Adaptive PII Mitigation Framework for Large Language Models
作者: Shubhi Asthana, Ruchi Mahindru, Bing Zhang, Jorge Sanz
分类: cs.LG, cs.AI, cs.CR
发布日期: 2025-01-21
备注: This paper has been accepted at PPAI-25, the 6th AAAI Workshop on Privacy-Preserving Artificial Intelligence
💡 一句话要点
提出一种自适应PII缓解框架,用于应对大语言模型中的隐私合规挑战。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: PII缓解 大语言模型 隐私合规 自适应系统 NLP技术
📋 核心要点
- 大语言模型面临日益严格的隐私法规挑战,现有方法难以兼顾合规性和模型性能。
- 提出自适应PII缓解框架,通过NLP技术、上下文分析和策略驱动的掩码,动态适应不同法规。
- 实验表明,该系统在PII识别和用户信任度方面显著优于现有工具,验证了其有效性。
📝 摘要(中文)
人工智能正面临来自全球范围内不断发展的数据保护法律和执法实践的日益严峻的挑战。GDPR和CCPA等法规对机器学习模型提出了严格的合规要求,尤其是在个人数据使用方面。这些法律赋予个人数据更正和删除等权利,这使得依赖于广泛数据集的大型语言模型(LLM)的训练和部署变得复杂。公共数据的可用性并不能保证其用于机器学习的合法性,从而加剧了这些挑战。本文介绍了一种自适应系统,用于降低LLM中个人身份信息(PII)和敏感个人信息(SPI)的风险。它动态地与不同的监管框架保持一致,并无缝集成到治理、风险和合规性(GRC)系统中。该系统使用先进的NLP技术、上下文感知分析和策略驱动的掩码来确保法规遵从性。基准测试突出了该系统的有效性,Passport Numbers的F1得分为0.95,优于Microsoft Presidio(0.33)和Amazon Comprehend(0.54)等工具。在人工评估中,该系统获得了平均4.6/5的用户信任评分,参与者认可了其准确性和透明度。观察表明,与允许假名化和用户选择退出的CCPA相比,GDPR下的匿名化更为严格。这些结果验证了该系统作为企业隐私合规性的可扩展且稳健的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理包含个人身份信息(PII)和敏感个人信息(SPI)的数据时,如何满足不同地区和法规(如GDPR、CCPA)的合规性要求的问题。现有方法通常是静态的,无法灵活适应不断变化的法规,并且在准确性和效率方面存在不足,容易导致过度或不足的匿名化。
核心思路:论文的核心思路是构建一个自适应的PII缓解系统,该系统能够根据不同的法规要求动态调整其行为。通过结合先进的自然语言处理(NLP)技术、上下文感知分析和策略驱动的掩码,系统可以更准确地识别和处理PII,同时保持数据的可用性和模型的性能。
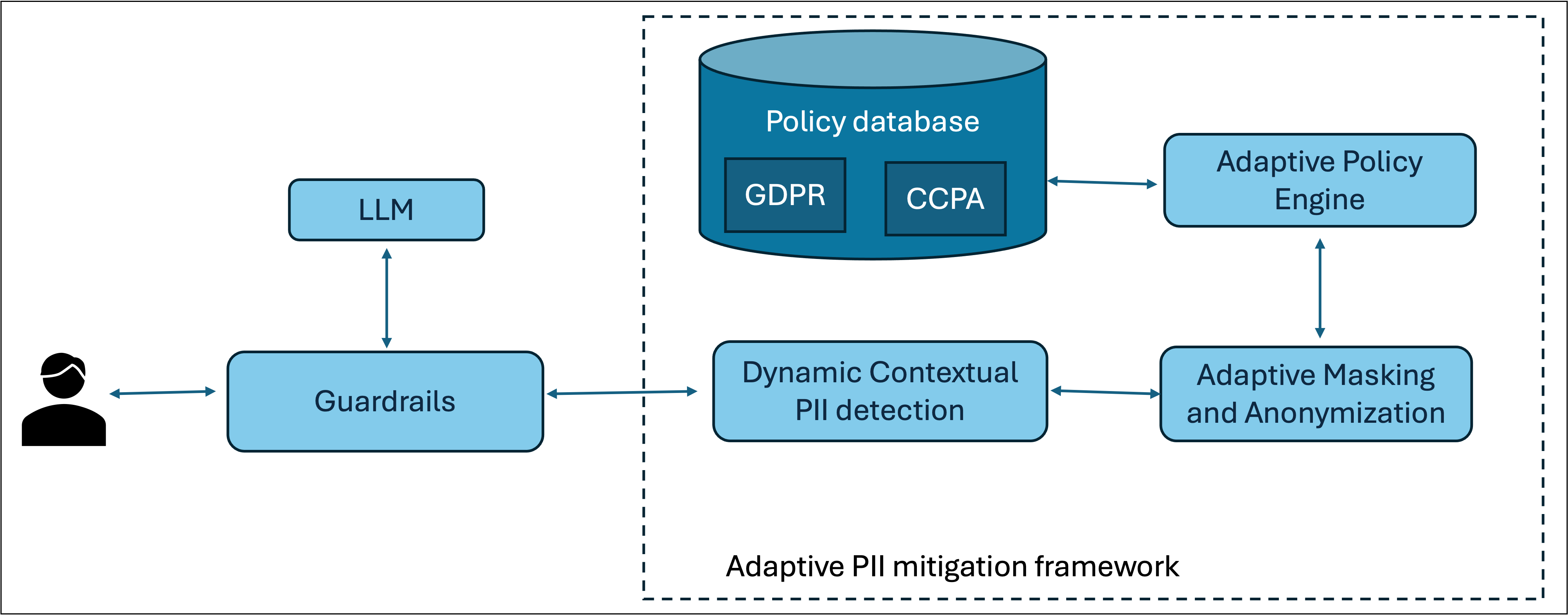
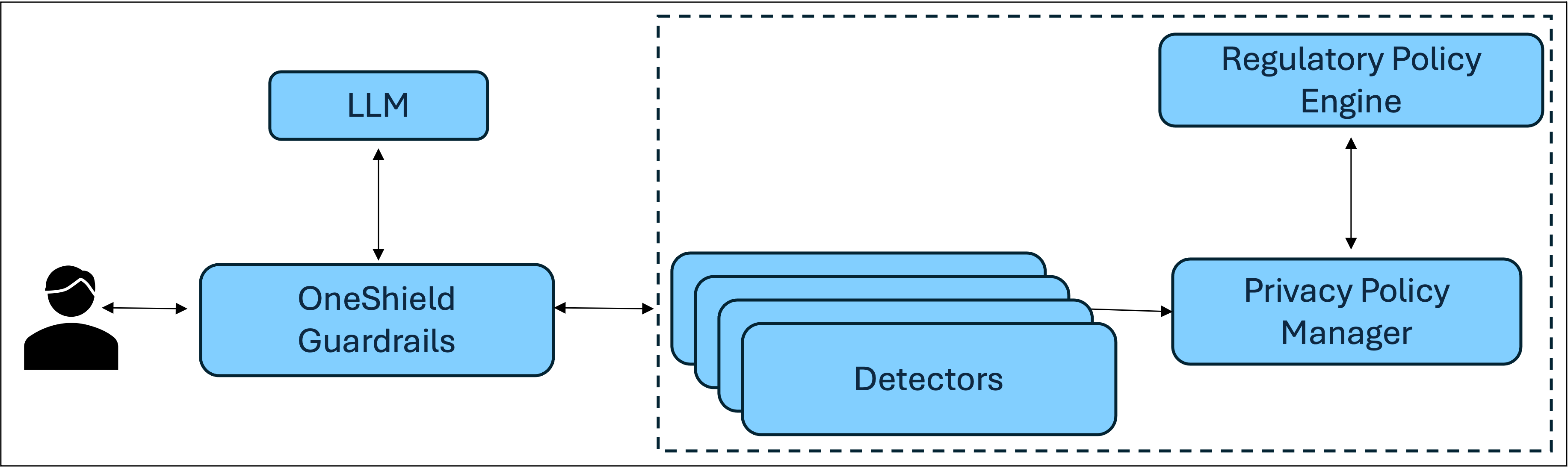
技术框架:该系统集成到治理、风险和合规性(GRC)系统中,包含以下主要模块:1) 数据输入模块:接收待处理的文本数据。2) 法规识别模块:根据输入数据确定适用的法规。3) PII识别模块:使用NLP技术和上下文分析识别文本中的PII。4) 策略引擎:根据适用的法规和预定义的策略,确定PII的处理方式(例如,掩码、删除、替换)。5) 匿名化模块:根据策略引擎的指示,对PII进行处理。6) 输出模块:输出经过匿名化处理的文本数据。
关键创新:该系统最重要的技术创新点在于其自适应性。传统的PII缓解系统通常是静态的,针对特定法规进行硬编码。而该系统能够动态地适应不同的法规,并根据法规的变化自动调整其行为。这种自适应性使得该系统能够更好地满足不同地区和行业的合规性要求。
