The Journey Matters: Average Parameter Count over Pre-training Unifies Sparse and Dense Scaling Laws
作者: Tian Jin, Ahmed Imtiaz Humayun, Utku Evci, Suvinay Subramanian, Amir Yazdanbakhsh, Dan Alistarh, Gintare Karolina Dziugaite
分类: cs.LG, cs.CL
发布日期: 2025-01-21 (更新: 2025-03-15)
备注: 17 pages
💡 一句话要点
提出基于平均参数计数的缩放法则,统一稀疏和稠密预训练LLM的性能预测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏预训练 大型语言模型 剪枝 缩放法则 平均参数计数
📋 核心要点
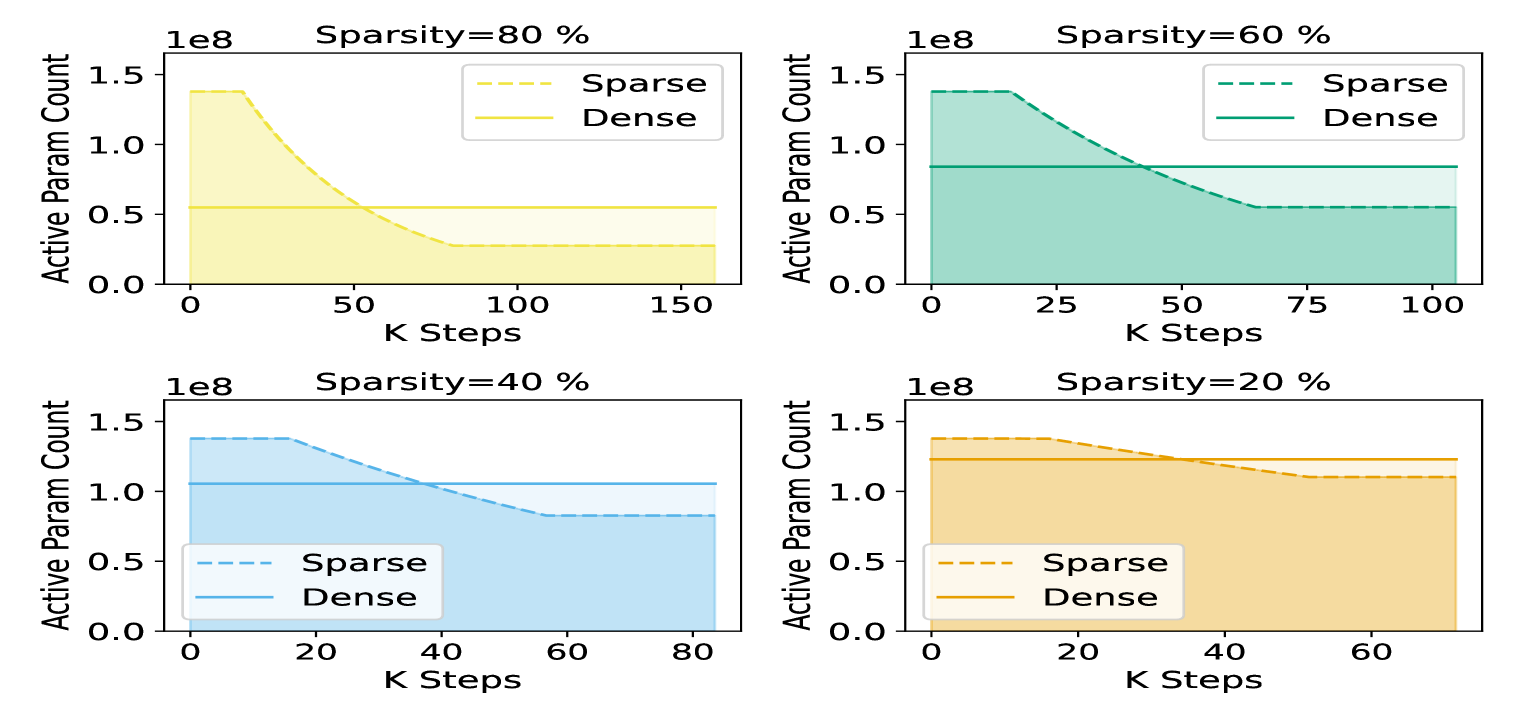
- 大型语言模型计算需求高,后训练剪枝复杂,稀疏预训练是更优选择,但缺乏系统性探索。
- 通过探索不同剪枝策略,论文发现最佳剪枝时机,并提出基于平均参数计数的统一缩放法则。
- 实验表明,稀疏预训练在同等计算量下可达相同模型质量,并因模型更小而节省推理计算。
📝 摘要(中文)
本文针对大型语言模型(LLMs)日益增长的计算需求,探索了稀疏预训练这一更简单的替代方案,它将剪枝和预训练结合在一个阶段。通过对不同稀疏度和训练时长下的80种独特剪枝策略的考察,我们对LLMs的最佳稀疏预训练配置进行了首次系统性探索。研究发现,在总训练计算量的25%处开始剪枝,并在75%处结束,可以实现接近最优的最终评估损失。这些发现为LLMs的高效稀疏预训练提供了有价值的见解。此外,我们提出了一种新的缩放法则,它修改了Chinchilla缩放法则,使用预训练期间的平均参数计数。通过实证和理论验证,我们证明了这种修改后的缩放法则能够准确地模拟稀疏和稠密预训练LLMs的评估损失,从而统一了不同预训练范式的缩放法则。我们的研究结果表明,对于相同的计算预算,稀疏预训练可以达到与稠密预训练相同的最终模型质量,但它通过减少模型大小提供了显著的优势,从而在推理过程中实现了巨大的潜在计算节省。
🔬 方法详解
问题定义:现有大型语言模型(LLMs)的训练需要巨大的计算资源。虽然后训练剪枝可以减小模型大小,但稀疏预训练,即在预训练过程中进行剪枝,是一种更简单有效的方法。然而,目前缺乏对LLMs稀疏预训练配置的系统性研究,无法确定最佳的剪枝策略和时间安排。
核心思路:论文的核心思路是通过大规模实验探索不同的剪枝策略,找到最佳的剪枝时间窗口,并提出一种新的缩放法则,该法则能够统一描述稀疏和稠密预训练模型的性能。通过使用预训练期间的平均参数数量,该缩放法则能够更准确地预测模型的最终评估损失。
技术框架:该研究的技术框架主要包括以下几个阶段:1)设计并实施80种不同的剪枝策略,涵盖不同的稀疏度和训练时长;2)使用这些策略对LLMs进行稀疏预训练;3)评估预训练模型的性能,并分析不同剪枝策略的影响;4)提出基于平均参数计数的缩放法则,并进行理论和实证验证。
关键创新:论文的关键创新在于:1)首次对LLMs的稀疏预训练配置进行了系统性探索,揭示了最佳的剪枝时间窗口;2)提出了基于平均参数计数的缩放法则,该法则能够统一描述稀疏和稠密预训练模型的性能,解决了现有缩放法则无法有效处理稀疏模型的问题。
关键设计:论文的关键设计包括:1)剪枝策略的设计,涵盖不同的稀疏度和训练时长,以全面探索最佳配置;2)平均参数计数的计算方法,用于修正Chinchilla缩放法则;3)实验验证,通过在不同数据集和模型上进行实验,验证了所提出的缩放法则的有效性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在总训练计算量的25%处开始剪枝,并在75%处结束,可以实现接近最优的最终评估损失。提出的基于平均参数计数的缩放法则能够准确地模拟稀疏和稠密预训练LLMs的评估损失,优于传统的Chinchilla缩放法则。稀疏预训练在同等计算量下可达相同模型质量,并因模型更小而节省推理计算。
