Can Bayesian Neural Networks Make Confident Predictions?
作者: Katharine Fisher, Youssef Marzouk
分类: stat.ML, cs.LG, math.ST
发布日期: 2025-01-20
备注: Mathematics of Modern Machine Learning Workshop at NeurIPS 2024
💡 一句话要点
提出基于离散先验的贝叶斯神经网络,精确量化预测不确定性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 贝叶斯神经网络 不确定性量化 离散先验 高斯混合模型 后验推断 预测多模态 模型缩放
📋 核心要点
- 贝叶斯神经网络面临后验分布难以刻画和预测分布可解释性差的挑战。
- 论文提出在离散先验下,后验预测分布可精确表示为高斯混合模型,便于分析。
- 研究识别出预测多模态的场景,并评估模型在不同缩放机制下的学习能力。
📝 摘要(中文)
贝叶斯推断为神经网络预测提供了一个原则性的不确定性量化框架。然而,全面刻画网络参数的后验分布以及后验预测分布的可解释性是应用该框架的障碍。本文证明,在内层权重采用离散先验的情况下,我们可以将后验预测分布精确地表征为高斯混合模型。这种设置允许我们定义产生相同似然(训练误差)的网络参数值的等价类,并将这些类的元素与网络的缩放机制联系起来,缩放机制通过训练样本大小、每层大小和最终层参数数量的比率来定义。特别令人感兴趣的是,不同的参数实现对应于低训练误差,但对应于后验预测分布中的不同模式。我们识别出表现出这种预测多模态的设置,从而深入了解单峰后验近似的准确性。我们还通过评估不同缩放机制中后验预测的收缩来表征模型“从数据中学习”的能力。
🔬 方法详解
问题定义:贝叶斯神经网络旨在提供神经网络预测的置信度估计,但由于后验分布的复杂性,难以准确量化预测的不确定性。现有方法通常采用近似推断,可能导致对不确定性的错误估计,尤其是在模型缩放和数据量变化时。
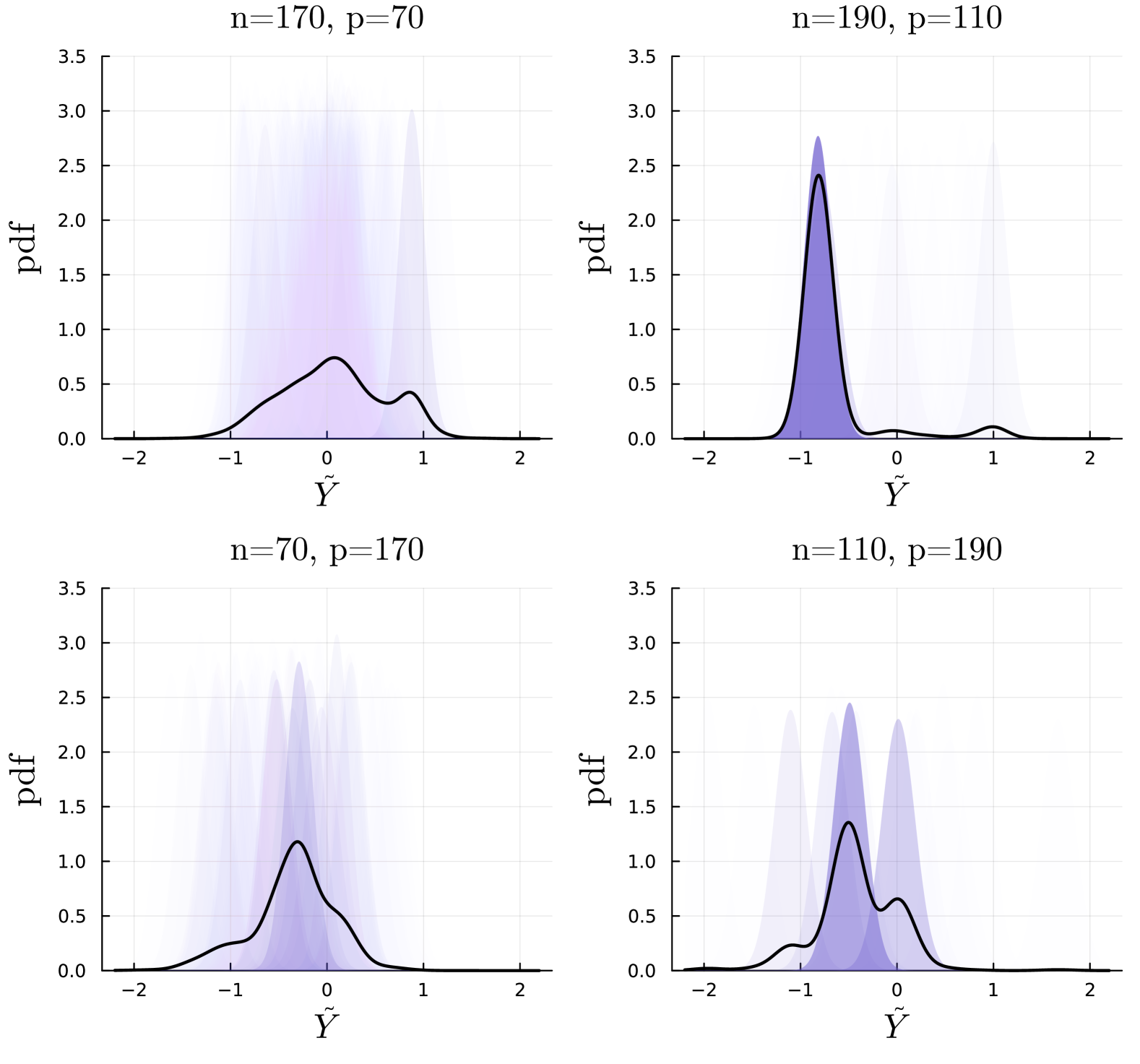
核心思路:论文的核心思路是在神经网络的内层权重上施加离散先验。通过这种方式,可以将后验预测分布精确地表示为高斯混合模型。这种表示形式允许研究人员分析不同参数配置对预测分布的影响,并识别导致预测多模态的参数配置。
技术框架:该方法主要包含以下几个步骤:1) 定义具有离散先验的贝叶斯神经网络;2) 基于训练数据计算后验分布;3) 将后验预测分布表示为高斯混合模型;4) 分析高斯混合模型的各个成分,识别导致预测多模态的参数配置;5) 评估模型在不同缩放机制下的后验收缩情况。
关键创新:该方法最重要的创新点在于使用离散先验简化了后验分布的计算,使得可以精确地表征后验预测分布。与现有方法中常用的变分推断或马尔可夫链蒙特卡洛方法相比,该方法避免了近似误差,提供了更准确的不确定性估计。
关键设计:关键设计包括:1) 选择合适的离散先验,确保能够覆盖参数空间的重要区域;2) 设计有效的算法来计算后验分布和高斯混合模型的参数;3) 定义合适的指标来评估预测多模态和后验收缩情况。论文中,网络的缩放机制通过训练样本大小、每层大小和最终层参数数量的比率来定义,这些比率影响着模型的学习能力和泛化性能。
🖼️ 关键图片


