Enhancing UAV Path Planning Efficiency Through Accelerated Learning
作者: Joseanne Viana, Boris Galkin, Lester Ho, Holger Claussen
分类: cs.LG, cs.AI
发布日期: 2025-01-17
备注: This paper was accepted in https://camad2024.ieee-camad.org/ conference but it is not available from the conference yet
💡 一句话要点
提出基于加速学习的无人机路径规划方法,提升效率并降低存储需求。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无人机路径规划 深度强化学习 主成分分析 TD3算法 优先经验回放
📋 核心要点
- 高分辨率地形图增加了无人机路径规划中深度强化学习的存储需求和收敛时间,是现有方法的挑战。
- 利用主成分分析降维、样本组合、优先经验回放以及混合损失函数,加速TD3算法的收敛。
- 实验结果表明,该方法显著减少了无人机路径规划训练所需的episode数,加速了学习过程。
📝 摘要(中文)
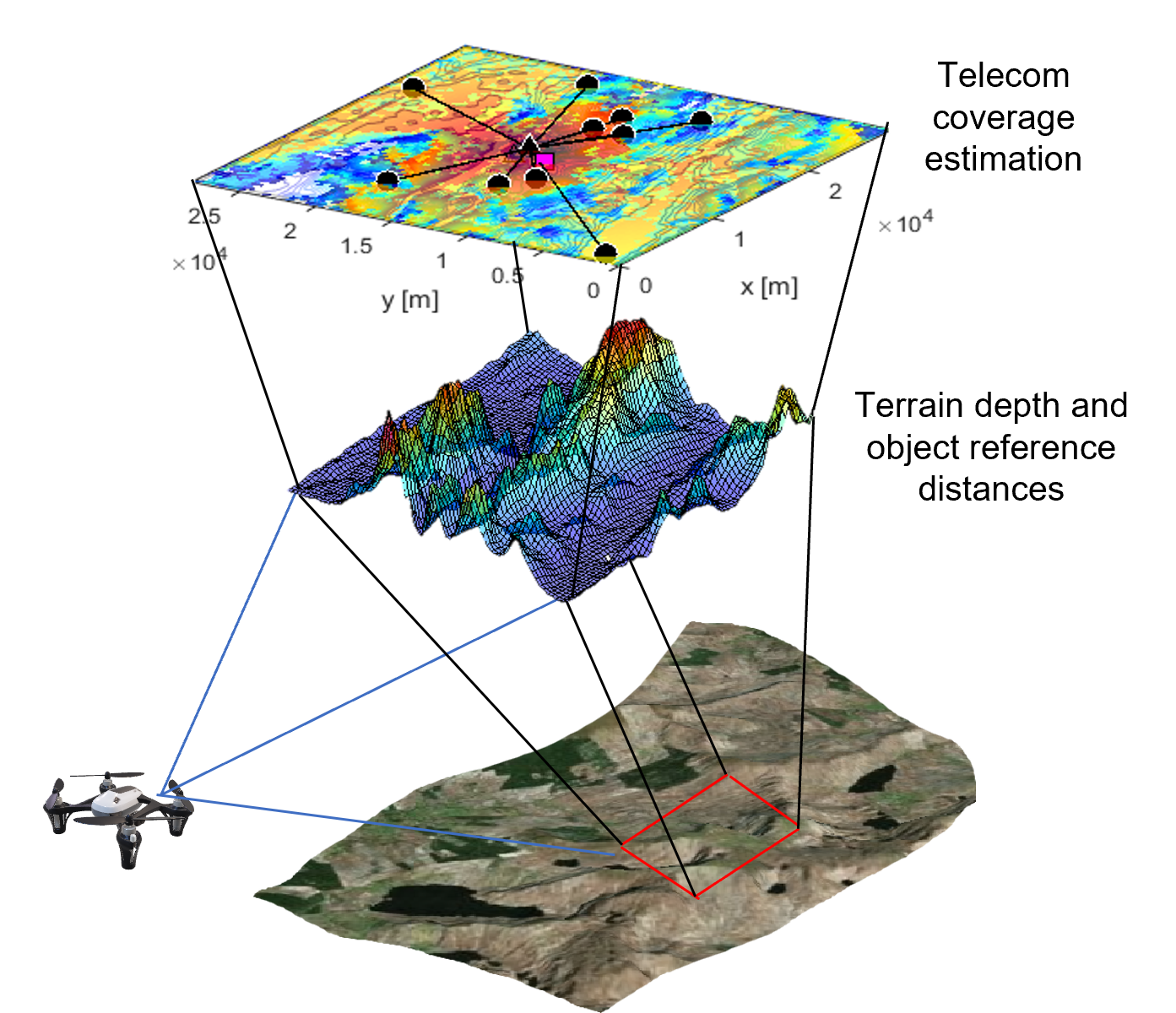
本研究旨在为无人机无线通信中继的路径规划开发一种学习算法,以减少存储需求并加速深度强化学习(DRL)的收敛。假设系统拥有区域地形图,并能利用定位算法或直接GPS报告估计用户位置,则可以将这些参数输入到学习算法中,以实现优化的路径规划性能。然而,为了提取地形高度、物体距离和信号阻挡等拓扑信息,需要更高分辨率的地形图,这增加了无人机的内存和存储需求,同时也延长了DRL算法的收敛时间。类似地,使用这些地形图和用户位置估计来定义无人机无线通信中继的覆盖地图,也需要更高的内存和存储利用率。本研究通过应用基于主成分分析(PCA)的降维技术、样本组合、优先经验回放(PER)以及均方误差(MSE)和平均绝对误差(MAE)损失计算的组合来增强双延迟深度确定性策略梯度(TD3)算法,从而减少路径规划训练时间。所提出的解决方案将基本训练所需的收敛episode数减少了约四倍。
🔬 方法详解
问题定义:论文旨在解决无人机路径规划中,由于高分辨率地形图导致深度强化学习算法收敛速度慢、存储需求大的问题。现有方法在处理复杂环境时,需要大量的训练数据和计算资源,限制了无人机实时路径规划的能力。
核心思路:论文的核心思路是通过降维技术减少输入数据的维度,降低计算复杂度,并结合优先经验回放和混合损失函数来加速深度强化学习的收敛。这样可以在保证路径规划性能的同时,降低对计算资源和存储空间的需求。
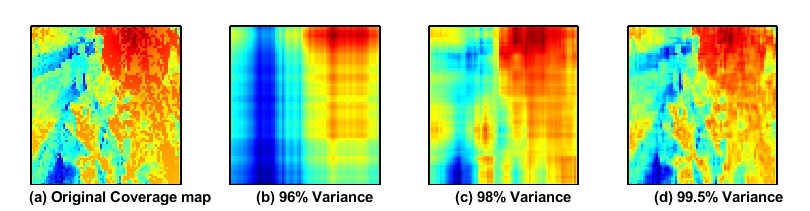
技术框架:整体框架包括以下几个主要步骤:1) 使用地形图和用户位置信息作为输入;2) 利用主成分分析(PCA)进行降维,减少输入数据的维度;3) 使用改进的TD3算法进行训练,其中包含样本组合和优先经验回放机制;4) 使用均方误差(MSE)和平均绝对误差(MAE)的组合作为损失函数,优化覆盖地图的估计。
关键创新:论文的关键创新在于将主成分分析降维技术与深度强化学习相结合,有效地降低了输入数据的维度,从而减少了计算复杂度和存储需求。此外,混合损失函数和优先经验回放机制进一步加速了算法的收敛速度。
关键设计:论文使用了主成分分析(PCA)进行降维,具体降维的维度需要根据实际地形图的复杂度进行调整。损失函数方面,采用了MSE和MAE的组合,通过调整两者的权重来平衡训练的稳定性和准确性。优先经验回放(PER)的优先级计算方式也需要根据具体任务进行调整,以保证重要经验能够被优先学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的方法相比于传统的TD3算法,在无人机路径规划任务中,将基本训练所需的收敛episode数减少了约四倍。这意味着在相同的训练时间内,该方法能够更快地找到最优路径,显著提升了无人机路径规划的效率。
🎯 应用场景
