FOCUS: First Order Concentrated Updating Scheme
作者: Yizhou Liu, Ziming Liu, Jeff Gore
分类: cs.LG, cs.CL, math.OC
发布日期: 2025-01-21
备注: 19 pages, 8 figures
💡 一句话要点
提出FOCUS优化器,提升LLM在梯度噪声下的训练稳定性和速度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 优化器 大型语言模型 梯度噪声 Signum Adam 预训练 深度学习 移动平均
📋 核心要点
- 现有Adam优化器在梯度噪声较高时,由于步长衰减过快,性能会显著下降,限制了大型语言模型的训练效果。
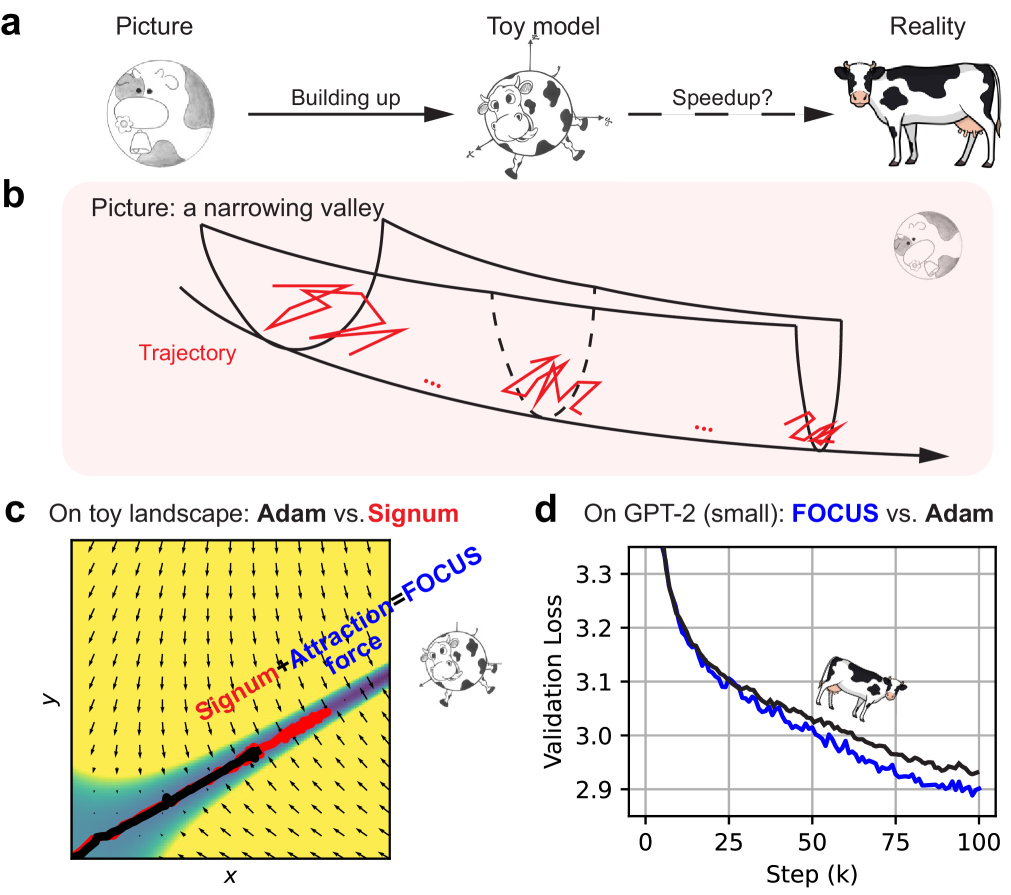
- FOCUS优化器通过引入对移动平均参数的吸引力,增强了Signum优化器,从而在保持较大步长的同时,更好地处理梯度噪声。
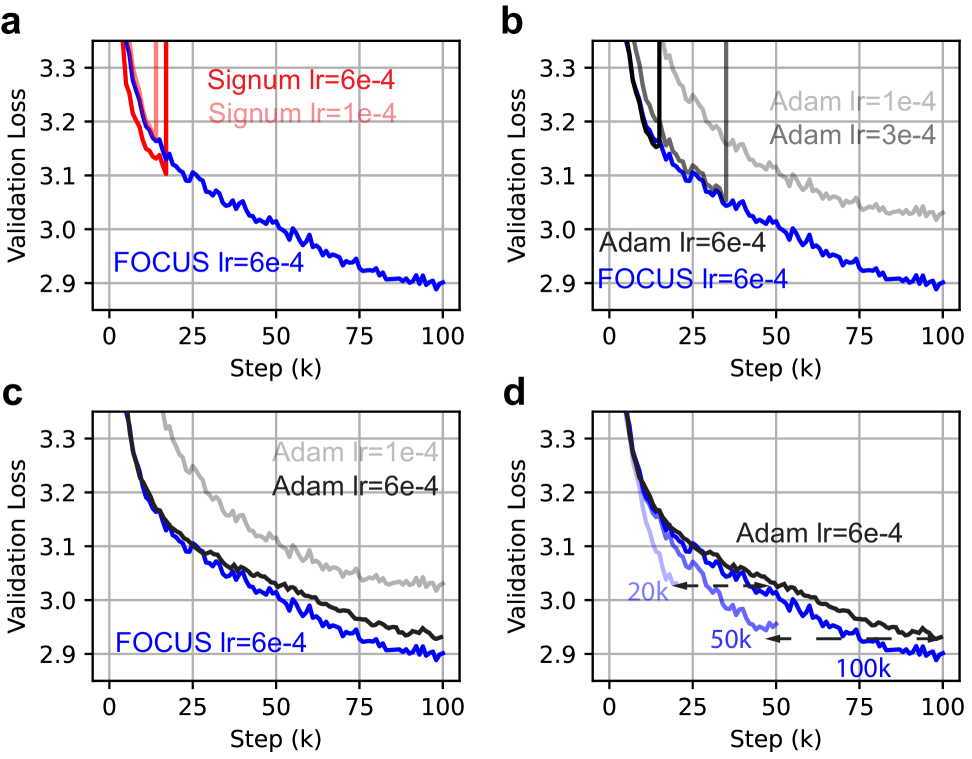
- 实验表明,在GPT-2的训练中,FOCUS优化器比Signum更稳定,比Adam更快,验证了其在噪声环境下的有效性。
📝 摘要(中文)
大型语言模型(LLM)展现了卓越的性能,而改进其预训练过程似乎是进一步提升其能力的关键。基于Adam、学习率衰减和权重衰减的成功经验,我们假设预训练损失面呈现出狭窄的峡谷结构。通过合成损失函数的实验,我们发现当梯度查询噪声相对于峡谷的锐度较高时,Adam的性能会落后于Signum,因为Adam过度降低了有效步长。基于此,我们开发了FOCUS优化器,它通过引入对移动平均参数的吸引力来增强Signum,使其能够更好地处理噪声,同时保持更大的步长。在GPT-2的训练中,FOCUS被证明比Signum更稳定,比Adam更快。这些结果表明,梯度噪声可能是LLM训练中一个被低估的限制因素,而FOCUS提供了一个有希望的解决方案。
🔬 方法详解
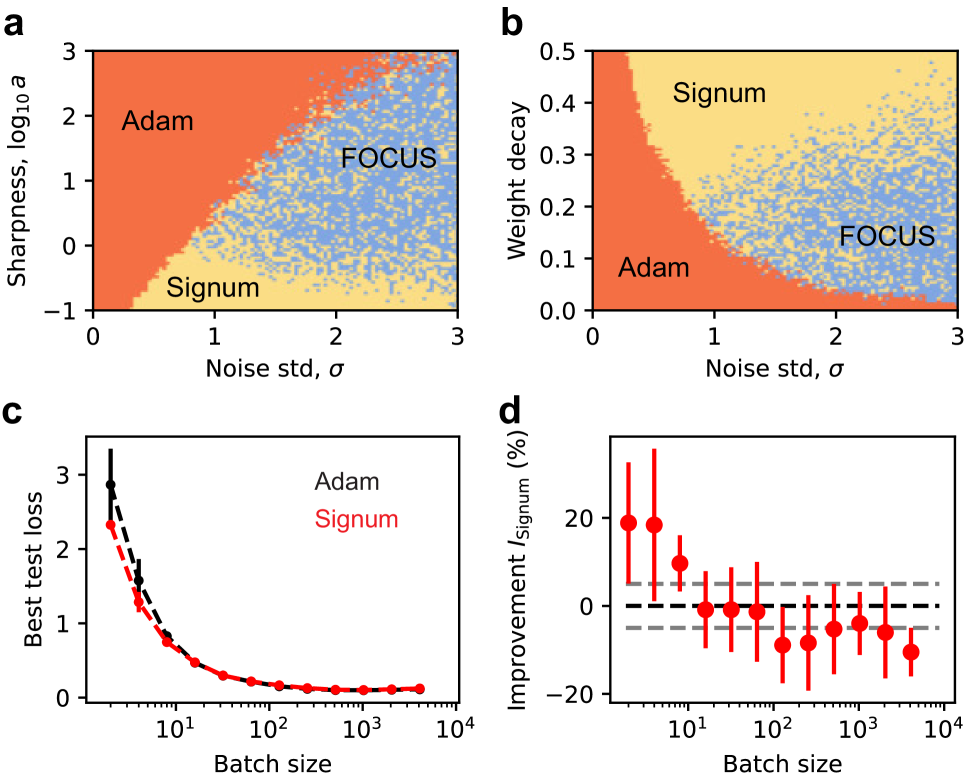
