HierPromptLM: A Pure PLM-based Framework for Representation Learning on Heterogeneous Text-rich Networks
作者: Qiuyu Zhu, Liang Zhang, Qianxiong Xu, Cheng Long
分类: cs.LG
发布日期: 2025-01-22
💡 一句话要点
提出HierPromptLM,一个纯PLM框架,用于异构富文本网络表示学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 异构图神经网络 预训练语言模型 表示学习 Prompt Learning 富文本网络
📋 核心要点
- 现有HTRN表示学习方法分离处理文本和结构信息,忽略了二者间的交互,且PLM和HGNN的对齐困难。
- HierPromptLM提出层级Prompt模块,在统一文本空间整合文本和图结构,并设计HTRN预训练任务。
- 实验表明,HierPromptLM在节点分类和链接预测任务上显著优于现有方法,最高提升达10.84%。
📝 摘要(中文)
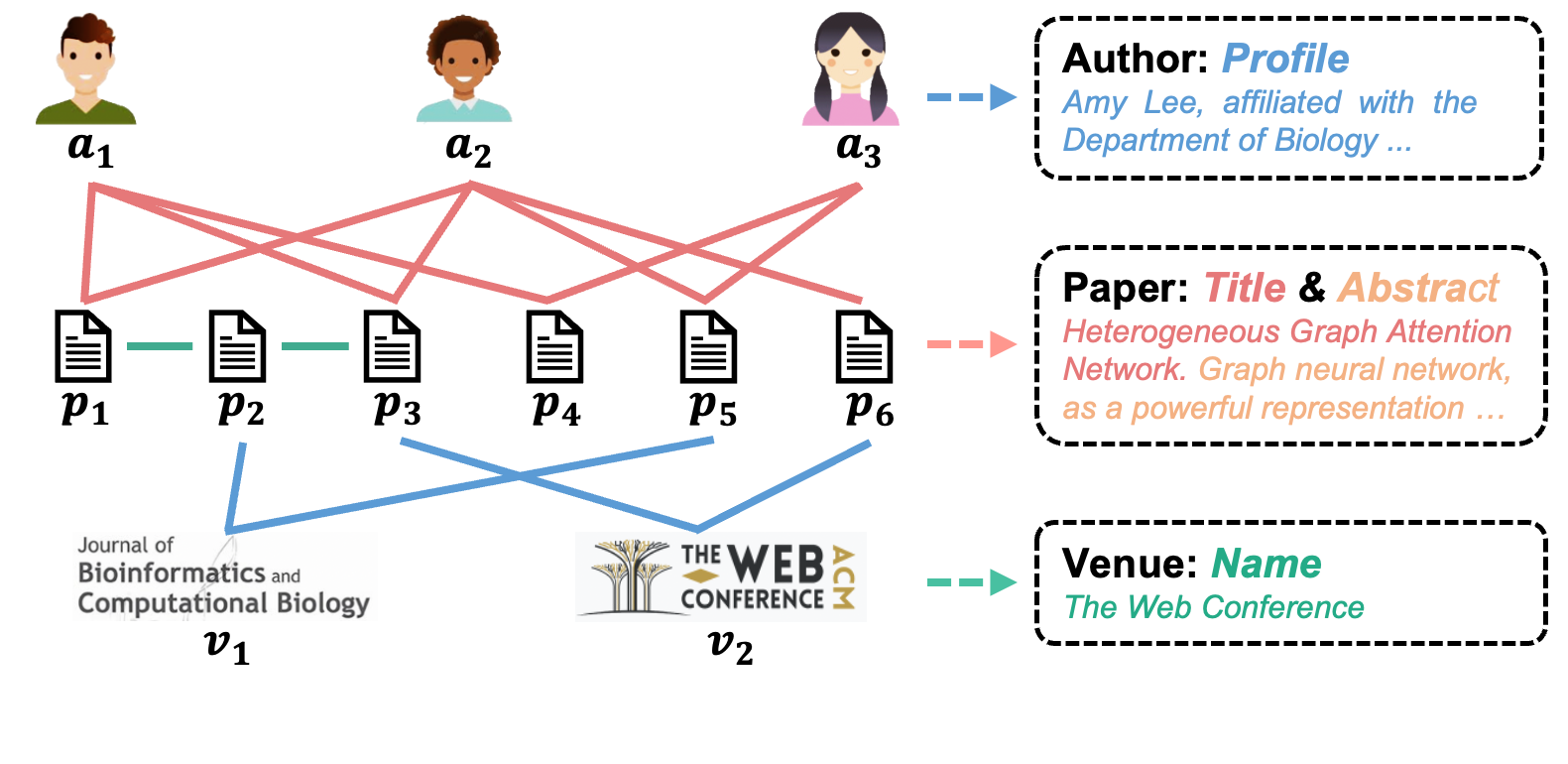
本文提出了一种用于异构富文本网络(HTRNs)表示学习的纯预训练语言模型(PLM)框架HierPromptLM。HTRNs由多种类型的节点和边组成,每个节点都关联着文本信息,在现实世界中有着广泛的应用。现有方法通常将文本和结构信息分开处理,使用PLM和异构图神经网络(HGNN),忽略了HTRNs中这两种信息之间的关键交互。此外,由于PLM和HGNN生成的嵌入空间存在根本差异,还需要额外的对齐步骤,这极具挑战性。HierPromptLM通过层级Prompt模块,在统一的文本空间中整合节点和边的文本数据和异构图结构,从而无缝地建模文本数据和图结构,无需单独处理。此外,还引入了两个专门为HTRN设计的预训练任务,通过强调HTRN中文本和结构信息之间的内在异构性和交互来微调PLM。在两个真实HTRN数据集上的大量实验表明,HierPromptLM优于最先进的方法,在节点分类和链接预测方面分别实现了高达6.08%和10.84%的显著改进。
🔬 方法详解
问题定义:现有异构富文本网络表示学习方法通常将文本信息和图结构信息分开处理,分别使用预训练语言模型(PLM)和异构图神经网络(HGNN)。这种分离处理方式忽略了文本和结构信息之间存在的内在关联和相互影响。此外,由于PLM和HGNN产生的嵌入向量位于不同的空间,需要额外的对齐步骤,增加了模型的复杂性和训练难度。
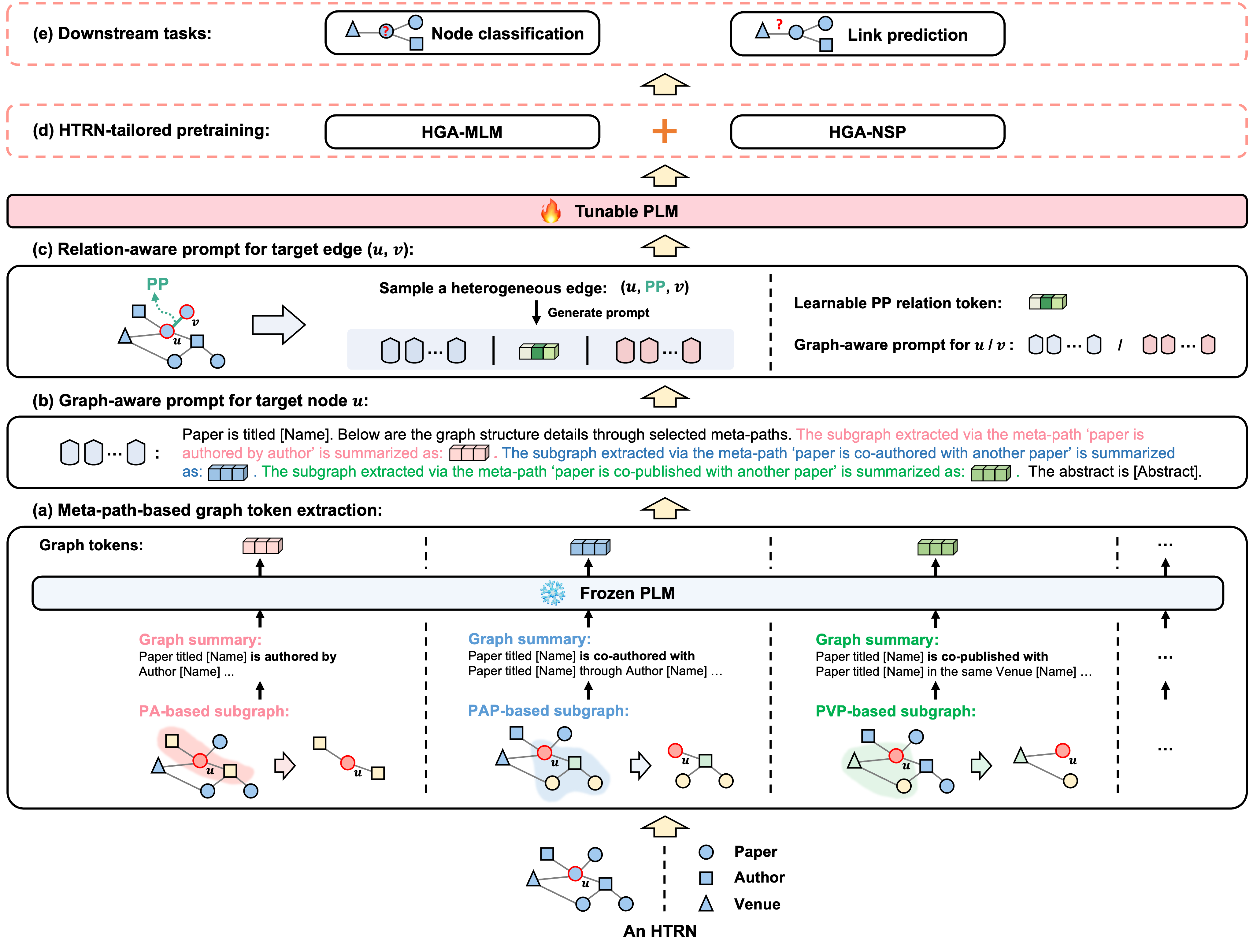
核心思路:HierPromptLM的核心思路是将文本信息和图结构信息统一到预训练语言模型的文本空间中进行建模。通过Prompt Learning的方式,将节点和边的信息转化为文本描述,然后利用PLM强大的文本建模能力来学习节点和边的表示。这样可以避免分离处理带来的信息损失和对齐问题。
