4bit-Quantization in Vector-Embedding for RAG
作者: Taehee Jeong
分类: cs.LG, cs.AI
发布日期: 2025-01-17
🔗 代码/项目: GITHUB
💡 一句话要点
提出RAG中向量嵌入的4比特量化方法,降低内存占用并加速搜索。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 向量嵌入 量化 4比特量化 内存压缩 向量检索
📋 核心要点
- 大型语言模型存在信息过时和产生幻觉的问题,检索增强生成(RAG)旨在通过检索相关文档来缓解这些问题。
- 该论文提出使用4比特量化来压缩RAG中高维向量嵌入,从而显著降低内存占用,并加速向量搜索过程。
- 实验结果未知,但理论上该方法可以在资源受限的环境中更高效地部署RAG系统,并提升检索速度。
📝 摘要(中文)
检索增强生成(RAG)是一种很有前景的技术,它在解决大型语言模型(LLM)的一些局限性方面显示出了巨大的潜力。LLM有两个主要的局限性:它们可能包含由于其训练数据而导致的过时信息,并且它们可能生成不准确的回复,这种现象被称为幻觉。RAG旨在通过利用相关文档数据库来缓解这些问题,这些文档作为嵌入向量存储在高维空间中。然而,使用高维嵌入的一个挑战是它们需要大量的内存来存储。当处理大型文档数据库时,这可能是一个主要问题。为了缓解这个问题,我们建议使用4比特量化来存储嵌入向量。这包括将向量的精度从32位浮点数降低到4位整数,这可以显著降低内存需求。我们的方法有几个好处。首先,它显著降低了高维向量数据库的内存存储需求,使得在资源受限的环境中部署RAG系统更加可行。其次,它加快了搜索过程,因为向量的精度降低允许更快的计算。我们的代码可在https://github.com/taeheej/4bit-Quantization-in-Vector-Embedding-for-RAG获得。
🔬 方法详解
问题定义:RAG系统依赖于存储在高维向量空间中的文档嵌入。这些高维嵌入需要大量的内存空间,尤其是在处理大规模文档数据库时,这限制了RAG系统在资源受限环境中的部署。现有方法通常采用32位浮点数来表示这些向量,存在冗余。
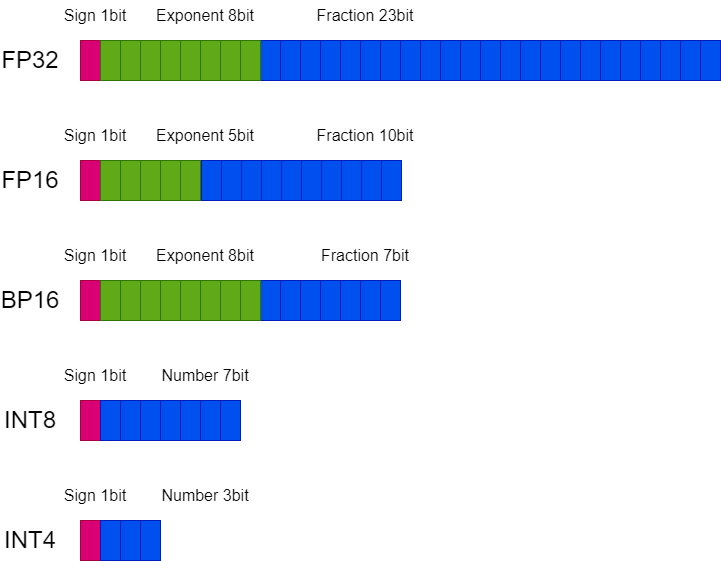
核心思路:核心思路是通过量化来降低向量嵌入的精度,从而减少存储空间。具体而言,将32位浮点数向量量化为4位整数向量。虽然精度降低,但大幅减少了内存占用,并且理论上可以加速向量相似度计算。
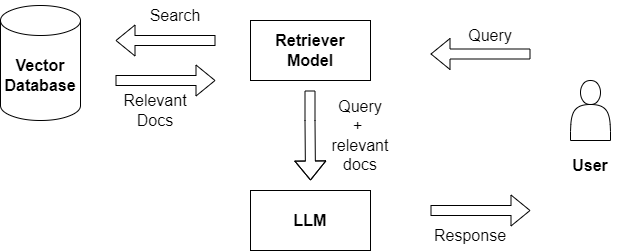
技术框架:该方法主要包含一个量化模块,将原始的32位浮点向量转换为4位整数向量。在检索阶段,使用量化后的向量进行相似度搜索。整体流程为:文档编码 -> 向量嵌入 -> 4比特量化 -> 向量存储 -> 检索查询 -> 4比特量化 -> 相似度计算 -> 返回结果。
关键创新:关键创新在于将4比特量化应用于RAG系统的向量嵌入。虽然量化本身不是一个全新的技术,但将其应用于RAG系统,并针对向量检索进行优化,可以有效降低内存占用并提升检索效率。这种方法的优势在于简单有效,易于实现。
关键设计:论文中没有详细说明量化的具体方法(例如,是否使用均匀量化、非均匀量化或矢量量化),也没有提及任何特定的损失函数或网络结构。关键设计在于如何选择合适的量化策略,以在精度损失和存储空间之间取得平衡。具体的参数设置和量化算法的选择将直接影响最终的检索性能。
🖼️ 关键图片

📊 实验亮点
由于论文中没有提供具体的实验结果,因此无法总结实验亮点。但是,该方法理论上可以显著降低RAG系统中向量数据库的内存占用,并加速向量检索过程。具体的性能提升幅度取决于量化策略的选择和数据集的特性,需要在实际应用中进行评估。
🎯 应用场景
该研究成果可广泛应用于各种需要大规模文档检索的RAG系统中,尤其是在资源受限的边缘设备或移动设备上。例如,可以用于构建轻量级的智能助手、移动端的知识库问答系统等。通过降低内存占用,使得RAG技术能够更广泛地应用。
📄 摘要(原文)
Retrieval-augmented generation (RAG) is a promising technique that has shown great potential in addressing some of the limitations of large language models (LLMs). LLMs have two major limitations: they can contain outdated information due to their training data, and they can generate factually inaccurate responses, a phenomenon known as hallucinations. RAG aims to mitigate these issues by leveraging a database of relevant documents, which are stored as embedding vectors in a high-dimensional space. However, one of the challenges of using high-dimensional embeddings is that they require a significant amount of memory to store. This can be a major issue, especially when dealing with large databases of documents. To alleviate this problem, we propose the use of 4-bit quantization to store the embedding vectors. This involves reducing the precision of the vectors from 32-bit floating-point numbers to 4-bit integers, which can significantly reduce the memory requirements. Our approach has several benefits. Firstly, it significantly reduces the memory storage requirements of the high-dimensional vector database, making it more feasible to deploy RAG systems in resource-constrained environments. Secondly, it speeds up the searching process, as the reduced precision of the vectors allows for faster computation. Our code is available at https://github.com/taeheej/4bit-Quantization-in-Vector-Embedding-for-RAG