问题定义:论文旨在解决大型语言模型(LLM)预训练过程中,由于梯度噪声的存在,导致现有优化器(如Adam)性能下降的问题。尤其是在损失面呈现狭窄峡谷结构时,高梯度噪声会使得Adam的步长衰减过快,从而影响模型的收敛速度和最终性能。Signum虽然对噪声具有一定的鲁棒性,但稳定性较差。
核心思路:论文的核心思路是设计一种新的优化器,能够在高梯度噪声环境下保持较大的步长,同时保证训练的稳定性。FOCUS优化器通过引入对移动平均参数的吸引力,增强了Signum优化器,使其能够在噪声环境下更好地探索损失面,并加速收敛。
技术框架:FOCUS优化器的整体框架基于Signum优化器,并在此基础上进行了改进。其主要流程如下:1) 计算梯度;2) 使用Signum函数对梯度进行符号化;3) 计算移动平均参数;4) 将符号化的梯度与移动平均参数之间的差异作为吸引力项;5) 将吸引力项添加到更新方向中;6) 更新模型参数。
关键创新:FOCUS优化器的关键创新在于引入了对移动平均参数的吸引力项。这一项的作用是引导优化器向历史参数的平均方向移动,从而提高对噪声的鲁棒性,并保持较大的步长。与Adam等自适应学习率优化器不同,FOCUS的步长不是基于梯度的方差进行调整,而是基于移动平均参数的吸引力进行调整,因此能够更好地适应高噪声环境。
关键设计:FOCUS优化器的关键设计包括:1) 移动平均参数的计算方式,可以使用指数移动平均(EMA)或其他移动平均方法;2) 吸引力项的权重,需要根据具体问题进行调整,以平衡噪声鲁棒性和收敛速度;3) 符号化梯度的实现方式,可以使用Signum函数或其他符号化函数。论文中具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
论文通过在GPT-2模型上的实验证明了FOCUS优化器的有效性。实验结果表明,FOCUS优化器比Signum更稳定,比Adam更快。具体的性能提升数据未知,但结果表明FOCUS在LLM训练中具有显著优势,尤其是在梯度噪声较大的情况下。
🎯 应用场景
FOCUS优化器具有广泛的应用前景,尤其适用于训练大型语言模型等需要处理高梯度噪声的任务。它可以提高模型的训练速度和稳定性,从而降低训练成本,并提升模型的最终性能。此外,该优化器还可以应用于其他深度学习任务,例如图像识别、语音识别等,以提高模型在噪声环境下的鲁棒性。
📄 摘要(原文)
Large language models (LLMs) demonstrate remarkable performance, and improving their pre-training process appears to be key to enhancing their capabilities further. Based on the documented success of Adam, learning rate decay, and weight decay, we hypothesize that the pre-training loss landscape features a narrowing valley structure. Through experiments with synthetic loss functions, we discover that when gradient query noise is high relative to the valley's sharpness, Adam's performance falls behind that of Signum because Adam reduces the effective step size too drastically. This observation led us to develop FOCUS, an optimizer that enhances Signum by incorporating attraction toward moving averaged parameters, allowing it to handle noise better while maintaining larger step sizes. In training GPT-2, FOCUS proves to be more stable than Signum and faster than Adam. These results suggest that gradient noise may be an underappreciated limiting factor in LLM training, and FOCUS offers promising solutions.