Class Incremental Fault Diagnosis under Limited Fault Data via Supervised Contrastive Knowledge Distillation
作者: Hanrong Zhang, Yifei Yao, Zixuan Wang, Jiayuan Su, Mengxuan Li, Peng Peng, Hongwei Wang
分类: cs.LG, cs.AI
发布日期: 2025-01-16 (更新: 2025-01-19)
🔗 代码/项目: GITHUB
💡 一句话要点
提出SCLIFD框架,解决少样本下类别增量故障诊断中的灾难性遗忘和类别不平衡问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 类别增量学习 故障诊断 监督对比学习 知识蒸馏 少样本学习
📋 核心要点
- 类别增量故障诊断面临少样本故障数据特征提取困难和模型灾难性遗忘的挑战,现有方法难以有效应对。
- SCLIFD框架通过监督对比知识蒸馏增强表征学习,并采用优先示例选择的样本回放策略缓解灾难性遗忘。
- 实验结果表明,SCLIFD在模拟和真实工业数据集上优于现有方法,尤其在类别不平衡场景下表现突出。
📝 摘要(中文)
本文提出了一种用于类别增量故障诊断的监督对比知识蒸馏(SCLIFD)框架,旨在解决数据不平衡和长尾分布下的问题。针对少样本故障数据难以提取判别性特征,以及新增故障类别需要耗费大量模型重训练成本的问题,SCLIFD框架利用监督对比知识蒸馏来提升表征学习能力并减少遗忘。同时,提出了一种新颖的优先示例选择方法用于样本回放,以缓解灾难性遗忘。此外,采用随机森林分类器来解决类别不平衡问题。在模拟和真实工业数据集上的大量实验表明,SCLIFD优于现有方法,并验证了其在各种不平衡比例下的有效性。
🔬 方法详解
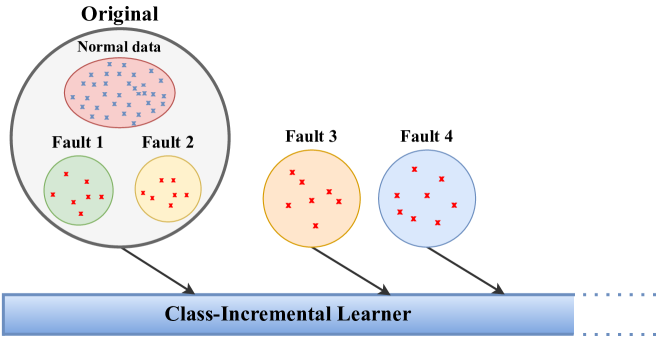
问题定义:类别增量故障诊断旨在使模型在不断增加新的故障类别时,既能学习新知识,又能保留已学知识。现有方法在少样本和类别不平衡的情况下,难以提取具有区分性的特征,且容易发生灾难性遗忘,导致模型性能下降。此外,新增类别通常需要重新训练整个模型,成本较高。
核心思路:本文的核心思路是利用监督对比学习增强特征的区分性,并通过知识蒸馏将先前模型的知识迁移到新模型,从而缓解灾难性遗忘。同时,采用样本回放策略,选择性地保留先前类别的代表性样本,进一步巩固已学知识。针对类别不平衡问题,采用随机森林分类器进行决策。
