Multimodal Techniques for Malware Classification
作者: Jonathan Jiang, Mark Stamp
分类: cs.CR, cs.LG
发布日期: 2025-01-19
💡 一句话要点
提出基于多模态机器学习的恶意软件分类方法,提升Windows PE文件恶意软件检测精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 恶意软件分类 多模态学习 Windows PE文件 支持向量机 长短期记忆网络 卷积神经网络 特征提取
📋 核心要点
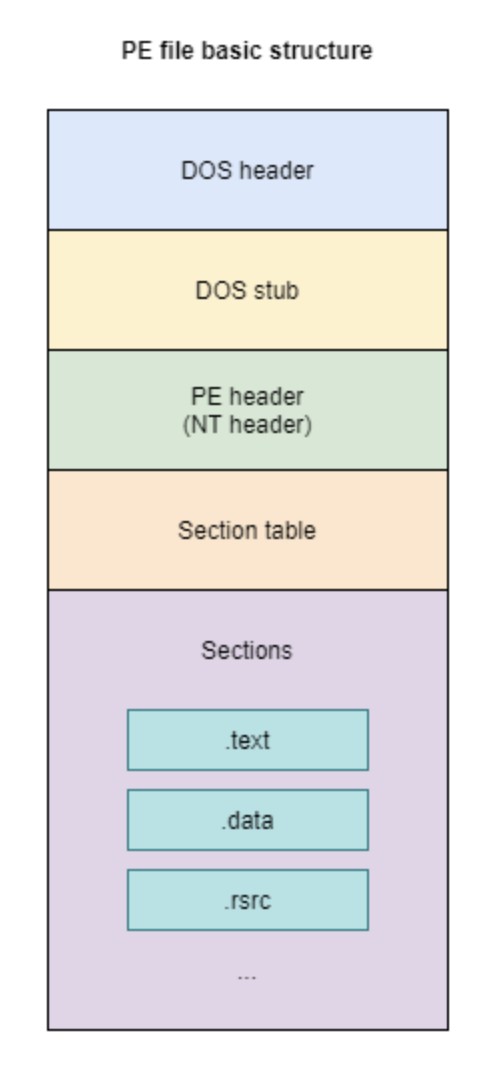
- 现有恶意软件分类方法在处理复杂的PE文件结构时存在局限性,难以充分利用不同区域的信息。
- 该论文提出一种多模态机器学习方法,通过分别训练PE文件的不同部分,然后进行组合,从而更全面地提取特征。
- 实验结果表明,多模态模型优于基线模型,验证了该方法在恶意软件分类中的有效性。
📝 摘要(中文)
恶意软件对计算机网络和系统构成严重威胁,精确的分类技术至关重要。本研究探索了基于Windows PE文件结构的多模态机器学习方法用于恶意软件分类。具体而言,我们分别在PE头、PE文件其他节区以及整个PE文件上训练支持向量机(SVM)、长短期记忆网络(LSTM)和卷积神经网络(CNN)模型。然后,我们使用这些基线模型的输出层概率作为特征向量,训练SVM模型来组合九种头部-节区组合。我们将多模态组合与基线情况进行比较。实验结果表明,最佳多模态模型优于最佳基线模型,证明了对Windows PE文件的不同部分训练单独模型具有优势。
🔬 方法详解
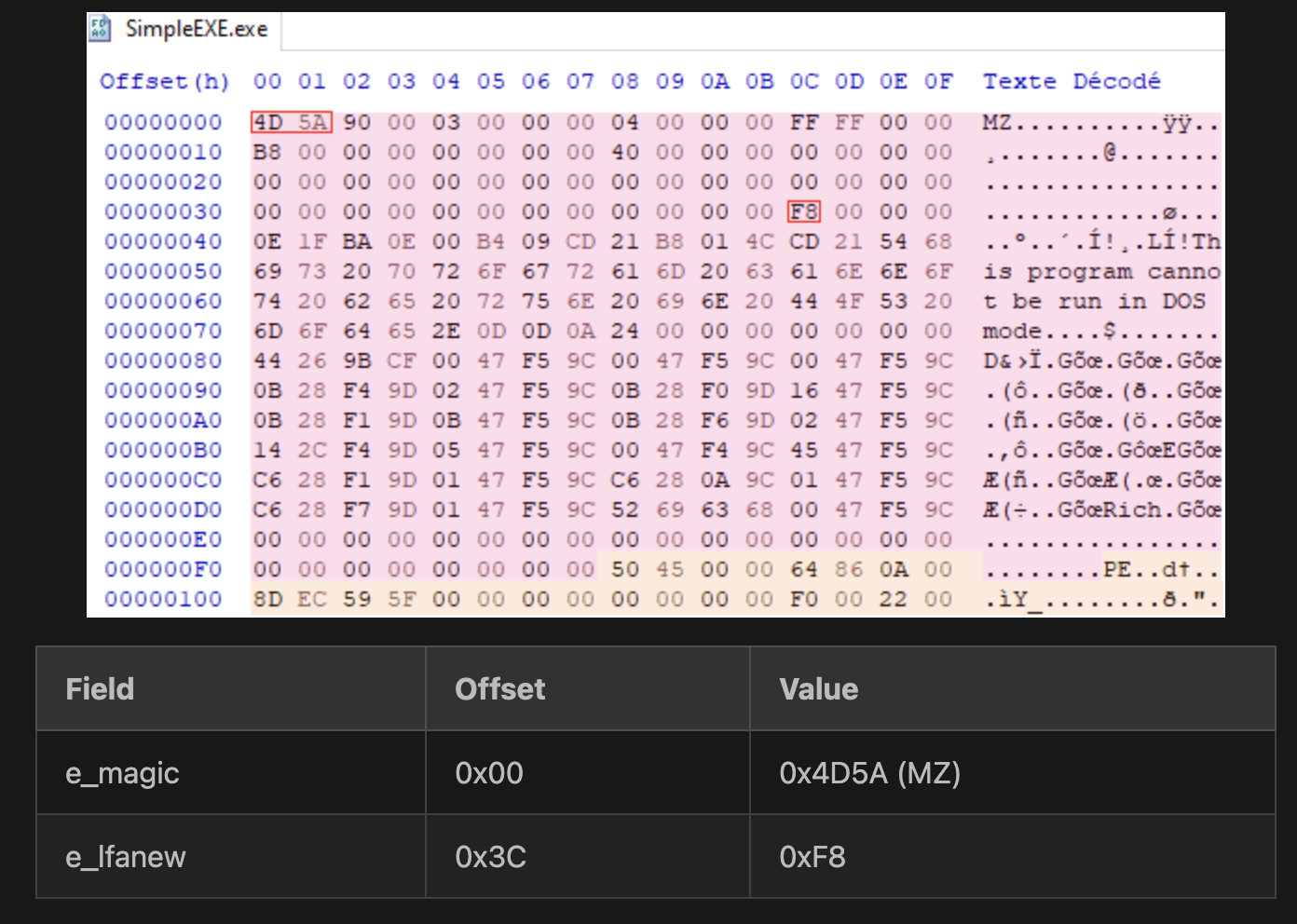
问题定义:论文旨在解决恶意软件分类的准确性问题,特别是针对Windows PE文件。现有方法可能无法充分利用PE文件的结构化信息,例如PE头和不同节区包含的不同类型的数据。这些方法可能无法有效地捕捉恶意软件隐藏在特定区域的特征,导致分类性能下降。
核心思路:论文的核心思路是将PE文件视为一个多模态数据源,其中PE头和不同的节区代表不同的模态。通过分别训练每个模态,可以更有效地提取特定于该模态的特征。然后,将这些特征组合起来,以获得更全面的恶意软件表示。这种方法能够更好地利用PE文件的结构化信息,从而提高分类准确性。
技术框架:整体框架包括以下几个阶段:1) 特征提取:从PE头、PE文件的其他节区以及整个PE文件中提取特征。2) 基线模型训练:在每个特征集上训练SVM、LSTM和CNN模型。3) 多模态组合:使用基线模型的输出层概率作为特征向量,训练SVM模型来组合不同的头部-节区组合。4) 性能评估:比较基线模型和多模态模型的分类性能。
关键创新:该论文的关键创新在于将多模态学习应用于恶意软件分类,并针对PE文件的结构特点设计了特定的组合策略。通过分别训练PE文件的不同部分,并使用基线模型的输出概率进行组合,可以更有效地利用PE文件的结构化信息,从而提高分类准确性。
