Inverse Reinforcement Learning with Switching Rewards and History Dependency for Characterizing Animal Behaviors
作者: Jingyang Ke, Feiyang Wu, Jiyi Wang, Jeffrey Markowitz, Anqi Wu
分类: cs.LG, cs.AI
发布日期: 2025-01-22 (更新: 2025-07-15)
💡 一句话要点
SWIRL:一种结合时变奖励与历史依赖的逆强化学习方法,用于刻画动物行为
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 逆强化学习 动物行为 历史依赖 时变奖励 决策过程
📋 核心要点
- 传统动物决策研究依赖简化任务和显式奖励,难以捕捉自然环境中由内在动机驱动的复杂行为。
- SWIRL通过引入时变、历史依赖的奖励函数,将长时行为建模为短期决策过程的转换,从而捕捉历史对决策的影响。
- 实验表明,SWIRL在模拟和真实动物行为数据集上优于缺乏历史依赖性的模型,能更准确地描述动物决策。
📝 摘要(中文)
本研究针对神经科学中动物决策研究的传统方法局限性,即过度依赖简化行为任务和显式奖励,提出了SWIRL(SWitching IRL)框架。该框架通过引入时变、历史依赖的奖励函数,扩展了传统的逆强化学习(IRL)。SWIRL将长时间的行为序列建模为短期决策过程之间的转换,每个过程由独特的奖励函数驱动。通过结合生物学上合理的历史依赖性,SWIRL能够捕捉过去决策和环境背景如何影响行为,从而更准确地描述动物的决策过程。在模拟和真实动物行为数据集上的实验结果表明,SWIRL在定量和定性方面均优于缺乏历史依赖性的模型。该工作是首个结合历史依赖策略和奖励的IRL模型,旨在推进对动物复杂、自然决策行为的理解。
🔬 方法详解
问题定义:现有研究动物决策的方法通常依赖于简化的行为任务,动物在这些任务中重复执行刻板的行为以获得明确的奖励。然而,这种方法无法捕捉动物在自然环境中表现出的复杂、长期的行为,这些行为通常由难以观察的内在动机驱动。现有的时变逆强化学习(IRL)方法试图捕捉长期自由移动行为中不断变化的动机,但忽略了动物的决策是基于其历史而非仅仅当前状态的事实。
核心思路:SWIRL的核心思路是将长时间的行为序列分解为一系列短期的决策过程,每个过程都由一个独特的奖励函数驱动。通过引入历史依赖性,SWIRL能够捕捉过去的行为和环境背景如何影响当前的决策。这种方法更符合生物学上的实际情况,因为动物的决策往往受到其过去经验的影响。
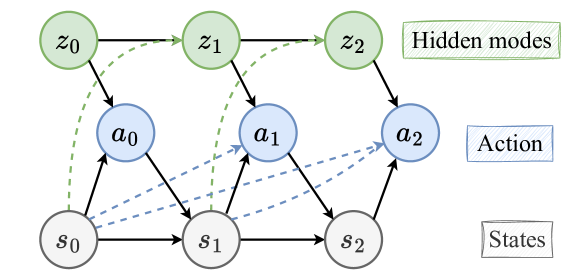
技术框架:SWIRL框架主要包含以下几个部分:1) 状态表示:将动物的行为和环境信息编码为状态向量。2) 奖励函数:为每个短期决策过程定义一个奖励函数,该函数不仅依赖于当前状态,还依赖于历史信息。3) 策略学习:使用逆强化学习算法,从动物的行为数据中推断出每个决策过程的奖励函数和策略。4) 状态转移:定义状态之间的转移规则,模拟动物在不同决策过程之间的切换。
关键创新:SWIRL的关键创新在于将历史依赖性引入到时变的逆强化学习框架中。传统的IRL方法通常假设奖励函数只依赖于当前状态,而SWIRL则允许奖励函数依赖于过去的状态和行为。这种历史依赖性使得SWIRL能够更准确地捕捉动物的决策过程,并更好地解释其复杂的行为模式。
关键设计:SWIRL中历史依赖性的实现方式是使用循环神经网络(RNN)来编码过去的状态和行为。RNN的输出被用作奖励函数的输入,从而使得奖励函数能够捕捉到历史信息的影响。此外,SWIRL还使用了一种特殊的损失函数,该函数鼓励模型学习到具有生物学意义的奖励函数。具体的参数设置和网络结构的选择需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
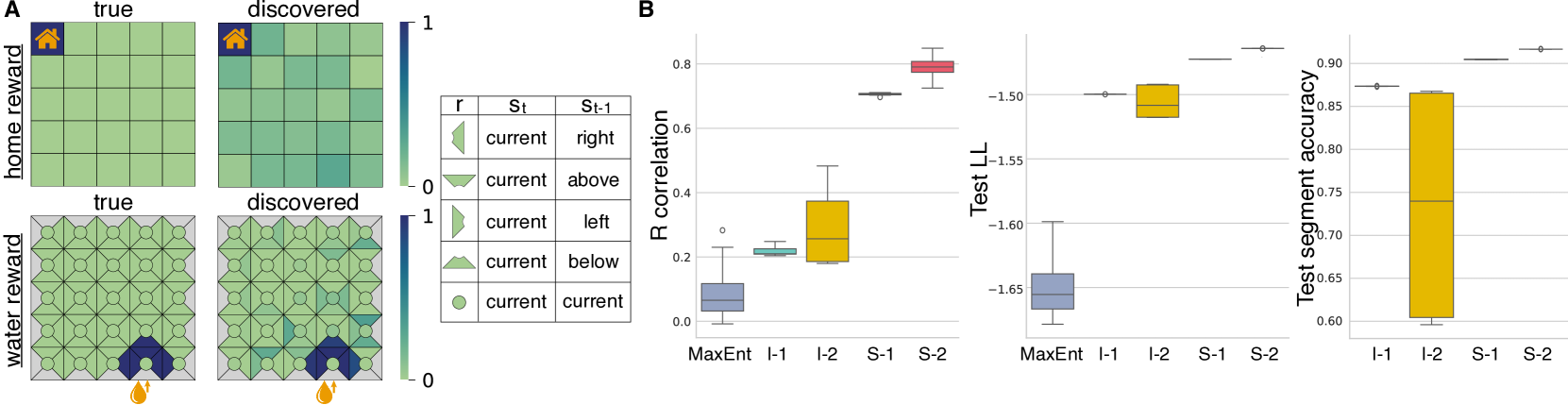
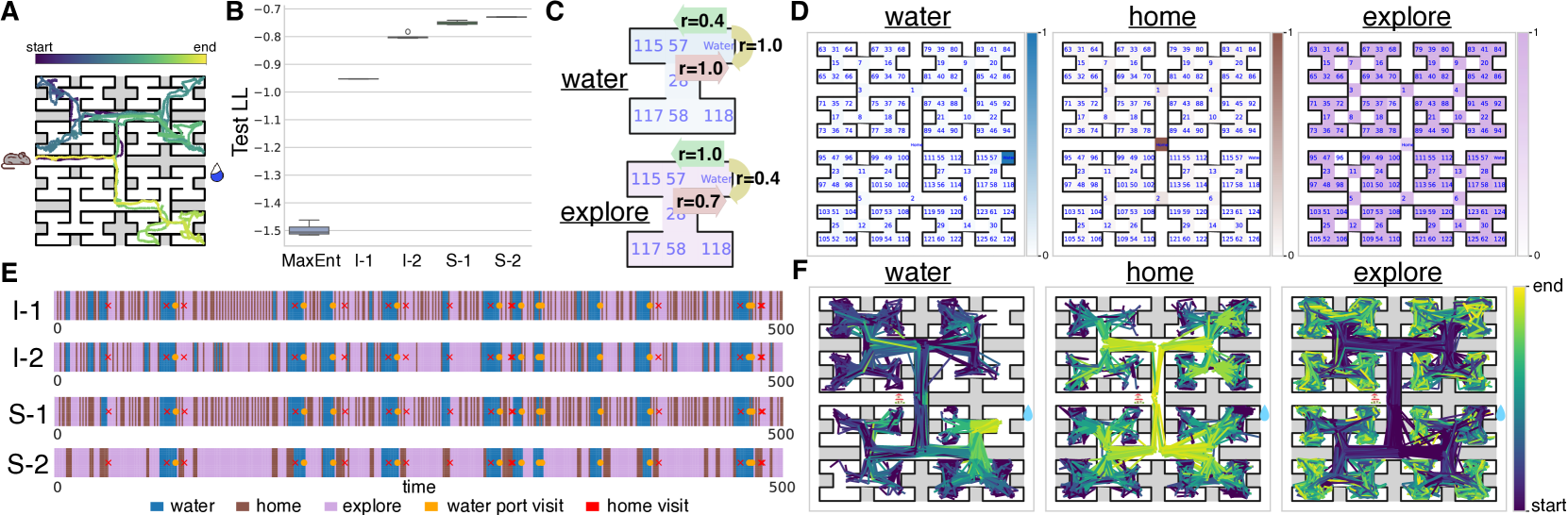
