Accelerating Large Language Models through Partially Linear Feed-Forward Network
作者: Gansen Hu, Zhaoguo Wang, Jinglin Wei, Wei Huang, Haibo Chen
分类: cs.LG, cs.AI
发布日期: 2025-01-17
💡 一句话要点
TARDIS:通过部分线性化前馈网络加速大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型压缩 线性近似 在线预测 推理加速 前馈网络 模型优化
📋 核心要点
- 大型语言模型部署面临参数量大的挑战,现有剪枝方法在高压缩率下精度损失严重。
- TARDIS通过线性函数近似非线性激活,并使用在线预测器处理异常值,实现参数缩减。
- 实验表明,TARDIS在参数缩减的同时,显著提升了精度和推理速度,优于现有剪枝方法。
📝 摘要(中文)
大型语言模型(LLMs)展示了卓越的能力,但由于其庞大的参数量而面临部署挑战。现有的压缩技术(如剪枝)可以减少模型大小,但在高压缩率下会导致显著的精度下降。我们提出了一种受编译器优化中常量折叠启发的全新视角。我们的方法通过将LLM中的激活函数视为线性函数来实现参数缩减。然而,最近的LLM使用复杂的非线性激活函数(如GELU),这阻止了该技术的直接应用。我们提出了TARDIS,它通过在频繁出现的输入范围内用线性函数部分近似非线性激活函数来优化具有非线性激活的LLM。对于异常输入,TARDIS采用在线预测器来动态回退到原始计算。实验表明,TARDIS在前馈网络中实现了80%的参数缩减,同时显著优于最先进的剪枝方法Wanda和RIA,精度提高了高达65%。在7B模型的实际部署中,TARDIS与vLLM服务系统集成时实现了1.6倍的端到端推理加速,与广泛采用的HuggingFace实现集成时实现了1.4倍的加速,而精度损失仅为10.9%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)部署时参数量过大,导致推理速度慢、资源消耗高的难题。现有的模型压缩方法,如剪枝,虽然可以减少参数量,但在高压缩率下会造成显著的精度损失,无法在保证性能的同时实现高效部署。
核心思路:论文的核心思路是受到编译器优化中常量折叠的启发,将LLM中的非线性激活函数在一定范围内近似为线性函数,从而减少计算复杂度和参数量。对于超出线性近似范围的异常值,则采用在线预测器动态回退到原始的非线性计算,以保证精度。这种部分线性化的方法可以在参数缩减和精度保持之间取得平衡。
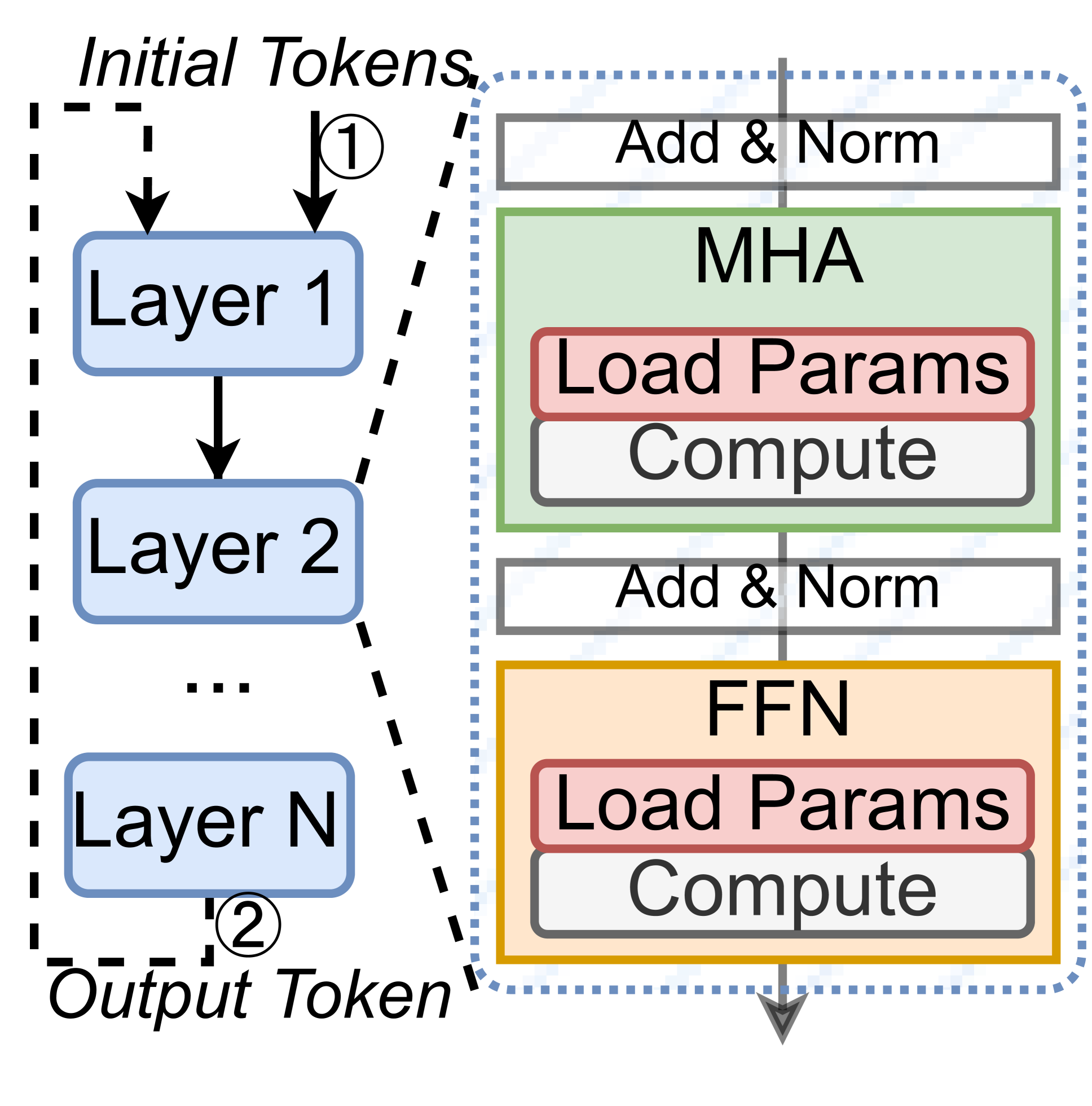
技术框架:TARDIS的核心在于对前馈网络(FFN)中的激活函数进行处理。整体流程如下:1. 线性近似:对激活函数(如GELU)在常见的输入范围内进行线性近似。2. 在线预测器:对于超出线性范围的输入,使用在线预测器判断是否需要回退到原始的非线性计算。3. 动态切换:根据预测器的结果,动态地选择使用线性近似计算或原始的非线性计算。4. 模型训练:通过训练调整线性近似的参数和在线预测器的参数,以优化整体性能。
关键创新:TARDIS的关键创新在于部分线性化的思想,它不同于完全依赖线性近似或完全依赖非线性计算的方法。通过在线预测器动态地选择计算方式,可以在保证精度的前提下,最大限度地利用线性近似带来的加速效果。这种动态切换的机制是TARDIS能够优于传统剪枝方法的核心原因。
关键设计:TARDIS的关键设计包括:1. 线性近似范围的选择:需要根据激活函数的特性和输入数据的分布,选择合适的线性近似范围,以保证近似的精度。2. 在线预测器的设计:预测器需要能够快速准确地判断输入是否超出线性范围,并及时触发回退机制。可以使用简单的阈值判断或更复杂的机器学习模型作为预测器。3. 训练策略:需要设计合适的训练策略,以优化线性近似的参数和在线预测器的参数,并保证整体模型的收敛性和泛化能力。