📊 实验亮点
论文通过实验识别出导致预测多模态的参数配置,并深入分析了单峰后验近似的局限性。此外,论文还评估了模型在不同缩放机制下的学习能力,为贝叶斯神经网络的设计和应用提供了有价值的见解。
🎯 应用场景
该研究成果可应用于对预测置信度要求较高的领域,例如自动驾驶、医疗诊断和金融风险评估。通过准确量化神经网络预测的不确定性,可以提高决策的可靠性和安全性,并为模型改进提供指导。
📄 摘要(原文)
Bayesian inference promises a framework for principled uncertainty quantification of neural network predictions. Barriers to adoption include the difficulty of fully characterizing posterior distributions on network parameters and the interpretability of posterior predictive distributions. We demonstrate that under a discretized prior for the inner layer weights, we can exactly characterize the posterior predictive distribution as a Gaussian mixture. This setting allows us to define equivalence classes of network parameter values which produce the same likelihood (training error) and to relate the elements of these classes to the network's scaling regime -- defined via ratios of the training sample size, the size of each layer, and the number of final layer parameters. Of particular interest are distinct parameter realizations that map to low training error and yet correspond to distinct modes in the posterior predictive distribution. We identify settings that exhibit such predictive multimodality, and thus provide insight into the accuracy of unimodal posterior approximations. We also characterize the capacity of a model to "learn from data" by evaluating contraction of the posterior predictive in different scaling regimes.