Secure Resource Allocation via Constrained Deep Reinforcement Learning
作者: Jianfei Sun, Qiang Gao, Cong Wu, Yuxian Li, Jiacheng Wang, Dusit Niyato
分类: cs.LG
发布日期: 2025-01-20
💡 一句话要点
提出SARMTO框架,通过约束深度强化学习实现安全高效的多云边缘资源分配
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 资源分配 边缘计算 多云环境 安全机制 物联网 约束优化
📋 核心要点
- 现有资源分配方案难以应对多云环境的复杂性、安全集成以及约束条件下深度强化学习的应用。
- SARMTO框架通过集成动作约束的深度强化学习模型,动态平衡资源分配、任务卸载、安全性和性能。
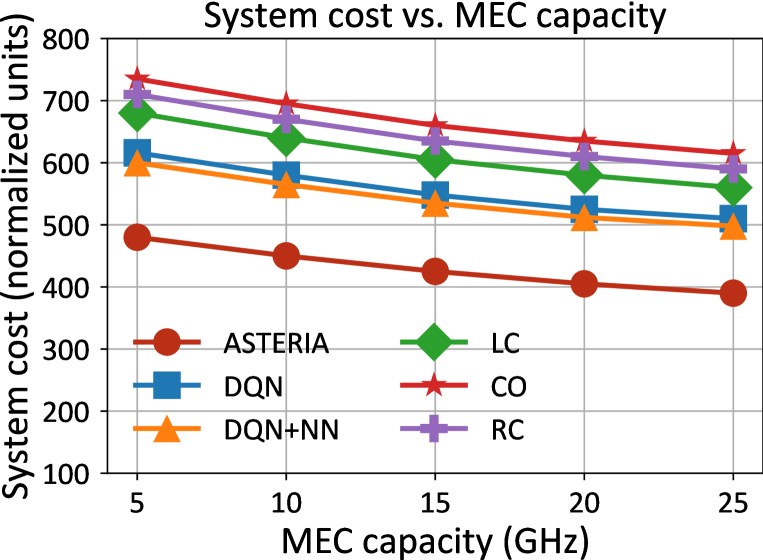
- 实验结果表明,SARMTO在系统成本和能源效率方面显著优于现有方法,提升分别高达40%和41.5%。
📝 摘要(中文)
本文提出SARMTO框架,旨在解决serverless多云边缘计算环境中资源分配的安全和效率问题。面对物联网设备激增和6G技术发展带来的计算密集型任务挑战,现有方案难以有效应对多云基础设施的复杂性、安全集成以及传统深度强化学习在约束条件下的应用。SARMTO集成了动作约束的深度强化学习模型,通过马尔可夫决策过程、自适应安全机制和优化技术,动态平衡资源分配、任务卸载、安全性和性能。仿真结果表明,在不同任务负载、数据大小和MEC容量下,SARMTO优于五个基线方法,系统成本降低高达40%,能源效率提高41.5%。该框架有望革新复杂分布式计算环境中的资源管理,促进更高效、安全的物联网和边缘计算应用。
🔬 方法详解
问题定义:论文旨在解决serverless多云边缘计算环境中安全且高效的资源分配问题。现有方法在处理复杂的多云基础设施、集成强大的安全机制以及在系统约束下应用传统的深度强化学习(DRL)技术时面临挑战。这些挑战导致资源利用率低下、安全风险增加以及整体系统性能下降。
核心思路:论文的核心思路是利用动作约束的深度强化学习(DRL)模型,在满足系统约束的前提下,动态地优化资源分配策略。通过将资源分配问题建模为马尔可夫决策过程(MDP),并引入自适应安全机制,SARMTO能够平衡资源利用率、安全性和性能。这种设计旨在克服传统DRL方法在复杂和受限环境中的局限性。
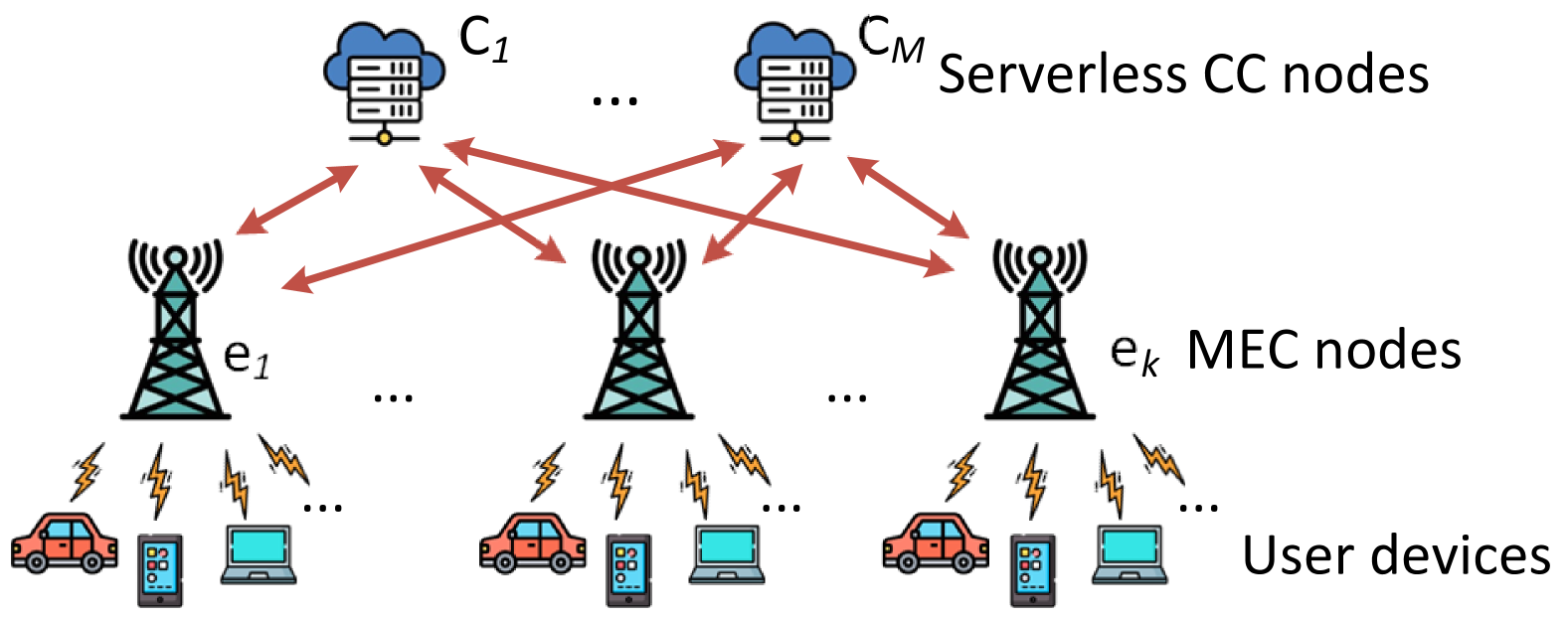
