IC-Cache: Efficient Large Language Model Serving via In-context Caching
作者: Yifan Yu, Yu Gan, Nikhil Sarda, Lillian Tsai, Jiaming Shen, Yanqi Zhou, Arvind Krishnamurthy, Fan Lai, Henry M. Levy, David Culler
分类: cs.LG
发布日期: 2025-01-22 (更新: 2025-09-04)
💡 一句话要点
IC-Cache:通过上下文缓存提升大语言模型服务效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 缓存系统 请求路由 服务优化
📋 核心要点
- 现有LLM服务面临高资源需求和高延迟挑战,简单缓存重用导致质量下降。
- IC-Cache利用历史请求-响应对作为上下文示例,增强小型LLM能力,实现选择性卸载。
- 实验表明,IC-Cache在不降低响应质量的前提下,显著提升吞吐量并降低延迟。
📝 摘要(中文)
大型语言模型(LLM)在各种应用中表现出色,但由于其巨大的资源需求和高延迟,大规模服务这些模型极具挑战性。我们的实际研究表明,超过70%的用户LLM请求具有语义相似的对应请求,这表明请求之间存在知识转移的潜力。然而,简单地缓存和重用过去的响应会导致严重的质量下降。本文介绍了一种缓存系统IC-Cache,它通过利用来自更大模型的历史请求-响应对作为上下文示例,实现LLM能力的实时增强,从而提高服务效率。IC-Cache使小型LLM能够模仿甚至超越其大型对应模型的组合能力(例如,推理),从而能够选择性地卸载请求以降低成本和延迟。大规模实现这种实时增强引入了响应质量、延迟和系统吞吐量之间复杂的权衡。对于新请求,IC-Cache有效地选择相似的、高实用性的示例,并将它们添加到新请求的输入中。在规模上,它自适应地跨不同能力的LLM路由请求,同时考虑响应质量和服务负载。IC-Cache采用成本感知的缓存重放机制,离线优化示例质量,以最大限度地提高在线缓存的效用和效率。对数百万真实请求的评估表明,IC-Cache将LLM服务吞吐量提高了1.4-5.9倍,并将延迟降低了28-71%,而不会损害响应质量。
🔬 方法详解
问题定义:论文旨在解决大规模LLM服务中高延迟和高成本的问题。现有方法,如直接缓存LLM的输出,虽然简单,但会显著降低响应质量,无法有效利用LLM的上下文学习能力。此外,如何根据请求的特性,动态选择合适的LLM进行服务,也是一个挑战。
核心思路:IC-Cache的核心思路是利用上下文学习(In-context Learning)的思想,将历史请求-响应对作为上下文示例,添加到新的请求中,从而增强小型LLM的能力,使其能够模仿甚至超越大型LLM的性能。通过这种方式,可以将一部分请求卸载到小型LLM上,从而降低整体的延迟和成本。
技术框架:IC-Cache的整体架构包含以下几个主要模块:1) 请求相似度计算:计算新请求与历史请求的相似度,选择最相关的示例。2) 上下文示例选择:根据相似度得分和示例的质量,选择合适的上下文示例。3) 请求路由:根据请求的复杂度和LLM的负载,将请求路由到合适的LLM(大型或小型)。4) 缓存重放:离线优化缓存中的示例质量,提高在线缓存的效用。
关键创新:IC-Cache的关键创新在于其将上下文学习与缓存机制相结合,实现了LLM能力的实时增强。与传统的缓存方法不同,IC-Cache不仅缓存LLM的输出,还缓存请求-响应对,并将其作为上下文示例添加到新的请求中。此外,IC-Cache还引入了成本感知的缓存重放机制,离线优化示例质量,进一步提高了缓存的效率。
关键设计:IC-Cache的关键设计包括:1) 相似度度量:使用语义相似度模型(例如,Sentence-BERT)计算请求之间的相似度。2) 示例质量评估:使用奖励模型评估示例的质量,例如,使用LLM本身对示例的合理性进行评分。3) 请求路由策略:根据请求的复杂度和LLM的负载,动态调整请求路由策略,例如,使用强化学习算法优化路由策略。
🖼️ 关键图片
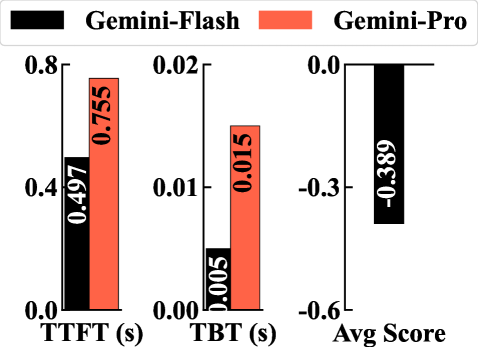
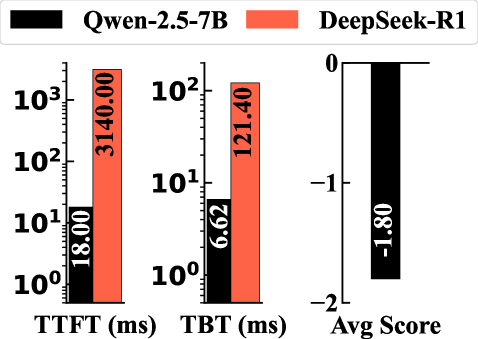
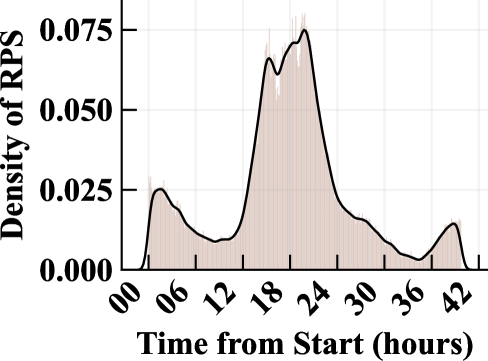
