Confidence Estimation for Error Detection in Text-to-SQL Systems
作者: Oleg Somov, Elena Tutubalina
分类: cs.LG, cs.CL
发布日期: 2025-01-16
备注: 15 pages, 11 figures, to be published in AAAI 2025 Proceedings
DOI: 10.1609/aaai.v39i23.34699
💡 一句话要点
针对Text-to-SQL系统,提出基于熵的置信度估计方法以进行错误检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 自然语言查询 置信度估计 错误检测 选择性分类器
📋 核心要点
- Text-to-SQL系统面临泛化能力弱和置信度不可靠的问题,限制了其广泛应用。
- 论文提出利用基于熵的置信度估计和选择性分类器,来提升Text-to-SQL系统的错误检测能力。
- 实验表明,T5模型校准性优于GPT-4和Llama 3,且选择性分类器能有效检测不相关问题导致的错误。
📝 摘要(中文)
Text-to-SQL技术使用户能够通过自然语言与数据库交互,简化信息的检索和综合。尽管大型语言模型(LLM)在将自然语言问题转换为SQL查询方面取得了成功,但其更广泛的应用受到两个主要挑战的限制:在各种查询中实现稳健的泛化,并确保对其预测具有可解释的置信度。为了解决这些问题,本研究探讨了将选择性分类器集成到Text-to-SQL系统中。我们分析了使用基于熵的置信度估计和选择性分类器在覆盖率和风险之间的权衡,并评估了其对Text-to-SQL模型整体性能的影响。此外,我们探索了模型的初始校准,并通过校准技术对其进行改进,以更好地对齐置信度和准确性。实验结果表明,编码器-解码器T5比上下文学习GPT-4和仅解码器Llama 3具有更好的校准效果,因此指定的外部基于熵的选择性分类器具有更好的性能。该研究还表明,在错误检测方面,具有较高概率的选择性分类器检测到与不相关问题相关的错误,而不是不正确的查询生成。
🔬 方法详解
问题定义:Text-to-SQL系统在将自然语言转换为SQL查询时,容易出现错误,且现有方法缺乏对预测结果置信度的有效评估。这导致用户难以信任和依赖这些系统,尤其是在对准确性要求高的场景下。现有方法难以区分正确和错误的预测,也无法有效处理由于输入问题不相关而导致的错误。
核心思路:论文的核心思路是利用选择性分类器,并结合基于熵的置信度估计,来识别和过滤掉Text-to-SQL系统可能产生的错误预测。通过评估模型预测结果的不确定性,选择性分类器可以决定是否接受或拒绝某个预测,从而在覆盖率(接受的预测比例)和风险(错误预测的比例)之间进行权衡。这样设计的目的是提高系统的整体准确性和可靠性。
