Beyond Reward Hacking: Causal Rewards for Large Language Model Alignment
作者: Chaoqi Wang, Zhuokai Zhao, Yibo Jiang, Zhaorun Chen, Chen Zhu, Yuxin Chen, Jiayi Liu, Lizhu Zhang, Xiangjun Fan, Hao Ma, Sinong Wang
分类: cs.LG, cs.AI
发布日期: 2025-01-16 (更新: 2025-05-29)
💡 一句话要点
提出因果奖励建模方法,提升大型语言模型对齐的可靠性和公平性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 人类反馈 因果推理 奖励建模 对齐 反事实不变性
📋 核心要点
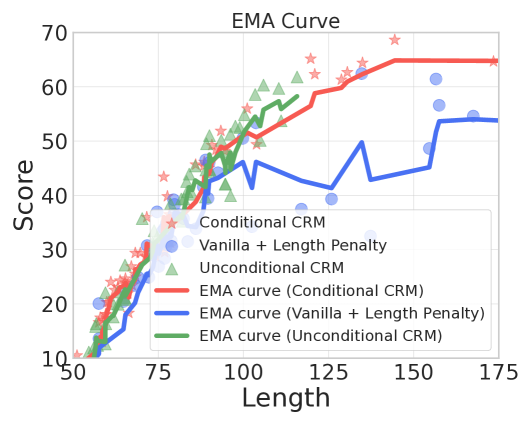
- RLHF易受奖励模型中虚假相关性的影响,导致LLM产生长度偏差、谄媚等问题,阻碍模型学习真实因果关系。
- 论文提出一种因果奖励建模方法,通过引入因果关系来减轻虚假相关性,并强制反事实不变性,保证奖励预测的一致性。
- 实验结果表明,该方法能有效缓解各种虚假相关性,提升LLM与人类偏好对齐的可靠性和公平性,且易于集成到现有RLHF流程中。
📝 摘要(中文)
大型语言模型(LLMs)在执行复杂任务方面取得了显著进展。尽管从人类反馈中进行强化学习(RLHF)在将LLMs与人类偏好对齐方面是有效的,但它容易受到奖励建模中虚假相关性的影响。因此,它经常引入偏差——例如长度偏差、谄媚、概念偏差和歧视——这阻碍了模型捕捉真实因果关系的能力。为了解决这个问题,我们提出了一种新颖的因果奖励建模方法,该方法集成了因果关系以减轻这些虚假相关性。我们的方法强制执行反事实不变性,确保当不相关的变量被改变时,奖励预测保持一致。通过在合成和真实世界数据集上的实验,我们表明我们的方法有效地减轻了各种类型的虚假相关性,从而使LLMs与人类偏好的对齐更加可靠和公平。作为对现有RLHF工作流程的直接增强,我们的因果奖励建模提供了一种实用的方法来提高LLM微调的可信度和公平性。
🔬 方法详解
问题定义:现有基于RLHF的大型语言模型对齐方法,其奖励模型容易受到训练数据中虚假相关性的影响,导致模型学习到错误的模式,例如,模型可能因为回复的长度更长而给予更高的奖励,或者因为回复的内容更符合人类的期望(即使是错误的期望)而给予更高的奖励。这些虚假相关性导致模型产生偏差,降低了模型的可靠性和公平性。
核心思路:论文的核心思路是利用因果推理来消除奖励模型中的虚假相关性。具体来说,论文通过强制反事实不变性,即当改变与奖励无关的变量时,奖励预测应该保持不变。这样可以确保奖励模型学习到的是真实的因果关系,而不是虚假的统计相关性。
技术框架:该方法可以作为现有RLHF流程的直接增强。首先,收集训练数据,包括模型生成的回复和人类给出的奖励。然后,使用因果奖励建模方法训练奖励模型,该模型的目标是预测给定回复的奖励,同时强制反事实不变性。最后,使用训练好的奖励模型来指导LLM的微调,使其更好地与人类偏好对齐。
关键创新:该方法最重要的技术创新点在于将因果推理引入到奖励建模中,通过强制反事实不变性来消除虚假相关性。与传统的奖励建模方法相比,该方法能够学习到更鲁棒、更可靠的奖励模型,从而提升LLM的对齐效果。
