键创新:GANQ的主要创新在于其无训练的GPU自适应优化算法,这一设计使得量化过程更加高效,能够动态适应硬件特性,显著提升了量化性能。与传统均匀量化方法相比,GANQ能够更好地捕捉权重分布特征。
关键设计:在GANQ中,关键参数设置包括量化位数(3比特和4比特),损失函数设计为最小化量化误差,并采用查找表结构以提高mpGEMM的效率。
🖼️ 关键图片
📊 实验亮点
GANQ在3比特和4比特量化中,相较于FP16基线,显著降低了困惑度差距,并在NVIDIA RTX 4090 GPU上实现了高达2.57倍的推理速度提升。这些结果表明GANQ在内存和推理效率方面的显著进步,超越了现有的最先进方法。
🎯 应用场景
GANQ的研究成果在大语言模型的部署中具有广泛的应用潜力,尤其是在资源受限的环境中。通过提高量化效率和推理速度,该方法能够支持更大规模的模型在边缘设备上的应用,推动智能助手、自然语言处理等领域的发展。未来,GANQ的技术框架也可扩展至其他深度学习模型的优化与部署。
📄 摘要(原文)
Large Language Models (LLMs) face significant deployment challenges due to their substantial resource requirements. While low-bit quantized weights can reduce memory usage and improve inference efficiency, current hardware lacks native support for mixed-precision General Matrix Multiplication (mpGEMM), resulting in inefficient dequantization-based implementations. Moreover, uniform quantization methods often fail to capture weight distributions adequately, leading to performance degradation. We propose GANQ (GPU-Adaptive Non-Uniform Quantization), a layer-wise post-training non-uniform quantization framework optimized for hardware-efficient lookup table-based mpGEMM. GANQ achieves superior quantization performance by utilizing a training-free, GPU-adaptive optimization algorithm to efficiently reduce layer-wise quantization errors. Extensive experiments demonstrate GANQ's ability to reduce the perplexity gap from the FP16 baseline compared to state-of-the-art methods for both 3-bit and 4-bit quantization. Furthermore, when deployed on a single NVIDIA RTX 4090 GPU, GANQ's quantized models achieve up to 2.57$\times$ speedup over the baseline, advancing memory and inference efficiency in LLM deployment.