技术框架:SCLIFD框架主要包含三个模块:1) 特征提取模块,用于从输入数据中提取特征表示;2) 监督对比知识蒸馏模块,利用监督对比学习损失和知识蒸馏损失,提升特征的区分性和知识迁移能力;3) 分类模块,使用随机森林分类器对提取的特征进行分类。训练过程采用增量学习的方式,每次增加新的故障类别时,只训练新模型,并利用知识蒸馏将旧模型的知识迁移过来。
关键创新:SCLIFD的关键创新在于:1) 提出了监督对比知识蒸馏方法,将监督对比学习和知识蒸馏相结合,既能增强特征的区分性,又能有效缓解灾难性遗忘;2) 提出了一种优先示例选择方法,用于选择最具代表性的样本进行回放,进一步巩固已学知识;3) 针对类别不平衡问题,采用了随机森林分类器,提高了模型在不平衡数据上的性能。
关键设计:监督对比学习损失采用InfoNCE损失函数,旨在拉近同类样本的距离,推远不同类样本的距离。知识蒸馏损失采用KL散度损失,旨在使新模型的输出分布尽可能接近旧模型的输出分布。优先示例选择方法基于样本的置信度和多样性进行选择。随机森林分类器的参数设置根据具体数据集进行调整。
🖼️ 关键图片
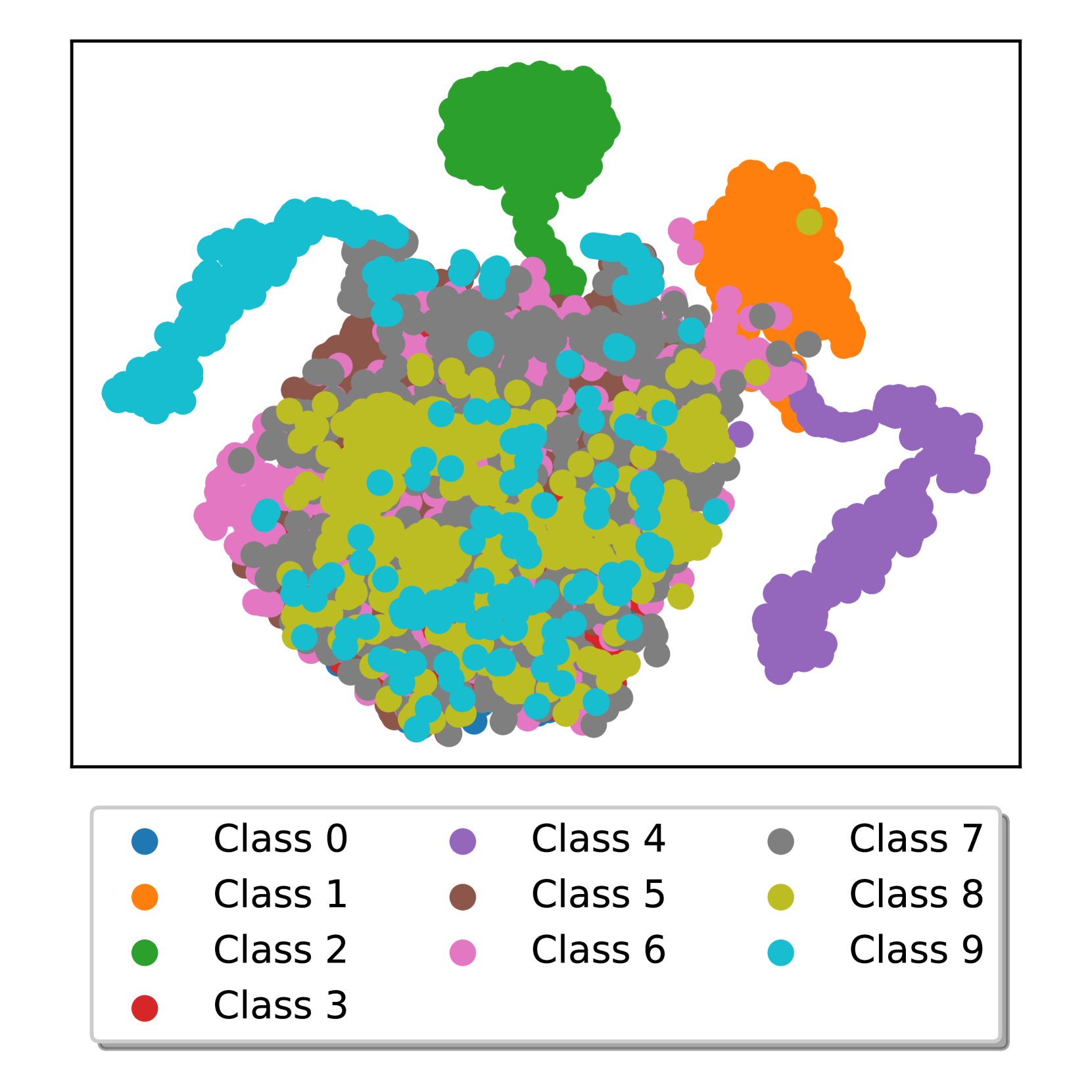
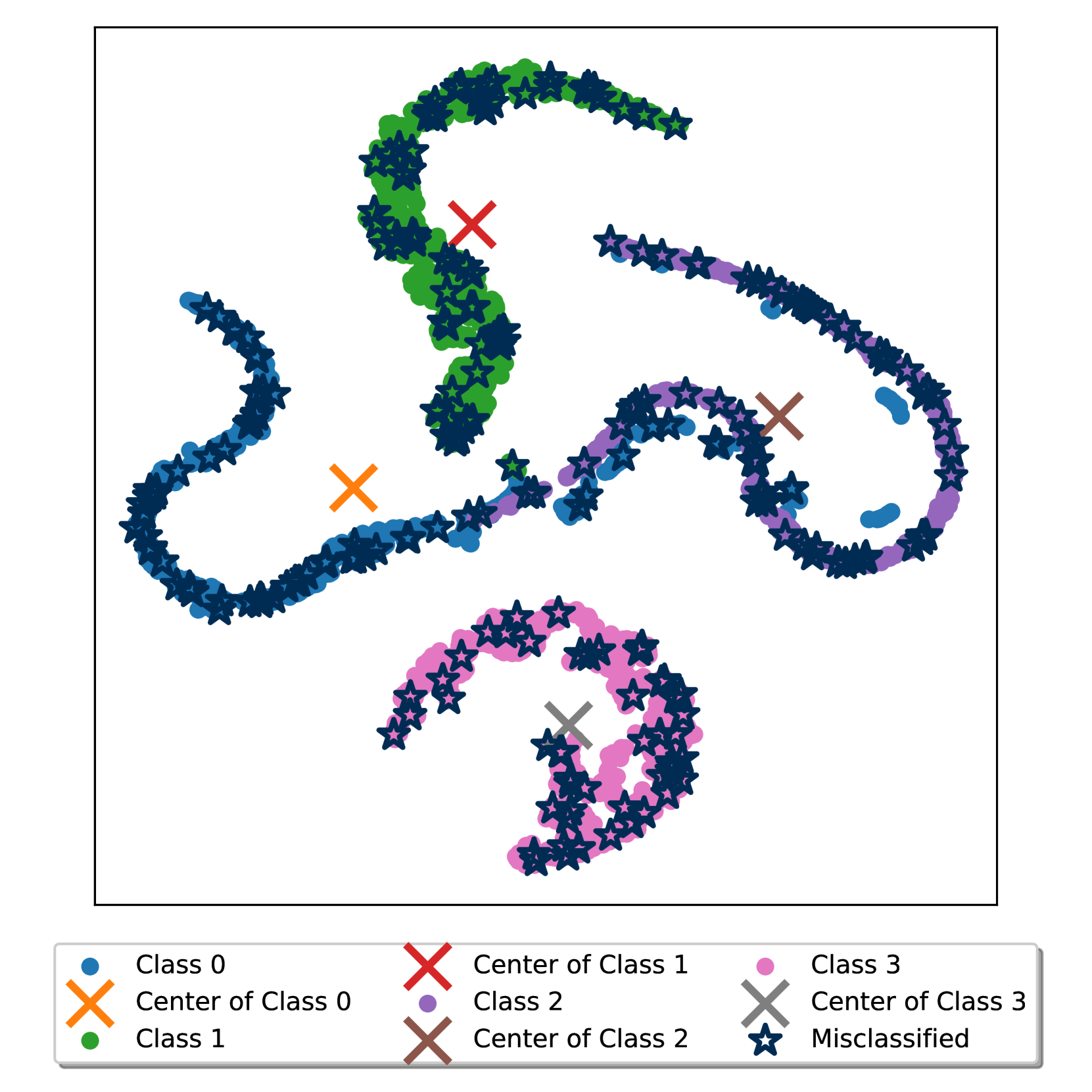
📊 实验亮点
在模拟和真实工业数据集上的实验结果表明,SCLIFD框架在类别增量故障诊断任务上优于现有方法。例如,在某个数据集上,SCLIFD的平均准确率比最佳基线方法提高了5%以上,并且在类别不平衡的情况下,性能提升更加显著。此外,实验还验证了优先示例选择方法和随机森林分类器在缓解灾难性遗忘和解决类别不平衡问题上的有效性。
🎯 应用场景
该研究成果可应用于各种工业设备的故障诊断领域,例如电机、轴承、齿轮箱等。通过增量学习的方式,模型可以不断适应新的故障类型,提高诊断的准确性和效率,降低维护成本,保障设备的安全稳定运行。未来,该方法还可以扩展到其他领域的分类问题,例如图像识别、自然语言处理等。
📄 摘要(原文)
Class-incremental fault diagnosis requires a model to adapt to new fault classes while retaining previous knowledge. However, limited research exists for imbalanced and long-tailed data. Extracting discriminative features from few-shot fault data is challenging, and adding new fault classes often demands costly model retraining. Moreover, incremental training of existing methods risks catastrophic forgetting, and severe class imbalance can bias the model's decisions toward normal classes. To tackle these issues, we introduce a Supervised Contrastive knowledge distiLlation for class Incremental Fault Diagnosis (SCLIFD) framework proposing supervised contrastive knowledge distillation for improved representation learning capability and less forgetting, a novel prioritized exemplar selection method for sample replay to alleviate catastrophic forgetting, and the Random Forest Classifier to address the class imbalance. Extensive experimentation on simulated and real-world industrial datasets across various imbalance ratios demonstrates the superiority of SCLIFD over existing approaches. Our code can be found at https://github.com/Zhang-Henry/SCLIFD_TII.