关键设计:论文通过设计特定的损失函数来实现反事实不变性。例如,可以设计一个损失函数,惩罚当改变与奖励无关的变量时,奖励预测发生的变化。具体的实现方式可能包括使用因果图来建模变量之间的因果关系,并使用干预操作来模拟改变变量的效果。此外,还可以使用对抗训练等技术来增强模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
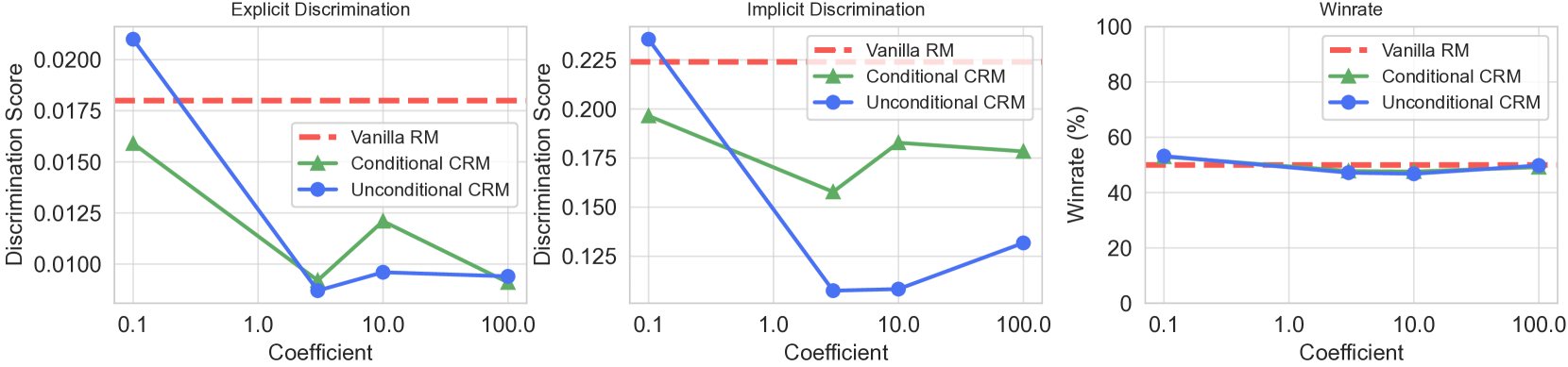
论文在合成数据集和真实数据集上进行了实验,结果表明,提出的因果奖励建模方法能够有效缓解各种类型的虚假相关性,例如长度偏差、谄媚等。实验结果表明,使用该方法训练的LLM在多个指标上都优于基线方法,例如,在公平性指标上取得了显著提升。
🎯 应用场景
该研究成果可广泛应用于各种需要大型语言模型与人类偏好对齐的场景,例如智能客服、内容生成、对话系统等。通过提高LLM的可靠性和公平性,可以提升用户体验,减少潜在的偏见和歧视,并促进人工智能技术的健康发展。未来,该方法可以进一步扩展到其他类型的机器学习模型和任务中。
📄 摘要(原文)
Recent advances in large language models (LLMs) have demonstrated significant progress in performing complex tasks. While Reinforcement Learning from Human Feedback (RLHF) has been effective in aligning LLMs with human preferences, it is susceptible to spurious correlations in reward modeling. Consequently, it often introduces biases-such as length bias, sycophancy, conceptual bias, and discrimination-that hinder the model's ability to capture true causal relationships. To address this, we propose a novel causal reward modeling approach that integrates causality to mitigate these spurious correlations. Our method enforces counterfactual invariance, ensuring reward predictions remain consistent when irrelevant variables are altered. Through experiments on both synthetic and real-world datasets, we show that our approach mitigates various types of spurious correlations effectively, resulting in more reliable and fair alignment of LLMs with human preferences. As a drop-in enhancement to the existing RLHF workflow, our causal reward modeling provides a practical way to improve the trustworthiness and fairness of LLM finetuning.