Learn-by-interact: A Data-Centric Framework for Self-Adaptive Agents in Realistic Environments
作者: Hongjin Su, Ruoxi Sun, Jinsung Yoon, Pengcheng Yin, Tao Yu, Sercan Ö. Arık
分类: cs.LG, cs.AI
发布日期: 2025-01-18
💡 一句话要点
Learn-by-interact:一种数据为中心的框架,用于在真实环境中自适应LLM Agent
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 数据合成 自适应Agent 交互学习 反向构建
📋 核心要点
- 现有LLM Agent缺乏高质量的交互数据,限制了其在真实环境中的能力。
- Learn-by-interact通过合成Agent与环境的交互轨迹,并反向构建指令,生成高质量训练数据。
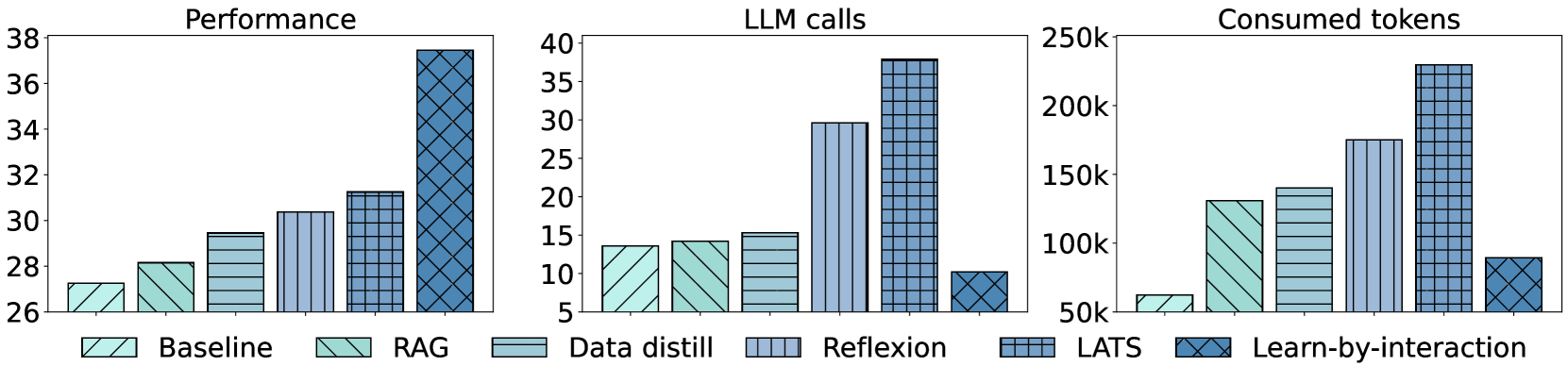
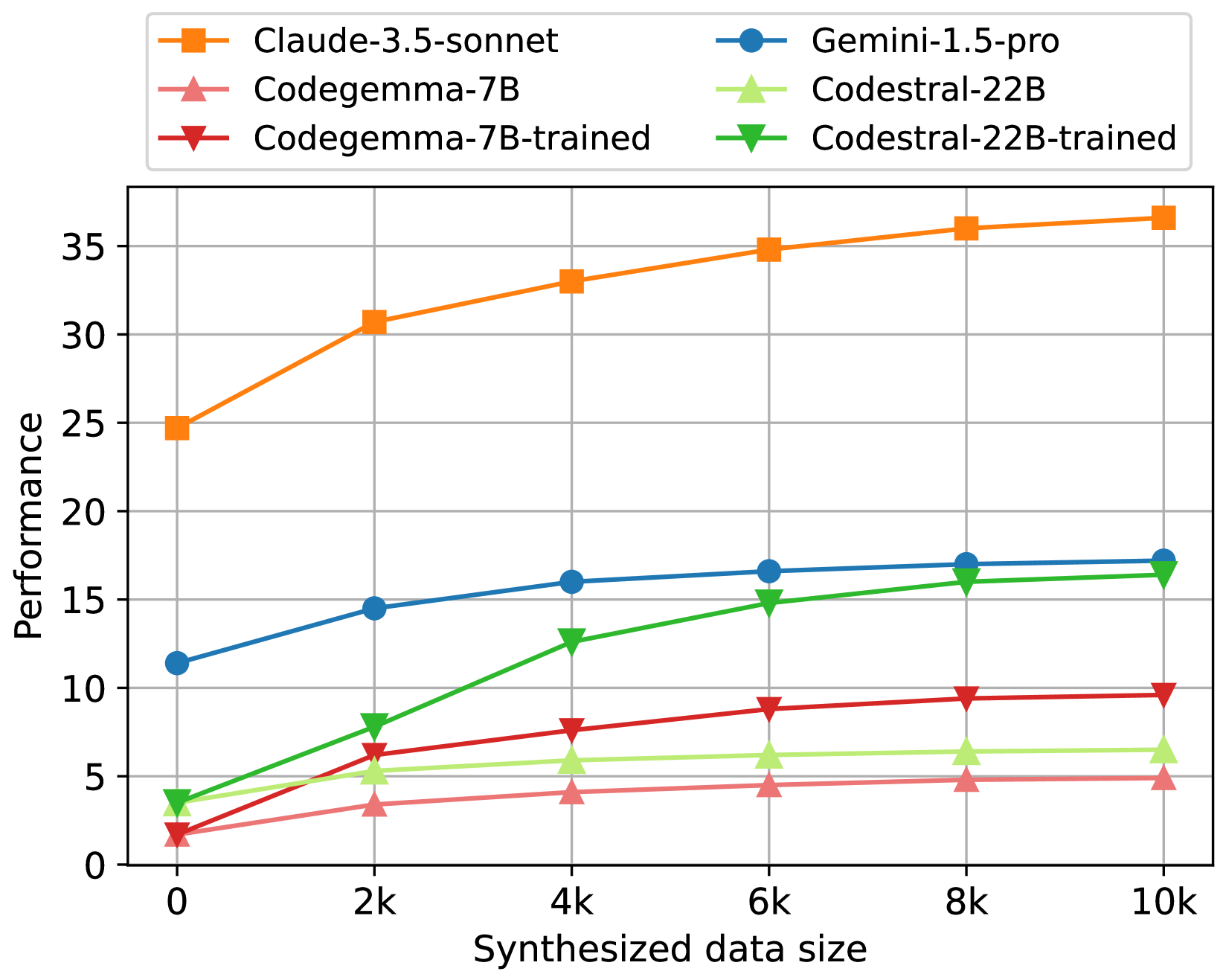
- 实验表明,该方法在多个真实环境中显著提升了LLM Agent的性能,最高提升达19.5%。
📝 摘要(中文)
本文提出Learn-by-interact,一个以数据为中心的框架,用于使LLM Agent适应任何给定的环境,无需人工标注。Learn-by-interact基于文档合成Agent与环境交互的轨迹,并通过总结或抽象交互历史来构建指令,这个过程称为反向构建。通过在基于训练和无训练的上下文学习(ICL)中使用合成数据来评估其质量,并设计了针对Agent优化的创新检索方法。在SWE-bench、WebArena、OSWorld和Spider2-V等涵盖真实编码、Web和桌面环境的广泛实验表明,Learn-by-interact在各种下游Agent任务中有效,使用Claude-3.5的ICL结果提高了高达12.2%,使用Codestral-22B的训练结果提高了19.5%。反向构建至关重要,训练效果提升高达14.0%。消融研究表明,合成数据在ICL中效率很高,并且检索管道优于传统的RAG。Learn-by-interact将为Agent数据合成奠定基础,因为LLM越来越多地部署在真实环境中。
🔬 方法详解
问题定义:现有的大语言模型(LLM)Agent在执行复杂任务时,往往受限于缺乏高质量的、来自真实交互环境的数据。人工标注成本高昂且难以覆盖所有场景,导致Agent难以适应各种实际应用环境。因此,如何高效地生成高质量的Agent交互数据,成为提升LLM Agent能力的关键挑战。
核心思路:Learn-by-interact的核心思路是通过模拟Agent与环境的交互过程,自动生成训练数据。该方法利用环境的文档信息,合成Agent的交互轨迹,并采用“反向构建”的方式,从交互历史中提取指令。这种方法避免了人工标注的成本,并能够生成多样化的、高质量的训练数据。
