PaSa: An LLM Agent for Comprehensive Academic Paper Search
作者: Yichen He, Guanhua Huang, Peiyuan Feng, Yuan Lin, Yuchen Zhang, Hang Li, Weinan E
分类: cs.IR, cs.LG
发布日期: 2025-01-17 (更新: 2025-05-27)
🔗 代码/项目: GITHUB
💡 一句话要点
PaSa:基于LLM Agent的综合学术论文搜索,显著提升搜索质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 学术论文搜索 强化学习 信息检索 自然语言处理
📋 核心要点
- 现有学术论文搜索方法难以处理复杂查询,需要人工干预进行迭代搜索和筛选。
- PaSa利用LLM作为Agent,自主决策搜索工具调用、论文阅读和参考文献选择,实现端到端搜索。
- 在真实学术查询基准测试中,PaSa显著优于现有方法,包括Google Scholar和GPT-4o等,提升明显。
📝 摘要(中文)
本文介绍了一种名为PaSa的先进论文搜索Agent,它由大型语言模型驱动。PaSa能够自主地进行一系列决策,包括调用搜索工具、阅读论文和选择相关参考文献,最终为复杂的学术查询获得全面而准确的结果。我们使用强化学习和一个合成数据集AutoScholarQuery(包含来自顶级AI会议出版物的3.5万个细粒度学术查询和相应的论文)来优化PaSa。此外,我们开发了一个名为RealScholarQuery的基准,用于收集真实世界的学术查询,以评估PaSa在更真实场景中的性能。尽管在合成数据上训练,PaSa在RealScholarQuery上显著优于现有的基线,包括Google、Google Scholar、使用GPT-4o进行释义查询的Google、ChatGPT(启用搜索的GPT-4o)、GPT-o1和PaSa-GPT-4o(通过提示GPT-4o实现的PaSa)。值得注意的是,PaSa-7B在recall@20和recall@50上分别超过了最佳的基于Google的基线(使用GPT-4o的Google)37.78%和39.90%,并且在recall和precision上分别超过了PaSa-GPT-4o 30.36%和4.25%。模型、数据集和代码可在https://github.com/bytedance/pasa 获取。
🔬 方法详解
问题定义:现有学术论文搜索方法在处理复杂、细粒度的学术查询时,往往需要用户进行多次搜索和筛选,效率低下且容易遗漏关键信息。现有的搜索引擎和基于LLM的搜索方法难以模拟研究人员的迭代式搜索过程,无法有效地整合来自不同来源的信息。
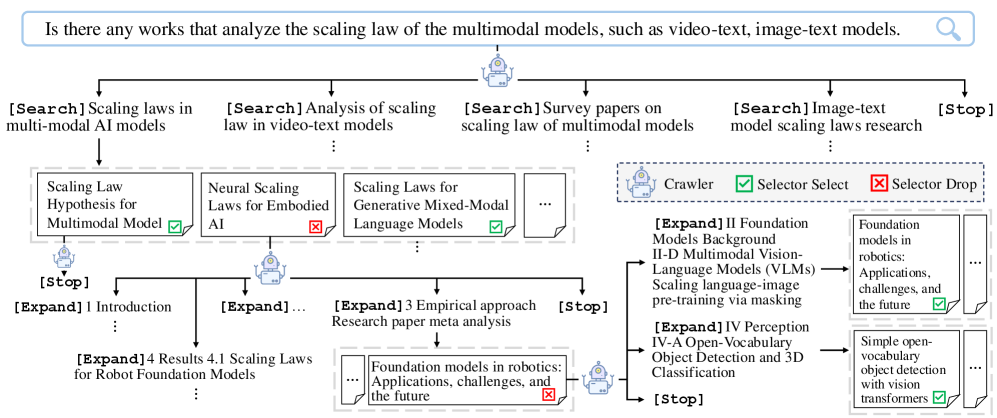
核心思路:PaSa的核心思路是将LLM作为一个智能Agent,赋予其自主决策的能力,使其能够像研究人员一样,根据查询需求,自主地选择合适的搜索工具、阅读相关论文、提取关键信息,并根据已获取的信息迭代搜索,最终获得全面而准确的搜索结果。这种方法模拟了人类研究人员的搜索过程,能够更好地处理复杂的学术查询。
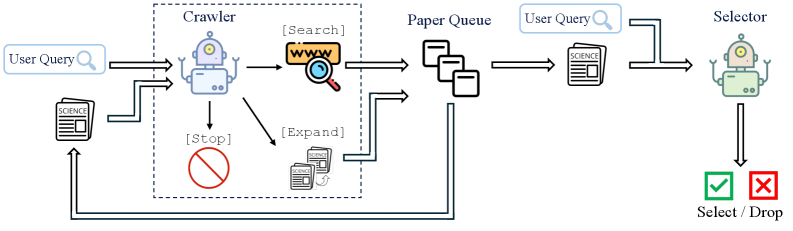
技术框架:PaSa的整体架构包含以下几个主要模块:1) 查询理解模块:负责理解用户输入的学术查询,提取关键信息和搜索意图。2) 搜索工具选择模块:根据查询意图,选择合适的搜索工具,例如Google Scholar、ArXiv等。3) 论文阅读模块:负责阅读搜索结果中的论文,提取关键信息,例如摘要、引言、结论等。4) 参考文献选择模块:根据已阅读论文的信息,选择相关的参考文献,并将其加入搜索范围。5) 迭代搜索模块:根据已获取的信息,迭代进行搜索,直到满足搜索目标。
关键创新:PaSa最重要的技术创新点在于将LLM作为一个智能Agent,赋予其自主决策的能力。与传统的基于关键词的搜索方法相比,PaSa能够更好地理解查询意图,并根据已获取的信息进行迭代搜索。与基于LLM的搜索方法相比,PaSa能够自主地选择搜索工具、阅读论文和选择参考文献,无需人工干预,更加高效和智能。