🖼️ 关键图片


📊 实验亮点
TARDIS在实验中表现出色,在前馈网络中实现了80%的参数缩减,同时显著优于最先进的剪枝方法Wanda和RIA,精度提高了高达65%。在实际部署中,与vLLM集成时实现了1.6倍的端到端推理加速,与HuggingFace集成时实现了1.4倍的加速,而精度损失仅为10.9%。这些结果表明TARDIS在参数缩减和性能提升方面具有显著优势。
🎯 应用场景
TARDIS技术可广泛应用于各种需要部署大型语言模型的场景,例如智能客服、机器翻译、文本生成、代码生成等。通过降低模型大小和提高推理速度,TARDIS可以降低部署成本,提高用户体验,并使得LLM能够在资源受限的设备上运行。未来,TARDIS有望成为LLM部署的重要优化手段。
📄 摘要(原文)
Large language models (LLMs) demonstrate remarkable capabilities but face deployment challenges due to their massive parameter counts. While existing compression techniques like pruning can reduce model size, it leads to significant accuracy degradation under high compression ratios. We present a novel perspective inspired by constant folding in compiler optimization. Our approach enables parameter reduction by treating activation functions in LLMs as linear functions. However, recent LLMs use complex non-linear activations like GELU that prevent direct application of this technique. We propose TARDIS, which enables optimization of LLMs with non-linear activations by partially approximating them with linear functions in frequently occurring input ranges. For outlier inputs, TARDIS employs an online predictor to dynamically fall back to original computations. Our experiments demonstrate that TARDIS achieves 80% parameter reduction in feed-forward networks, while significantly outperforming state-of-the-art pruning methods Wanda and RIA with up to 65% higher accuracy. In practical deployments for a 7B model, TARDIS achieves 1.6x end-to-end inference speedup when integrated with the vLLM serving system, and 1.4x speedup with the widely adopted HuggingFace implementation, while incurring only a 10.9% accuracy trade-off.