📊 实验亮点
在数百万真实请求的评估中,IC-Cache将LLM服务吞吐量提高了1.4-5.9倍,并将延迟降低了28-71%,而没有显著降低响应质量。这些结果表明,IC-Cache是一种有效的LLM服务优化方法,可以显著提高LLM服务的效率和用户体验。与直接缓存相比,IC-Cache能够更好地保持LLM的生成质量。
🎯 应用场景
IC-Cache可广泛应用于各种需要大规模LLM服务的场景,例如智能客服、内容生成、代码生成等。通过降低延迟和成本,IC-Cache可以使更多的用户能够访问LLM服务,并促进LLM在各个领域的应用。未来,IC-Cache可以进一步扩展到支持多模态输入,并与其他优化技术(例如,模型压缩、量化)相结合,以进一步提高LLM服务的效率。
📄 摘要(原文)
Large language models (LLMs) have excelled in various applications, yet serving them at scale is challenging due to their substantial resource demands and high latency. Our real-world studies reveal that over 70% of user requests to LLMs have semantically similar counterparts, suggesting the potential for knowledge transfer among requests. However, naively caching and reusing past responses leads to a big quality drop. In this paper, we introduce IC-Cache, a caching system that enables live LLM capability augmentation to improve serving efficiency: by leveraging historical request-response pairs from larger models as in-context examples, IC-Cache empowers small LLMs to imitate and even exceed the compositional abilities (e.g., reasoning) of their larger counterparts, enabling selective offloading of requests to reduce cost and latency. Achieving this live augmentation at scale introduces intricate trade-offs between response quality, latency, and system throughput. For a new request, IC-Cache efficiently selects similar, high-utility examples to prepend them to the new request's input. At scale, it adaptively routes requests across LLMs of varying capabilities, accounting for response quality and serving loads. IC-Cache employs a cost-aware cache replay mechanism that refines example quality offline to maximize online cache utility and efficiency. Evaluations on millions of realistic requests demonstrate that IC-Cache improves LLM serving throughput by 1.4-5.9x and reduces latency by 28-71% without hurting response quality.