SWIRL在模拟和真实动物行为数据集上进行了评估。实验结果表明,SWIRL在定量和定性方面均优于缺乏历史依赖性的模型。例如,在模拟数据集上,SWIRL能够更准确地恢复真实的奖励函数。在真实动物行为数据集上,SWIRL能够更好地预测动物的未来行为。这些结果表明,SWIRL是一种有效的动物行为建模工具。
🎯 应用场景
SWIRL框架可应用于多种领域,例如:1) 动物行为学研究:帮助研究人员理解动物的决策过程和内在动机。2) 机器人控制:设计更智能、更自主的机器人,使其能够适应复杂、动态的环境。3) 行为经济学:研究人类的决策行为,并预测其未来的行为模式。该研究具有重要的理论价值和实际意义,有望推动相关领域的发展。
📄 摘要(原文)
Traditional approaches to studying decision-making in neuroscience focus on simplified behavioral tasks where animals perform repetitive, stereotyped actions to receive explicit rewards. While informative, these methods constrain our understanding of decision-making to short timescale behaviors driven by explicit goals. In natural environments, animals exhibit more complex, long-term behaviors driven by intrinsic motivations that are often unobservable. Recent works in time-varying inverse reinforcement learning (IRL) aim to capture shifting motivations in long-term, freely moving behaviors. However, a crucial challenge remains: animals make decisions based on their history, not just their current state. To address this, we introduce SWIRL (SWitching IRL), a novel framework that extends traditional IRL by incorporating time-varying, history-dependent reward functions. SWIRL models long behavioral sequences as transitions between short-term decision-making processes, each governed by a unique reward function. SWIRL incorporates biologically plausible history dependency to capture how past decisions and environmental contexts shape behavior, offering a more accurate description of animal decision-making. We apply SWIRL to simulated and real-world animal behavior datasets and show that it outperforms models lacking history dependency, both quantitatively and qualitatively. This work presents the first IRL model to incorporate history-dependent policies and rewards to advance our understanding of complex, naturalistic decision-making in animals.