Evaluating Binary Decision Biases in Large Language Models: Implications for Fair Agent-Based Financial Simulations
作者: Alicia Vidler, Toby Walsh
分类: cs.LG, cs.AI
发布日期: 2025-01-20
备注: 8 pages
💡 一句话要点
评估大语言模型中的二元决策偏差,及其对公平的基于Agent金融模拟的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 二元决策 偏差评估 金融市场建模 Agent-Based模型
📋 核心要点
- 现有基于Agent的金融模型(ABM)越来越多地使用LLM模拟人类决策,但LLM固有的偏差可能影响ABM的公平性和准确性。
- 该研究通过一次性和少样本API查询,评估了不同GPT模型在二元决策任务中的偏差,并分析了采样方法和模型版本的影响。
- 实验发现不同GPT模型和版本存在显著偏差差异,少样本采样在特定条件下可接近均匀分布,并评估了模型对负近因偏差的抵抗能力。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用于模拟基于Agent的金融市场模型(ABM)中类人的决策。随着模型变得更加强大和易于访问,研究人员现在可以将单个LLM决策整合到ABM环境中。然而,这种整合可能会引入固有的偏差,需要仔细评估。本文使用两种模型采样方法:一次性(one-shot)和少样本(few-shot)API查询,测试了三种最先进的GPT模型的偏差。我们观察到特定模型和模型子版本之间的输出分布存在显著差异,其中GPT-4o-Mini-2024-07-18表现出明显更好的性能(32-43%的“是”响应),而GPT-4-0125-preview则表现出极端的偏差(98-99%的“是”响应)。我们表明,采样方法和模型子版本会显著影响结果:重复独立的API调用会产生与单个调用中的批量采样不同的分布。虽然目前没有GPT模型可以在一次性测试中同时实现均匀分布和马尔可夫性质,但少样本采样可以在某些条件下接近均匀分布。我们探讨了Temperature参数,提供了定义和比较结果。我们进一步将我们的结果与真正的随机二元序列进行比较,并专门测试了常见的负近因偏差(Negative Recency)——发现LLM在这方面具有“击败”人类的混合能力。这些发现强调了在将LLM整合到金融市场ABM以及更广泛的领域时,进行仔细评估的关键重要性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在二元决策任务中存在的偏差,这些偏差可能影响基于Agent的金融市场模型(ABM)的公平性和准确性。现有方法缺乏对LLM偏差的系统性评估,并且没有充分考虑不同采样方法和模型版本的影响。
核心思路:论文的核心思路是通过设计一系列二元决策任务,利用一次性(one-shot)和少样本(few-shot)API查询,系统地评估不同GPT模型及其子版本在这些任务中的偏差。通过比较不同模型和采样方法的结果,揭示LLM在二元决策中的潜在偏差,并探讨如何减轻这些偏差。
技术框架:该研究的技术框架主要包括以下几个阶段:1)选择代表性的GPT模型及其子版本;2)设计二元决策任务,例如生成随机二进制序列;3)使用一次性和少样本API查询方法,从LLM中采样二元决策结果;4)分析采样结果的分布,评估模型的偏差;5)比较不同模型和采样方法的结果,揭示偏差的来源;6)探讨Temperature参数对结果的影响;7)将结果与真实随机二进制序列进行比较,并测试模型对负近因偏差的抵抗能力。
关键创新:该研究的关键创新在于:1)系统性地评估了不同GPT模型及其子版本在二元决策任务中的偏差;2)揭示了采样方法(一次性 vs. 少样本)和模型版本对偏差的显著影响;3)探讨了Temperature参数对结果的影响;4)将LLM的决策行为与真实随机序列和人类行为进行比较,评估其在特定偏差(如负近因偏差)方面的表现。
关键设计:关键设计包括:1)使用两种采样方法(一次性和少样本)来评估模型的偏差;2)使用Temperature参数来控制模型的随机性;3)设计特定的二元决策任务,例如生成随机二进制序列,以便评估模型的偏差;4)使用统计方法来分析采样结果的分布,并评估模型的偏差。
🖼️ 关键图片
