Audio Texture Manipulation by Exemplar-Based Analogy
作者: Kan Jen Cheng, Tingle Li, Gopala Anumanchipalli
分类: cs.SD, cs.LG, eess.AS
发布日期: 2025-01-21
备注: ICASSP 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于范例类比的音频纹理操控方法,通过配对语音样本实现声音转换。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 音频纹理操控 范例学习 潜在扩散模型 自监督学习 语音转换
📋 核心要点
- 现有音频操控方法依赖文本指令,难以精确控制声音转换的细节和风格。
- 该方法利用配对语音样本学习声音转换的类比关系,无需文本指令,更直观。
- 实验证明,该模型在多种音频编辑任务上优于文本条件基线,并具有良好的泛化能力。
📝 摘要(中文)
音频纹理操控涉及修改声音的感知特性,以实现特定的转换,例如添加、删除或替换听觉元素。本文提出了一种基于范例类比的音频纹理操控模型。该方法不依赖于基于文本的指令,而是使用配对的语音范例,其中一个片段代表原始声音,另一个片段说明所需的转换。该模型学习将相同的转换应用于新的输入,从而实现声音纹理的操控。我们构建了一个四元组数据集,代表各种编辑任务,并以自监督的方式训练了一个潜在扩散模型。通过定量评估和感知研究表明,我们的模型优于文本条件基线,并推广到真实世界、分布外和非语音场景。
🔬 方法详解
问题定义:论文旨在解决音频纹理操控的问题,即如何修改声音的感知特性以实现特定的转换。现有方法通常依赖于文本指令,但文本描述难以捕捉声音的细微差别和风格,导致操控效果不佳,且泛化能力有限。
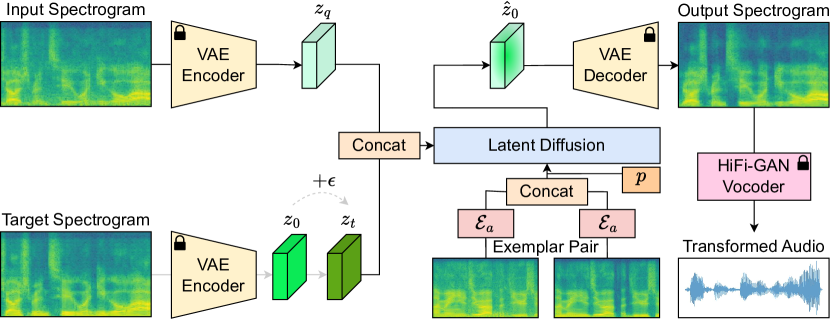
核心思路:论文的核心思路是利用范例类比。通过提供一对配对的语音样本(原始声音和目标声音),模型学习两者之间的转换关系。这种方法避免了对声音特征进行显式建模,而是直接学习从一个声音纹理到另一个声音纹理的映射。
技术框架:整体框架包含以下步骤:1) 构建一个四元组数据集,包含原始声音、目标声音以及其他相关的声音片段。2) 使用自监督学习的方式训练一个潜在扩散模型。该模型学习将原始声音映射到目标声音的潜在空间表示,并能够根据配对样本的类比关系,将新的输入声音转换到相应的目标声音。
关键创新:最重要的创新点在于使用范例类比来指导音频纹理操控。与传统的文本条件方法相比,该方法能够更精确地控制声音的转换,并且具有更好的泛化能力。此外,使用潜在扩散模型能够生成更加自然和逼真的音频。
关键设计:论文构建了一个四元组数据集,用于训练模型。数据集包含各种编辑任务,例如添加、删除或替换听觉元素。模型采用潜在扩散模型,通过自监督学习的方式进行训练。具体的损失函数和网络结构等技术细节在论文中进行了详细描述(具体细节未知)。
🖼️ 关键图片

📊 实验亮点
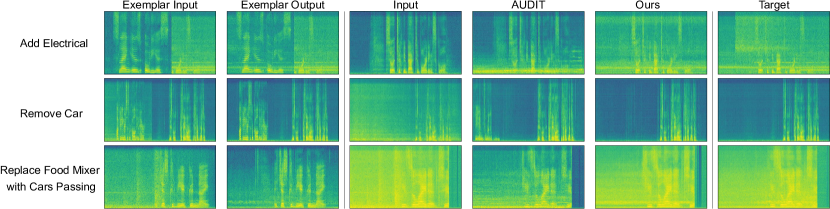
实验结果表明,该模型在各种音频编辑任务上优于文本条件基线。定量评估和感知研究都表明,该模型能够生成更加自然和逼真的音频,并且具有更好的泛化能力。该模型还能够推广到真实世界、分布外和非语音场景,例如动物叫声和环境声音。
🎯 应用场景
该研究成果可应用于音频编辑、音乐创作、语音增强等领域。例如,可以用于将一种乐器的声音转换为另一种乐器的声音,或者将一种环境的声音添加到另一种环境中。该技术还可以用于语音增强,例如去除背景噪声或口音转换。未来,该技术有望在虚拟现实、游戏和电影等领域得到广泛应用。
📄 摘要(原文)
Audio texture manipulation involves modifying the perceptual characteristics of a sound to achieve specific transformations, such as adding, removing, or replacing auditory elements. In this paper, we propose an exemplar-based analogy model for audio texture manipulation. Instead of conditioning on text-based instructions, our method uses paired speech examples, where one clip represents the original sound and another illustrates the desired transformation. The model learns to apply the same transformation to new input, allowing for the manipulation of sound textures. We construct a quadruplet dataset representing various editing tasks, and train a latent diffusion model in a self-supervised manner. We show through quantitative evaluations and perceptual studies that our model outperforms text-conditioned baselines and generalizes to real-world, out-of-distribution, and non-speech scenarios. Project page: https://berkeley-speech-group.github.io/audio-texture-analogy/