技术框架:整体框架包含以下几个主要步骤:1) 使用Text-to-SQL模型(如T5、GPT-4、Llama 3)生成SQL查询;2) 使用基于熵的置信度估计方法计算每个预测结果的置信度得分;3) 使用选择性分类器,根据置信度得分决定是否接受或拒绝该预测;4) 使用校准技术(如果需要)来改进模型的初始校准,使置信度得分更准确地反映预测的可靠性。
关键创新:最重要的技术创新点在于将选择性分类器与基于熵的置信度估计相结合,用于Text-to-SQL系统的错误检测。与现有方法相比,该方法能够更有效地识别和过滤掉错误预测,从而提高系统的整体准确性和可靠性。此外,论文还分析了不同Text-to-SQL模型(如T5、GPT-4、Llama 3)的校准情况,并提出了相应的改进方法。
关键设计:论文的关键设计包括:1) 使用熵作为置信度估计的指标,熵越高表示预测结果的不确定性越大;2) 设计选择性分类器的阈值,用于决定接受或拒绝预测结果;3) 探索不同的校准技术,以改进模型的初始校准;4) 针对不同的Text-to-SQL模型,选择合适的置信度估计和校准方法。具体参数设置和网络结构取决于所使用的Text-to-SQL模型和选择性分类器的具体实现。
🖼️ 关键图片
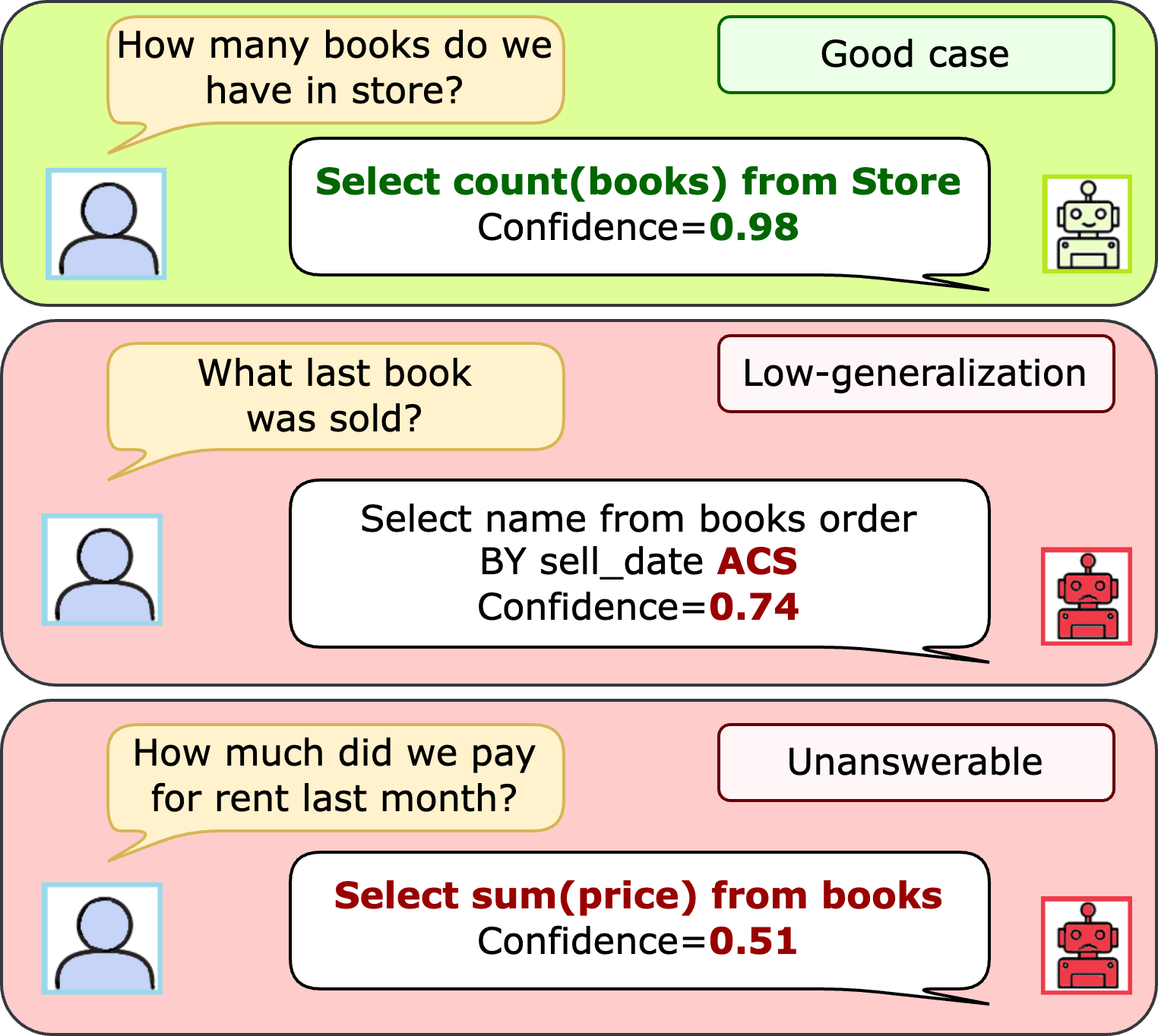
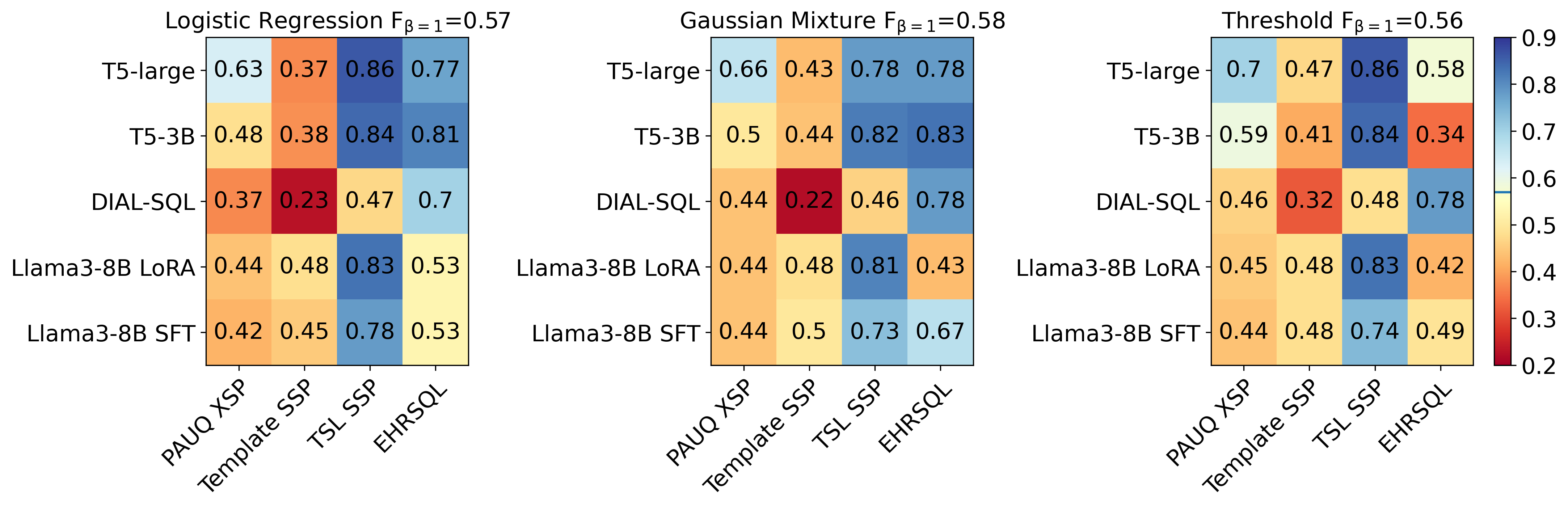

📊 实验亮点
实验结果表明,编码器-解码器T5模型比上下文学习GPT-4和仅解码器Llama 3具有更好的校准效果。此外,基于熵的选择性分类器能够有效检测与不相关问题相关的错误,从而提高Text-to-SQL系统的整体准确性。具体性能提升数据未知,但研究强调了选择性分类器在错误检测方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要自然语言查询数据库的场景,例如智能客服、数据分析平台、商业智能系统等。通过提高Text-to-SQL系统的准确性和可靠性,可以降低人工干预的需求,提高工作效率,并为用户提供更可靠的数据支持。未来,该技术有望进一步扩展到更复杂的数据库查询和数据分析任务中。
📄 摘要(原文)
Text-to-SQL enables users to interact with databases through natural language, simplifying the retrieval and synthesis of information. Despite the success of large language models (LLMs) in converting natural language questions into SQL queries, their broader adoption is limited by two main challenges: achieving robust generalization across diverse queries and ensuring interpretative confidence in their predictions. To tackle these issues, our research investigates the integration of selective classifiers into Text-to-SQL systems. We analyse the trade-off between coverage and risk using entropy based confidence estimation with selective classifiers and assess its impact on the overall performance of Text-to-SQL models. Additionally, we explore the models' initial calibration and improve it with calibration techniques for better model alignment between confidence and accuracy. Our experimental results show that encoder-decoder T5 is better calibrated than in-context-learning GPT 4 and decoder-only Llama 3, thus the designated external entropy-based selective classifier has better performance. The study also reveal that, in terms of error detection, selective classifier with a higher probability detects errors associated with irrelevant questions rather than incorrect query generations.