Diffusion-Based Imitation Learning for Social Pose Generation
作者: Antonio Lech Martin-Ozimek, Isuru Jayarathne, Su Larb Mon, Jouh Yeong Chew
分类: cs.LG, cs.RO
发布日期: 2025-01-18
备注: This paper was submitted as an LBR to HRI2025
💡 一句话要点
提出基于扩散模型的模仿学习方法,用于社交场景中人物姿态生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散模型 模仿学习 社交姿态生成 人机交互 行为克隆
📋 核心要点
- 现有方法难以有效表示复杂社交互动中的动态,需要多模态同步观测理解场景。
- 利用扩散行为克隆模型学习和复制社交互动促进者的姿态行为,生成非语言社交线索。
- 评估了两种姿态观测表示方法,分析了性能、计算负载以及准确性和处理时间之间的权衡。
📝 摘要(中文)
本文探讨了如何利用社交互动中多个个体的姿态行为,生成该互动促进者的非语言社交线索。促进者的角色对于智能体在人机交互中至关重要。本文采用了一种现有的扩散行为克隆模型,学习并复制促进者的行为。此外,评估了场景中姿态观测的两种表示方法,一种经过预处理,另一种未经过预处理。本文旨在为社交互动中的姿态生成引入一种新的扩散行为克隆用途,并理解使用两种不同的场景观测收集技术生成社交姿态行为时,性能与计算负载之间的关系。本质上,本文测试了扩散模型的两种不同类型的条件作用的有效性。然后,使用平均关节位置误差(MPJPE)、训练时间和推理时间等定量指标评估每种技术生成的行为。结果表明,经过进一步预处理的数据可以成功地调节扩散模型,以生成逼真的社交行为,并在准确性和处理时间之间取得合理的权衡。
🔬 方法详解
问题定义:论文旨在解决智能体(如机器人或虚拟代理)在社交互动中如何生成合适的姿态,以扮演“促进者”角色的问题。现有方法通常需要多模态信息,计算复杂度高,且难以捕捉社交互动的细微动态。论文关注仅使用姿态信息生成社交行为,降低了对多模态数据的依赖。
核心思路:论文的核心思路是利用扩散模型强大的生成能力,通过模仿学习的方式,让智能体学习人类促进者在社交互动中的姿态行为。扩散模型能够生成多样化的姿态,更符合社交互动的多模态特性。通过行为克隆,智能体可以直接从人类示范数据中学习。
技术框架:整体框架包括数据收集、姿态表示、扩散模型训练和姿态生成四个主要阶段。首先,收集社交互动场景中的人物姿态数据。然后,使用两种不同的方法表示姿态信息:一种是原始姿态数据,另一种是经过预处理的姿态数据。接下来,使用这些姿态表示作为条件,训练扩散模型。最后,在新的社交场景中,利用训练好的扩散模型生成促进者的姿态。
关键创新:论文的关键创新在于将扩散模型应用于社交姿态生成任务,并探索了不同姿态表示方法对生成效果的影响。与传统的生成模型相比,扩散模型能够生成更加逼真和多样化的社交姿态。此外,论文还分析了预处理对扩散模型性能的影响,为实际应用提供了指导。
关键设计:论文使用了扩散行为克隆模型,具体实现细节未知。关键设计包括:1) 姿态表示方法:论文比较了原始姿态数据和预处理后的姿态数据,预处理方法未知。2) 扩散模型结构:具体网络结构未知,但应包含噪声预测模块和采样模块。3) 损失函数:使用MPJPE(平均关节位置误差)作为评估指标,可能也将其作为训练损失的一部分。4) 训练参数:训练轮数、学习率等参数未知。
🖼️ 关键图片
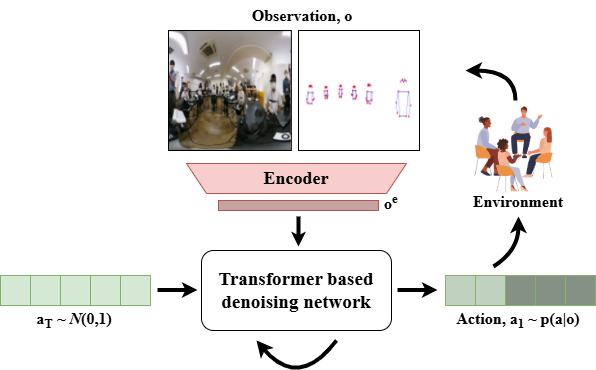
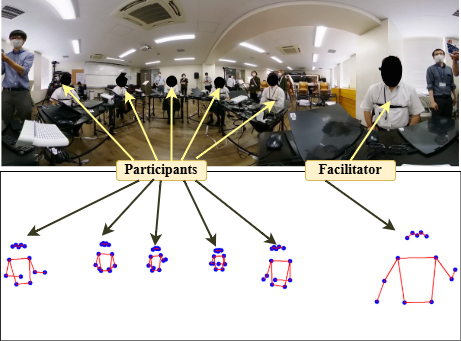
📊 实验亮点
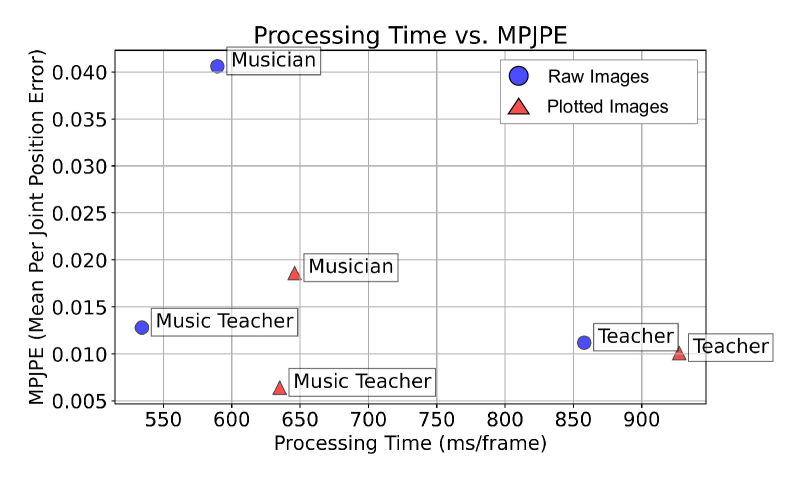
实验结果表明,经过预处理的数据可以成功地调节扩散模型,生成逼真的社交行为。论文对比了两种姿态表示方法的性能,并分析了训练时间和推理时间与MPJPE之间的权衡。具体性能数据未知,但结果表明,在准确性和处理时间之间存在合理的权衡。
🎯 应用场景
该研究成果可应用于人机交互、社交机器人、虚拟现实等领域。例如,在社交机器人中,可以利用该方法生成自然的姿态,提高机器人的社交能力。在虚拟现实中,可以生成虚拟角色的姿态,增强用户的沉浸感。此外,该方法还可以用于分析和理解人类社交行为。
