Deep Reinforcement Learning with Hybrid Intrinsic Reward Model
作者: Mingqi Yuan, Bo Li, Xin Jin, Wenjun Zeng
分类: cs.LG
发布日期: 2025-01-22
备注: 18 pages, 14 figures
💡 一句话要点
提出HIRE框架,通过混合内在奖励提升强化学习探索效率与技能学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 内在奖励 探索策略 混合奖励 技能学习
📋 核心要点
- 现有内在奖励方法在强化学习探索中存在局限性,单一奖励类型限制了探索的多样性和效率。
- HIRE框架通过融合多种内在奖励,实现更灵活和高效的探索策略,提升智能体在复杂环境中的表现。
- 实验结果表明,HIRE显著提升了探索效率、多样性以及技能学习能力,尤其是在复杂动态环境中。
📝 摘要(中文)
内在奖励塑造已成为解决强化学习中难探索和稀疏奖励环境的常用方法。虽然单一内在奖励(如好奇心驱动或基于新颖性的方法)已显示出有效性,但它们通常限制了探索的多样性和效率。此外,组合多个内在奖励的潜力和原理仍未得到充分探索。为了解决这一差距,我们引入了HIRE(混合内在奖励),这是一个灵活而优雅的框架,用于通过有意的融合策略创建混合内在奖励。借助HIRE,我们对混合内在奖励在通用和无监督强化学习中的应用进行了系统分析,涵盖多个基准。大量实验表明,HIRE可以显著提高复杂和动态环境中的探索效率和多样性,以及技能获取能力。
🔬 方法详解
问题定义:强化学习在稀疏奖励和难探索环境中面临挑战,现有的单一内在奖励方法无法充分驱动智能体进行有效探索,限制了学习效率和最终性能。如何有效地结合多种内在奖励,从而提升探索效率和多样性,是本论文要解决的核心问题。
核心思路:论文的核心思路是通过混合多种内在奖励信号,利用不同奖励信号的优势互补,从而更全面地引导智能体进行探索。这种混合策略旨在克服单一内在奖励的局限性,例如,好奇心驱动可能导致智能体陷入局部最优,而新颖性驱动可能忽略重要但非新颖的状态。
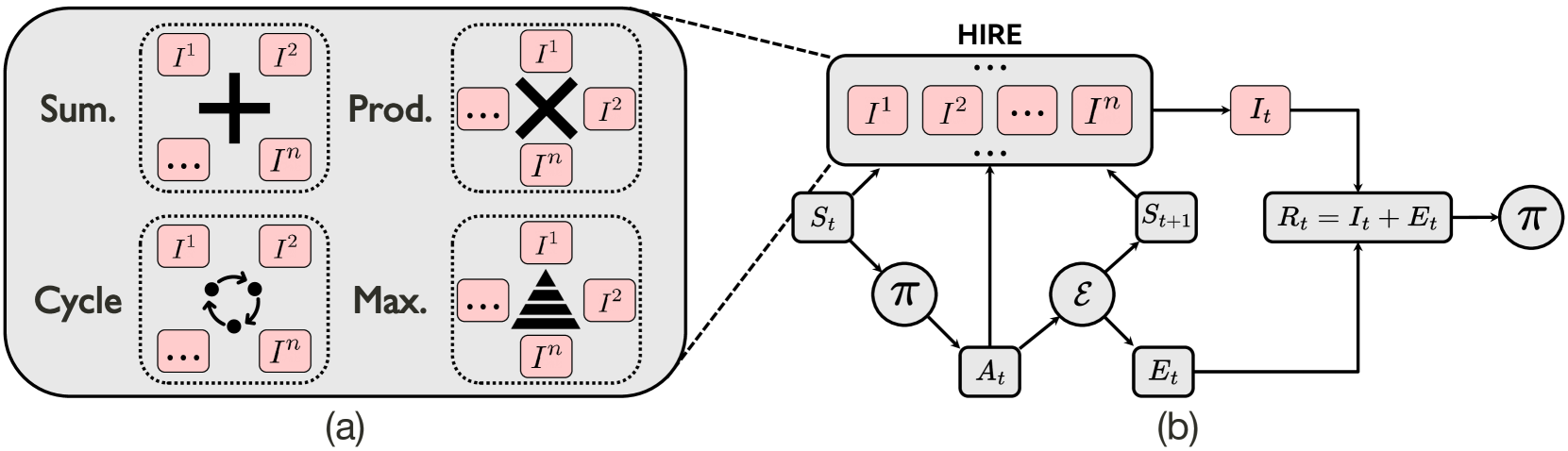
技术框架:HIRE框架包含多个内在奖励模块,每个模块负责生成一种内在奖励信号(例如,基于预测误差的好奇心奖励,基于状态访问频率的新颖性奖励)。框架的核心在于一个融合模块,该模块负责根据一定的策略(例如,加权平均、动态权重调整)将多个内在奖励信号组合成一个混合内在奖励。最终,混合内在奖励与环境提供的外在奖励结合,共同驱动智能体的策略学习。
关键创新:HIRE的关键创新在于提出了一个灵活的混合内在奖励框架,允许研究人员根据具体任务和环境特点,选择和组合不同的内在奖励信号。此外,框架还支持动态调整不同内在奖励的权重,从而更好地适应智能体在学习过程中的不同阶段。这种混合策略能够有效地平衡探索的广度和深度,提升学习效率。