技术框架:Learn-by-interact框架主要包含两个阶段:交互轨迹合成和反向构建。首先,利用环境的文档信息,模拟Agent与环境的交互过程,生成交互轨迹。然后,通过总结或抽象交互历史,构建指令。这些指令与交互轨迹一起,构成训练数据。此外,论文还设计了针对Agent优化的检索方法,用于在上下文学习(ICL)中选择合适的示例。
关键创新:Learn-by-interact的关键创新在于“反向构建”方法。传统的指令生成方法通常是正向的,即先设计指令,然后让Agent执行。而Learn-by-interact采用反向的方式,先生成交互轨迹,然后从轨迹中提取指令。这种方法能够更好地捕捉Agent与环境的交互模式,生成更自然的、更符合实际情况的指令。
关键设计:在交互轨迹合成阶段,需要设计合适的策略来模拟Agent的行为。在反向构建阶段,需要选择合适的总结或抽象方法来提取指令。论文中具体使用的参数设置、损失函数、网络结构等技术细节未知。
🖼️ 关键图片

📊 实验亮点
Learn-by-interact在SWE-bench、WebArena、OSWorld和Spider2-V等多个数据集上进行了评估,实验结果表明,该方法能够显著提升LLM Agent的性能。例如,在使用Claude-3.5进行上下文学习时,性能提升高达12.2%;在使用Codestral-22B进行训练时,性能提升高达19.5%。此外,反向构建方法也带来了显著的性能提升,最高可达14.0%。
🎯 应用场景
Learn-by-interact框架可广泛应用于各种需要自主Agent的领域,例如自动化办公、智能家居、软件开发和数据分析等。通过自动生成高质量的训练数据,该方法能够显著降低Agent的开发成本,并提升Agent在真实环境中的适应性和性能,加速LLM Agent在实际场景中的落地。
📄 摘要(原文)
Autonomous agents powered by large language models (LLMs) have the potential to enhance human capabilities, assisting with digital tasks from sending emails to performing data analysis. The abilities of existing LLMs at such tasks are often hindered by the lack of high-quality agent data from the corresponding environments they interact with. We propose Learn-by-interact, a data-centric framework to adapt LLM agents to any given environments without human annotations. Learn-by-interact synthesizes trajectories of agent-environment interactions based on documentations, and constructs instructions by summarizing or abstracting the interaction histories, a process called backward construction. We assess the quality of our synthetic data by using them in both training-based scenarios and training-free in-context learning (ICL), where we craft innovative retrieval approaches optimized for agents. Extensive experiments on SWE-bench, WebArena, OSWorld and Spider2-V spanning across realistic coding, web, and desktop environments show the effectiveness of Learn-by-interact in various downstream agentic tasks -- baseline results are improved by up to 12.2\% for ICL with Claude-3.5 and 19.5\% for training with Codestral-22B. We further demonstrate the critical role of backward construction, which provides up to 14.0\% improvement for training. Our ablation studies demonstrate the efficiency provided by our synthesized data in ICL and the superiority of our retrieval pipeline over alternative approaches like conventional retrieval-augmented generation (RAG). We expect that Learn-by-interact will serve as a foundation for agent data synthesis as LLMs are increasingly deployed at real-world environments.