📄 摘要(原文)
Intelligent agents, such as robots and virtual agents, must understand the dynamics of complex social interactions to interact with humans. Effectively representing social dynamics is challenging because we require multi-modal, synchronized observations to understand a scene. We explore how using a single modality, the pose behavior, of multiple individuals in a social interaction can be used to generate nonverbal social cues for the facilitator of that interaction. The facilitator acts to make a social interaction proceed smoothly and is an essential role for intelligent agents to replicate in human-robot interactions. In this paper, we adapt an existing diffusion behavior cloning model to learn and replicate facilitator behaviors. Furthermore, we evaluate two representations of pose observations from a scene, one representation has pre-processing applied and one does not. The purpose of this paper is to introduce a new use for diffusion behavior cloning for pose generation in social interactions. The second is to understand the relationship between performance and computational load for generating social pose behavior using two different techniques for collecting scene observations. As such, we are essentially testing the effectiveness of two different types of conditioning for a diffusion model. We then evaluate the resulting generated behavior from each technique using quantitative measures such as mean per-joint position error (MPJPE), training time, and inference time. Additionally, we plot training and inference time against MPJPE to examine the trade-offs between efficiency and performance. Our results suggest that the further pre-processed data can successfully condition diffusion models to generate realistic social behavior, with reasonable trade-offs in accuracy and processing time.