关键设计:策略引擎是该系统的关键组件。它包含一组预定义的策略,这些策略定义了在不同法规下如何处理不同类型的PII。策略可以根据法规的变化进行更新和修改。此外,系统还使用了上下文感知的NLP技术,以提高PII识别的准确性。例如,系统会考虑PII周围的文本,以确定其是否真的是PII,以及应该如何处理它。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该系统在Passport Numbers的识别上取得了显著的性能提升,F1 score达到0.95,远超Microsoft Presidio (0.33) 和 Amazon Comprehend (0.54)。此外,在人工评估中,用户对该系统的信任度平均达到4.6/5,表明用户对其准确性和透明度高度认可。观察还发现,GDPR下的匿名化要求比CCPA更为严格。
🎯 应用场景
该研究成果可广泛应用于需要处理大量文本数据的企业和组织,例如金融、医疗、法律等行业。它可以帮助这些企业和组织降低因违反隐私法规而面临的法律风险和经济损失,同时提高数据处理的效率和安全性。未来,该技术有望进一步发展,实现更智能、更自动化的隐私保护。
📄 摘要(原文)
Artificial Intelligence (AI) faces growing challenges from evolving data protection laws and enforcement practices worldwide. Regulations like GDPR and CCPA impose strict compliance requirements on Machine Learning (ML) models, especially concerning personal data use. These laws grant individuals rights such as data correction and deletion, complicating the training and deployment of Large Language Models (LLMs) that rely on extensive datasets. Public data availability does not guarantee its lawful use for ML, amplifying these challenges. This paper introduces an adaptive system for mitigating risk of Personally Identifiable Information (PII) and Sensitive Personal Information (SPI) in LLMs. It dynamically aligns with diverse regulatory frameworks and integrates seamlessly into Governance, Risk, and Compliance (GRC) systems. The system uses advanced NLP techniques, context-aware analysis, and policy-driven masking to ensure regulatory compliance. Benchmarks highlight the system's effectiveness, with an F1 score of 0.95 for Passport Numbers, outperforming tools like Microsoft Presidio (0.33) and Amazon Comprehend (0.54). In human evaluations, the system achieved an average user trust score of 4.6/5, with participants acknowledging its accuracy and transparency. Observations demonstrate stricter anonymization under GDPR compared to CCPA, which permits pseudonymization and user opt-outs. These results validate the system as a scalable and robust solution for enterprise privacy compliance.