关键设计:HIRE框架的关键设计包括:1) 多种内在奖励模块的选择和实现,例如,可以使用基于预测误差的内在奖励、基于状态访问频率的内在奖励等;2) 融合模块的设计,可以选择简单的加权平均,也可以使用更复杂的动态权重调整策略,例如,基于强化学习的权重学习方法;3) 混合内在奖励与外在奖励的结合方式,通常采用简单的加权求和,但也可以根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
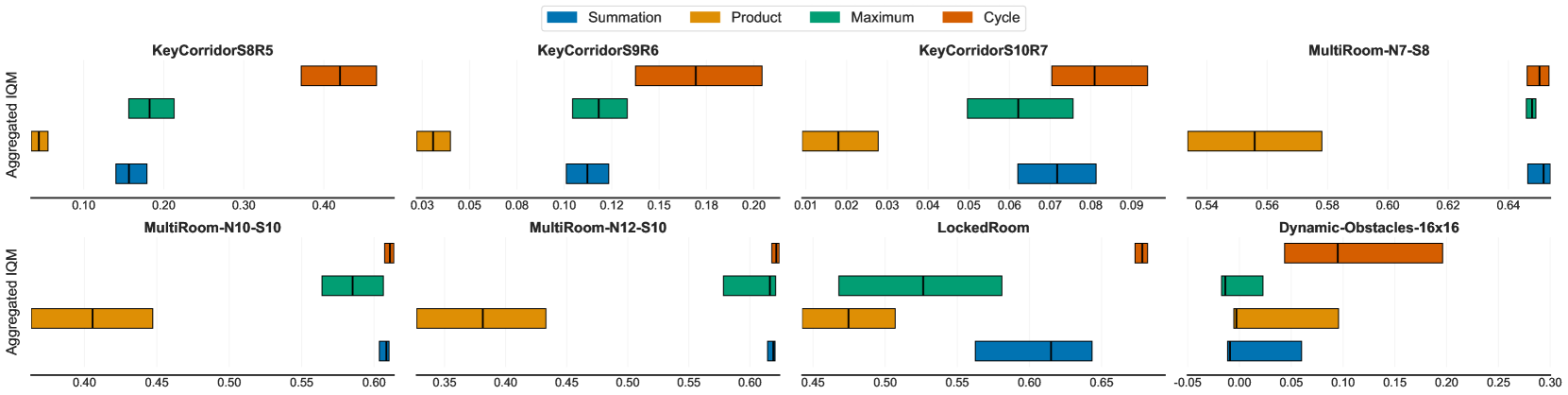
实验结果表明,HIRE框架在多个基准测试中显著优于现有的单一内在奖励方法。例如,在Atari游戏中,HIRE框架在多个游戏中取得了更高的平均奖励,并且在一些难探索游戏中取得了显著的性能提升。此外,实验还表明,HIRE框架能够有效地提升智能体在复杂动态环境中的技能学习能力。
🎯 应用场景
HIRE框架具有广泛的应用前景,可应用于机器人导航、游戏AI、自动驾驶等领域。通过提升智能体在复杂环境中的探索能力,HIRE可以帮助智能体更快地学习到有效的策略,从而解决实际应用中的难题。此外,该框架还可以用于无监督强化学习,帮助智能体自主地学习有用的技能。
📄 摘要(原文)
Intrinsic reward shaping has emerged as a prevalent approach to solving hard-exploration and sparse-rewards environments in reinforcement learning (RL). While single intrinsic rewards, such as curiosity-driven or novelty-based methods, have shown effectiveness, they often limit the diversity and efficiency of exploration. Moreover, the potential and principle of combining multiple intrinsic rewards remains insufficiently explored. To address this gap, we introduce HIRE (Hybrid Intrinsic REward), a flexible and elegant framework for creating hybrid intrinsic rewards through deliberate fusion strategies. With HIRE, we conduct a systematic analysis of the application of hybrid intrinsic rewards in both general and unsupervised RL across multiple benchmarks. Extensive experiments demonstrate that HIRE can significantly enhance exploration efficiency and diversity, as well as skill acquisition in complex and dynamic settings.