技术框架:SARMTO框架包含以下主要模块:1) 环境建模:将多云边缘计算环境建模为马尔可夫决策过程,定义状态空间、动作空间和奖励函数。2) 动作约束模块:实施安全策略和资源限制,约束DRL代理的动作选择。3) DRL代理:使用深度神经网络学习最优的资源分配策略。4) 自适应安全机制:根据系统状态动态调整安全参数,以应对潜在的安全威胁。整体流程是DRL代理根据当前状态选择动作,环境执行动作并返回新的状态和奖励,代理根据奖励更新策略,直到收敛。
关键创新:SARMTO的关键创新在于集成了动作约束的DRL模型和自适应安全机制。传统的DRL方法通常忽略了系统约束和安全因素,导致在实际应用中性能下降。SARMTO通过显式地约束动作空间,确保资源分配策略满足安全要求和资源限制。自适应安全机制能够根据环境变化动态调整安全参数,提高系统的鲁棒性。
关键设计:SARMTO使用深度Q网络(DQN)作为DRL代理,并引入了动作约束层,该层根据预定义的安全策略过滤掉不安全的动作。奖励函数的设计考虑了资源利用率、任务完成时间和安全成本。自适应安全机制通过监控系统状态和检测异常行为来调整安全参数,例如访问控制策略和加密强度。具体的网络结构和参数设置(如学习率、折扣因子等)未知,可能在论文的实验部分有更详细的描述。
🖼️ 关键图片
📊 实验亮点
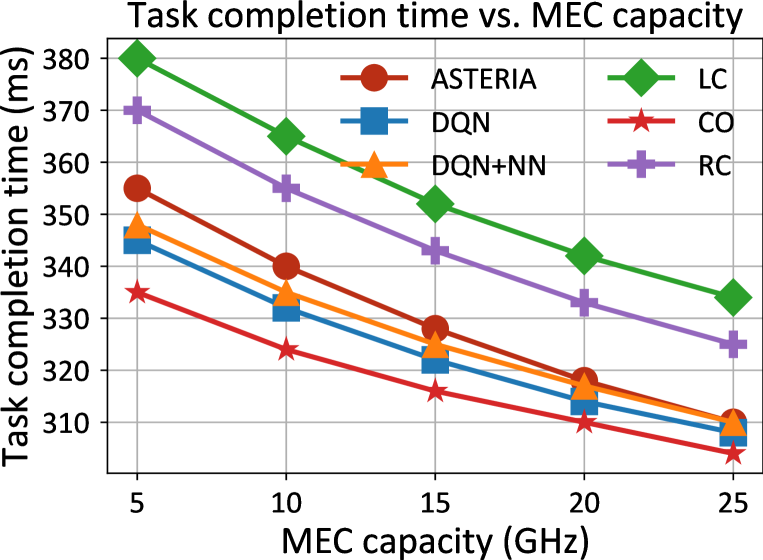
实验结果表明,SARMTO在不同任务负载、数据大小和MEC容量下均优于五个基线方法。SARMTO能够实现高达40%的系统成本降低和41.5%的能源效率提升。这些显著的性能提升验证了SARMTO在复杂分布式计算环境中的有效性。
🎯 应用场景
SARMTO框架可广泛应用于物联网、边缘计算和云计算等领域,尤其适用于需要高安全性和资源效率的场景,如智能交通、工业自动化、智慧城市等。通过优化资源分配,SARMTO能够降低系统成本、提高能源效率,并增强系统的安全性,从而推动分布式计算的发展和应用。
📄 摘要(原文)
The proliferation of Internet of Things (IoT) devices and the advent of 6G technologies have introduced computationally intensive tasks that often surpass the processing capabilities of user devices. Efficient and secure resource allocation in serverless multi-cloud edge computing environments is essential for supporting these demands and advancing distributed computing. However, existing solutions frequently struggle with the complexity of multi-cloud infrastructures, robust security integration, and effective application of traditional deep reinforcement learning (DRL) techniques under system constraints. To address these challenges, we present SARMTO, a novel framework that integrates an action-constrained DRL model. SARMTO dynamically balances resource allocation, task offloading, security, and performance by utilizing a Markov decision process formulation, an adaptive security mechanism, and sophisticated optimization techniques. Extensive simulations across varying scenarios, including different task loads, data sizes, and MEC capacities, show that SARMTO consistently outperforms five baseline approaches, achieving up to a 40% reduction in system costs and a 41.5% improvement in energy efficiency over state-of-the-art methods. These enhancements highlight SARMTO's potential to revolutionize resource management in intricate distributed computing environments, opening the door to more efficient and secure IoT and edge computing applications.