🎯 应用场景
该研究成果可应用于大规模语言模型的预训练,通过稀疏预训练降低计算成本和模型大小,从而加速模型训练和部署。该方法尤其适用于资源受限的场景,例如边缘设备或移动设备,可以实现更高效的LLM推理。此外,统一的缩放法则有助于更好地理解和预测不同预训练策略下的模型性能。
📄 摘要(原文)
Pruning eliminates unnecessary parameters in neural networks; it offers a promising solution to the growing computational demands of large language models (LLMs). While many focus on post-training pruning, sparse pre-training--which combines pruning and pre-training into a single phase--provides a simpler alternative. In this work, we present the first systematic exploration of optimal sparse pre-training configurations for LLMs through an examination of 80 unique pruning schedules across different sparsity levels and training durations. We find that initiating pruning at 25% of total training compute and concluding at 75% achieves near-optimal final evaluation loss. These findings provide valuable insights for efficient and effective sparse pre-training of LLMs. Furthermore, we propose a new scaling law that modifies the Chinchilla scaling law to use the average parameter count over pre-training. Through empirical and theoretical validation, we demonstrate that this modified scaling law accurately models evaluation loss for both sparsely and densely pre-trained LLMs, unifying scaling laws across pre-training paradigms. Our findings indicate that while sparse pre-training achieves the same final model quality as dense pre-training for equivalent compute budgets, it provides substantial benefits through reduced model size, enabling significant potential computational savings during inference.