Correctness Assessment of Code Generated by Large Language Models Using Internal Representations
作者: Tuan-Dung Bui, Thanh Trong Vu, Thu-Trang Nguyen, Son Nguyen, Hieu Dinh Vo
分类: cs.SE, cs.LG
发布日期: 2025-01-22 (更新: 2025-08-02)
💡 一句话要点
OPENIA:利用LLM内部表征评估代码正确性,提升代码生成质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 正确性评估 内部表征 白盒测试
📋 核心要点
- 现有代码生成评估方法主要依赖黑盒方式,忽略了LLM内部状态所蕴含的丰富信息,限制了评估的准确性和效率。
- OPENIA框架通过分析LLM代码生成过程中的内部表征,挖掘与代码正确性相关的潜在信息,实现更准确的评估。
- 实验结果表明,OPENIA在代码生成正确性评估方面显著优于现有基线模型,尤其在特定仓库场景下提升显著。
📝 摘要(中文)
本文提出OPENIA,一种新颖的白盒框架,旨在利用大型语言模型(LLM)在代码生成过程中的内部表征来评估代码的正确性。现有方法主要依赖黑盒方式,在代码生成后进行评估,无法利用LLM内部状态中蕴含的丰富信息。OPENIA系统地分析了DeepSeek-Coder、CodeLlama和MagicCoder等开源代码LLM在不同代码生成基准测试中的中间状态。实验结果表明,这些内部表征编码了与生成代码正确性高度相关的潜在信息。OPENIA利用白盒方法对代码正确性进行预测,在适应性和鲁棒性方面优于传统的基于分类的方法和零样本方法。实验结果表明,OPENIA始终优于基线模型,在独立代码生成中准确率提升高达2倍,在特定仓库场景中提升高达46%。OPENIA通过释放过程内信号的潜力,为LLM辅助代码生成中更主动、更高效的质量保证机制铺平了道路。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)代码生成评估方法主要采用黑盒方式,即在代码生成完成后,通过测试用例或人工检查来判断代码的正确性。这种方法无法利用LLM在生成代码过程中产生的内部状态信息,例如注意力权重、隐藏层输出等。这些内部状态可能蕴含着关于代码正确性的重要线索,而黑盒方法无法有效利用这些信息。因此,如何利用LLM的内部表征来更准确、更高效地评估代码的正确性是一个亟待解决的问题。
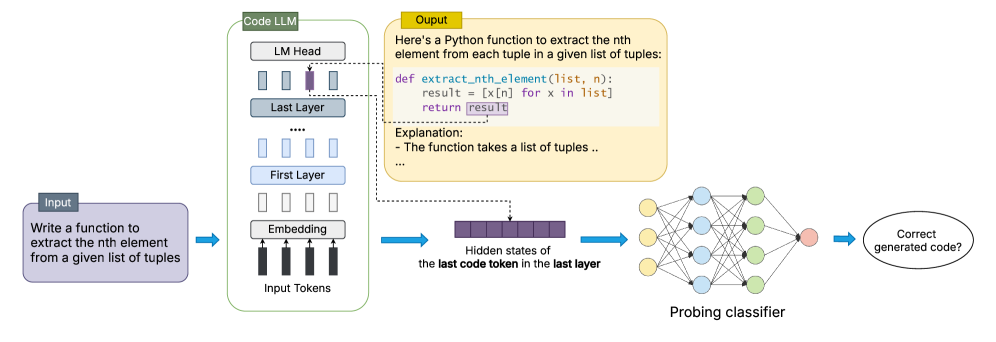
核心思路:OPENIA的核心思路是利用LLM在代码生成过程中的内部表征(internal representations)来预测生成代码的正确性。作者认为,LLM在生成代码的过程中,其内部状态会编码关于代码结构、语义以及潜在错误的信息。通过分析这些内部表征,可以提前预测代码的正确性,从而避免生成错误的代码或及时进行修正。这种方法类似于“白盒测试”,可以深入了解LLM的内部工作机制,从而更好地评估代码的质量。
技术框架:OPENIA框架主要包含以下几个阶段:1) 代码生成:使用选定的LLM(如DeepSeek-Coder、CodeLlama、MagicCoder)生成代码。2) 内部表征提取:在代码生成过程中,提取LLM的内部状态信息,例如注意力权重、隐藏层输出等。3) 特征工程:对提取的内部表征进行特征工程,提取与代码正确性相关的特征。4) 正确性预测:使用机器学习模型(如分类器或回归器)基于提取的特征预测代码的正确性。5) 评估:使用测试用例或人工检查来评估预测的准确性。
关键创新:OPENIA最重要的技术创新点在于其白盒/开放盒(white-box/open-box)方法,即利用LLM的内部表征进行代码正确性评估。与传统的黑盒方法相比,OPENIA可以更深入地了解LLM的内部工作机制,从而更准确地预测代码的正确性。此外,OPENIA还提出了一种系统化的方法来提取和分析LLM的内部表征,并将其用于代码正确性评估。
关键设计:OPENIA的关键设计包括:1) 内部表征的选择:选择哪些内部状态信息作为特征是至关重要的。作者可能尝试了不同的内部表征,并选择了与代码正确性相关性最高的特征。2) 特征工程方法:如何从内部表征中提取有用的特征也是一个关键问题。作者可能使用了各种特征工程技术,例如统计特征、频谱分析等。3) 机器学习模型:选择合适的机器学习模型来预测代码的正确性也很重要。作者可能尝试了不同的分类器或回归器,并选择了性能最佳的模型。具体参数设置、损失函数和网络结构等细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片