该研究成果可应用于各种需要无人机进行路径规划的场景,例如:环境监测、灾害救援、物流配送、农业巡检等。通过提高路径规划效率和降低资源消耗,可以使无人机在复杂环境中更快速、更有效地完成任务,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Unmanned Aerial Vehicles (UAVs) are increasingly essential in various fields such as surveillance, reconnaissance, and telecommunications. This study aims to develop a learning algorithm for the path planning of UAV wireless communication relays, which can reduce storage requirements and accelerate Deep Reinforcement Learning (DRL) convergence. Assuming the system possesses terrain maps of the area and can estimate user locations using localization algorithms or direct GPS reporting, it can input these parameters into the learning algorithms to achieve optimized path planning performance. However, higher resolution terrain maps are necessary to extract topological information such as terrain height, object distances, and signal blockages. This requirement increases memory and storage demands on UAVs while also lengthening convergence times in DRL algorithms. Similarly, defining the telecommunication coverage map in UAV wireless communication relays using these terrain maps and user position estimations demands higher memory and storage utilization for the learning path planning algorithms. Our approach reduces path planning training time by applying a dimensionality reduction technique based on Principal Component Analysis (PCA), sample combination, Prioritized Experience Replay (PER), and the combination of Mean Squared Error (MSE) and Mean Absolute Error (MAE) loss calculations in the coverage map estimates, thereby enhancing a Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. The proposed solution reduces the convergence episodes needed for basic training by approximately four times compared to the traditional TD3.