技术框架:HierPromptLM框架主要包含两个核心模块:层级Prompt模块和HTRN预训练任务。层级Prompt模块负责将节点和边的信息转化为文本描述,包括节点级别的Prompt和边级别的Prompt。HTRN预训练任务则用于微调PLM,使其更好地适应HTRN表示学习任务。整体流程是:首先,使用层级Prompt模块将HTRN转化为文本序列;然后,使用预训练的PLM对文本序列进行编码,得到节点和边的表示;最后,使用HTRN预训练任务对PLM进行微调。
关键创新:HierPromptLM的关键创新在于提出了一个纯PLM的框架,避免了使用HGNN,从而避免了文本和结构信息的分离处理以及后续的对齐问题。此外,层级Prompt模块的设计能够有效地将节点和边的信息转化为文本描述,使得PLM能够更好地理解和利用图结构信息。HTRN预训练任务的设计则能够进一步提升PLM在HTRN表示学习任务上的性能。
关键设计:层级Prompt模块包含节点Prompt和边Prompt。节点Prompt将节点类型和节点文本信息拼接成文本描述。边Prompt将起始节点、关系类型和目标节点的信息拼接成文本描述。HTRN预训练任务包括Masked Node Attribute Prediction和Heterogeneous Relation Prediction。Masked Node Attribute Prediction任务旨在预测被mask的节点属性。Heterogeneous Relation Prediction任务旨在预测节点之间的关系类型。损失函数采用交叉熵损失函数。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HierPromptLM在节点分类和链接预测任务上均取得了显著的性能提升。在节点分类任务上,HierPromptLM相比于现有最佳方法提升了高达6.08%。在链接预测任务上,HierPromptLM相比于现有最佳方法提升了高达10.84%。这些结果验证了HierPromptLM的有效性,表明其能够更好地捕捉HTRN中文本和结构信息之间的交互。
🎯 应用场景
该研究成果可广泛应用于社交网络分析、知识图谱推理、推荐系统等领域。例如,在社交网络中,可以利用该方法学习用户和帖子之间的表示,用于用户画像、社区发现和内容推荐。在知识图谱中,可以学习实体和关系之间的表示,用于知识图谱补全和推理。该研究的未来影响在于推动了图神经网络和预训练语言模型的融合,为解决复杂网络表示学习问题提供了新的思路。
📄 摘要(原文)
Representation learning on heterogeneous text-rich networks (HTRNs), which consist of multiple types of nodes and edges with each node associated with textual information, is essential for various real-world applications. Given the success of pretrained language models (PLMs) in processing text data, recent efforts have focused on integrating PLMs into HTRN representation learning. These methods typically handle textual and structural information separately, using both PLMs and heterogeneous graph neural networks (HGNNs). However, this separation fails to capture the critical interactions between these two types of information within HTRNs. Additionally, it necessitates an extra alignment step, which is challenging due to the fundamental differences between distinct embedding spaces generated by PLMs and HGNNs. To deal with it, we propose HierPromptLM, a novel pure PLM-based framework that seamlessly models both text data and graph structures without the need for separate processing. Firstly, we develop a Hierarchical Prompt module that employs prompt learning to integrate text data and heterogeneous graph structures at both the node and edge levels, within a unified textual space. Building upon this foundation, we further introduce two innovative HTRN-tailored pretraining tasks to fine-tune PLMs for representation learning by emphasizing the inherent heterogeneity and interactions between textual and structural information within HTRNs. Extensive experiments on two real-world HTRN datasets demonstrate HierPromptLM outperforms state-of-the-art methods, achieving significant improvements of up to 6.08% for node classification and 10.84% for link prediction.