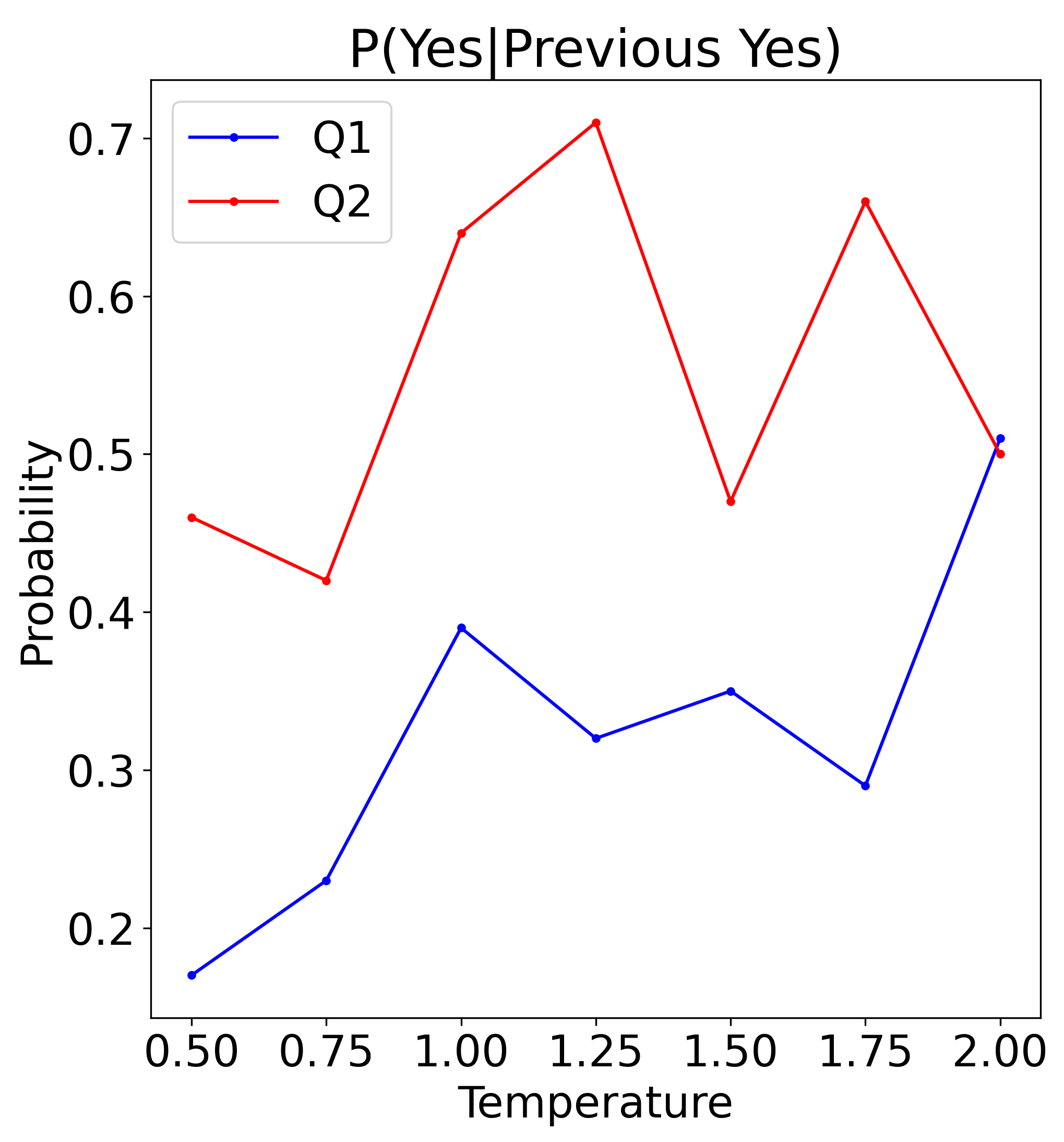
📊 实验亮点
实验结果表明,不同GPT模型和子版本在二元决策任务中存在显著偏差差异。例如,GPT-4o-Mini-2024-07-18的“是”响应比例为32-43%,而GPT-4-0125-preview则高达98-99%。少样本采样在特定条件下可以接近均匀分布。研究还发现,LLM在抵抗负近因偏差方面表现出混合能力,部分模型甚至优于人类。
🎯 应用场景
该研究成果可应用于金融市场建模、社会行为模拟、以及其他需要使用LLM进行决策模拟的领域。通过了解和减轻LLM的偏差,可以提高这些模型的公平性、准确性和可靠性,从而为政策制定和风险管理提供更可靠的依据。未来的研究可以进一步探索如何利用LLM来纠正人类决策中的偏差。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly being used to simulate human-like decision making in agent-based financial market models (ABMs). As models become more powerful and accessible, researchers can now incorporate individual LLM decisions into ABM environments. However, integration may introduce inherent biases that need careful evaluation. In this paper we test three state-of-the-art GPT models for bias using two model sampling approaches: one-shot and few-shot API queries. We observe significant variations in distributions of outputs between specific models, and model sub versions, with GPT-4o-Mini-2024-07-18 showing notably better performance (32-43% yes responses) compared to GPT-4-0125-preview's extreme bias (98-99% yes responses). We show that sampling methods and model sub-versions significantly impact results: repeated independent API calls produce different distributions compared to batch sampling within a single call. While no current GPT model can simultaneously achieve a uniform distribution and Markovian properties in one-shot testing, few-shot sampling can approach uniform distributions under certain conditions. We explore the Temperature parameter, providing a definition and comparative results. We further compare our results to true random binary series and test specifically for the common human bias of Negative Recency - finding LLMs have a mixed ability to 'beat' humans in this one regard. These findings emphasise the critical importance of careful LLM integration into ABMs for financial markets and more broadly.