关键设计:PaSa使用强化学习进行训练,目标是最大化搜索结果的质量和效率。为了训练PaSa,作者构建了一个合成数据集AutoScholarQuery,包含3.5万个细粒度学术查询和相应的论文。此外,作者还开发了一个真实世界的学术查询基准RealScholarQuery,用于评估PaSa在真实场景中的性能。在训练过程中,作者设计了合适的奖励函数,鼓励PaSa选择相关的论文和参考文献,并避免重复搜索。
🖼️ 关键图片

📊 实验亮点
PaSa在RealScholarQuery基准测试中表现出色,PaSa-7B在recall@20和recall@50上分别超过了最佳的基于Google的基线(使用GPT-4o的Google)37.78%和39.90%,并且在recall和precision上分别超过了PaSa-GPT-4o 30.36%和4.25%。这表明PaSa在处理真实学术查询方面具有显著优势。
🎯 应用场景
PaSa可应用于学术研究、科技情报分析、专利检索等领域,帮助研究人员快速准确地获取所需信息,提高科研效率。该研究的未来影响在于推动智能搜索技术的发展,实现更加自动化和智能化的信息获取方式,加速知识发现和创新。
📄 摘要(原文)
We introduce PaSa, an advanced Paper Search agent powered by large language models. PaSa can autonomously make a series of decisions, including invoking search tools, reading papers, and selecting relevant references, to ultimately obtain comprehensive and accurate results for complex scholar queries. We optimize PaSa using reinforcement learning with a synthetic dataset, AutoScholarQuery, which includes 35k fine-grained academic queries and corresponding papers sourced from top-tier AI conference publications. Additionally, we develop RealScholarQuery, a benchmark collecting real-world academic queries to assess PaSa performance in more realistic scenarios. Despite being trained on synthetic data, PaSa significantly outperforms existing baselines on RealScholarQuery, including Google, Google Scholar, Google with GPT-4o for paraphrased queries, ChatGPT (search-enabled GPT-4o), GPT-o1, and PaSa-GPT-4o (PaSa implemented by prompting GPT-4o). Notably, PaSa-7B surpasses the best Google-based baseline, Google with GPT-4o, by 37.78% in recall@20 and 39.90% in recall@50, and exceeds PaSa-GPT-4o by 30.36% in recall and 4.25% in precision. Model, datasets, and code are available at https://github.com/bytedance/pasa.