📊 实验亮点
OPENIA在代码正确性评估方面取得了显著的实验结果。在独立代码生成场景中,OPENIA的准确率提升高达2倍。在特定仓库场景中,OPENIA的准确率提升高达46%。这些结果表明,OPENIA能够有效地利用LLM的内部表征来预测代码的正确性,并显著优于现有的基线模型。实验结果还表明,OPENIA在精度、召回率和F1-Score等指标上均优于基线模型。
🎯 应用场景
OPENIA的研究成果可应用于AI驱动的软件开发流程中,例如自动化代码审查、代码生成质量控制、以及LLM代码生成能力的持续改进。通过提前预测代码的正确性,可以减少人工审查的工作量,提高开发效率,并降低软件缺陷率。此外,该方法还可以用于评估不同LLM的代码生成能力,为选择合适的LLM提供依据。未来,OPENIA有望成为LLM辅助软件开发的重要组成部分。
📄 摘要(原文)
Ensuring the correctness of code generated by Large Language Models (LLMs) presents a significant challenge in AI-driven software development. Existing approaches predominantly rely on black-box (closed-box) approaches that evaluate correctness post-generation, failing to utilize the rich insights embedded in the LLMs' internal states during code generation. In this paper, we introduce OPENIA, a novel white-box (open-box) framework that leverages these internal representations to assess the correctness of LLM-generated code. OPENIA systematically analyzes the intermediate states of representative open-source LLMs specialized for code, including DeepSeek-Coder, CodeLlama, and MagicCoder, across diverse code generation benchmarks. Our empirical analysis reveals that these internal representations encode latent information, which strongly correlates with the correctness of the generated code. Building on these insights, OPENIA uses a white-box/open-box approach to make informed predictions about code correctness, offering significant advantages in adaptability and robustness over traditional classification-based methods and zero-shot approaches. Experimental results demonstrate that OPENIA consistently outperforms baseline models, achieving higher accuracy, precision, recall, and F1-Scores with up to a 2X improvement in standalone code generation and a 46% enhancement in repository-specific scenarios. By unlocking the potential of in-process signals, OPENIA paves the way for more proactive and efficient quality assurance mechanisms in LLM-assisted code generation.