关键设计:论文中使用了三种不同的机器学习模型(SVM、LSTM和CNN)作为基线模型,以捕捉不同类型的特征。此外,论文还探索了不同的头部-节区组合策略,以找到最佳的多模态组合方式。具体参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,最佳的多模态模型优于最佳的基线模型,证明了对Windows PE文件的不同部分训练单独模型具有优势。具体的性能提升幅度未知,但该结果表明多模态方法在恶意软件分类方面具有潜力。该研究为恶意软件分类提供了一种新的思路,并为未来的研究奠定了基础。
🎯 应用场景
该研究成果可应用于网络安全领域,用于提高恶意软件检测系统的准确性和效率。通过更精确地识别恶意软件,可以有效保护计算机系统和网络免受恶意软件的侵害。该方法还可以用于开发新型的恶意软件分析工具,帮助安全研究人员更好地理解恶意软件的行为和特征。
📄 摘要(原文)
The threat of malware is a serious concern for computer networks and systems, highlighting the need for accurate classification techniques. In this research, we experiment with multimodal machine learning approaches for malware classification, based on the structured nature of the Windows Portable Executable (PE) file format. Specifically, we train Support Vector Machine (SVM), Long Short-Term Memory (LSTM), and Convolutional Neural Network (CNN) models on features extracted from PE headers, we train these same models on features extracted from the other sections of PE files, and train each model on features extracted from the entire PE file. We then train SVM models on each of the nine header-sections combinations of these baseline models, using the output layer probabilities of the component models as feature vectors. We compare the baseline cases to these multimodal combinations. In our experiments, we find that the best of the multimodal models outperforms the best of the baseline cases, indicating that it can be advantageous to train separate models on distinct parts of Windows PE files.