Rational Tuning of LLM Cascades via Probabilistic Modeling
作者: Michael J. Zellinger, Matt Thomson
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-01-16 (更新: 2025-06-06)
备注: 20 pages, 9 figures
💡 一句话要点
提出概率模型以优化LLM级联的置信度阈值
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 概率模型 Markov-copula 性能优化 级联系统 贝叶斯优化 错误-成本权衡
📋 核心要点
- 现有方法在预测LLM的性能时面临挑战,尤其是在复合LLM系统中,模型间的错误率交互复杂。
- 本文提出了一种基于概率模型的框架,能够通过连续优化合理调整LLM级联的置信度阈值。
- 实验结果显示,使用该模型的错误-成本权衡平均提高4.3%,在低样本情况下提升达到10.2%。
📝 摘要(中文)
近年来,理解大型语言模型(LLMs)的可靠性引起了广泛关注。由于LLMs容易产生幻觉且对提示设计高度敏感,预测单个LLM的性能已经具有挑战性。对于复合LLM系统如级联模型,更需理解不同模型的错误率如何相互作用。本文提出了一种概率模型,用于序列LLMs的联合性能分布,进而通过连续优化合理调整LLM级联的置信度阈值。与使用贝叶斯优化选择置信度阈值相比,我们的参数化Markov-copula模型在错误-成本权衡上表现更佳,平均提高了4.3%的错误-成本曲线下的面积。在低样本情况下(n ≤ 30),性能提升扩大至10.2%,表明该框架对不同LLMs错误率相互作用的归纳假设增强了样本效率。总体而言,我们的Markov-copula模型为调优LLM级联性能提供了合理基础,展示了概率方法在LLM系统分析中的潜力。
🔬 方法详解
问题定义:本文旨在解决大型语言模型级联系统中,如何有效预测和优化模型性能的问题。现有方法在处理模型间错误率交互时存在不足,导致性能预测不准确。
核心思路:论文提出了一种基于Markov-copula的概率模型,能够联合建模多个LLM的性能分布,从而通过优化置信度阈值来提升级联系统的整体性能。
技术框架:该框架包括数据收集、模型训练和置信度阈值优化三个主要模块。首先收集各个LLM的性能数据,然后构建Markov-copula模型,最后通过连续优化算法调整置信度阈值。
关键创新:最重要的创新在于引入了Markov-copula模型,能够有效捕捉不同LLM间的错误率交互,显著改善了错误-成本权衡,与传统的贝叶斯优化方法相比具有更好的性能。
关键设计:模型中使用了参数化的Markov-copula结构,设计了适应性损失函数以优化置信度阈值,确保在低样本情况下也能保持高效的性能提升。
🖼️ 关键图片
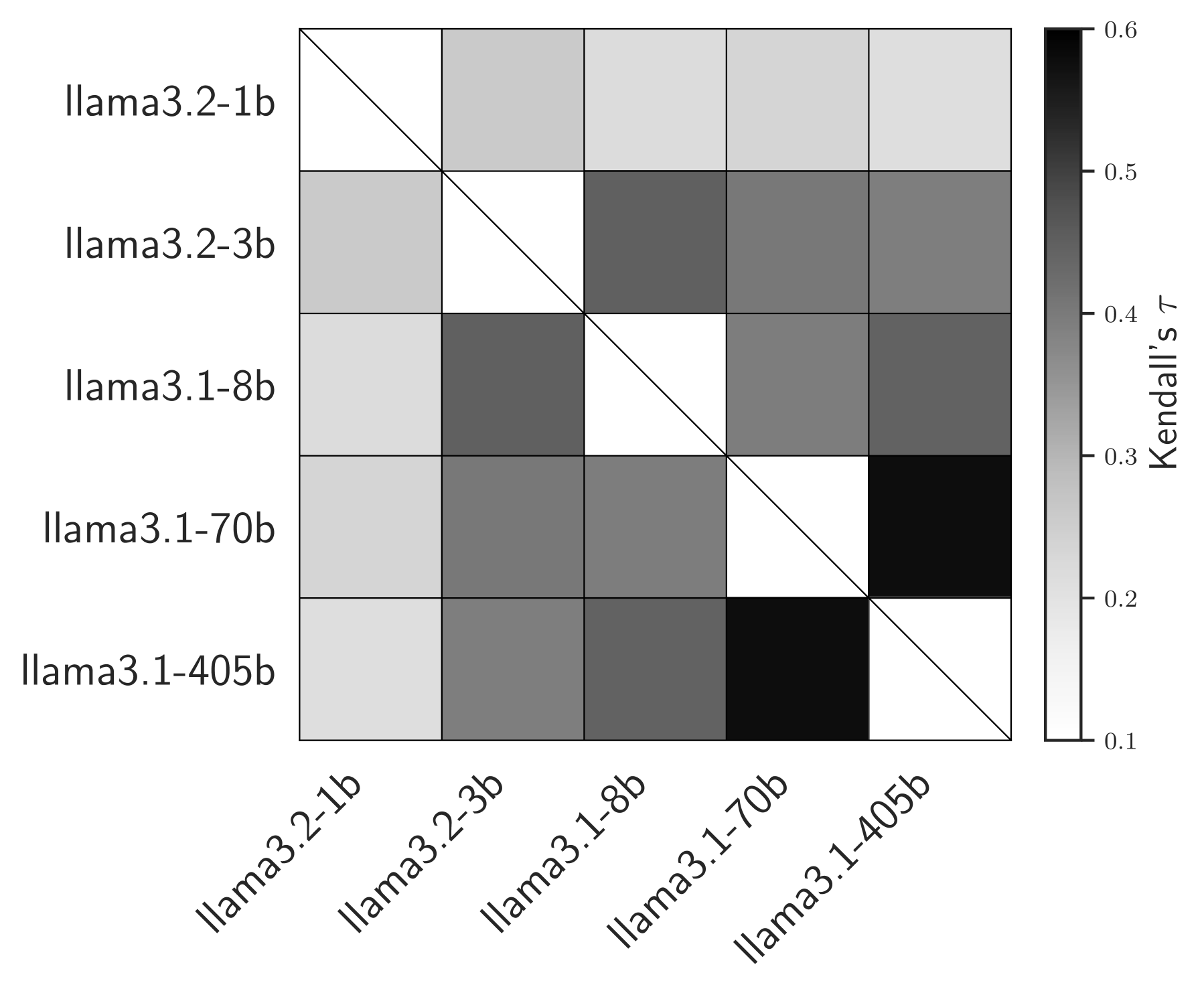
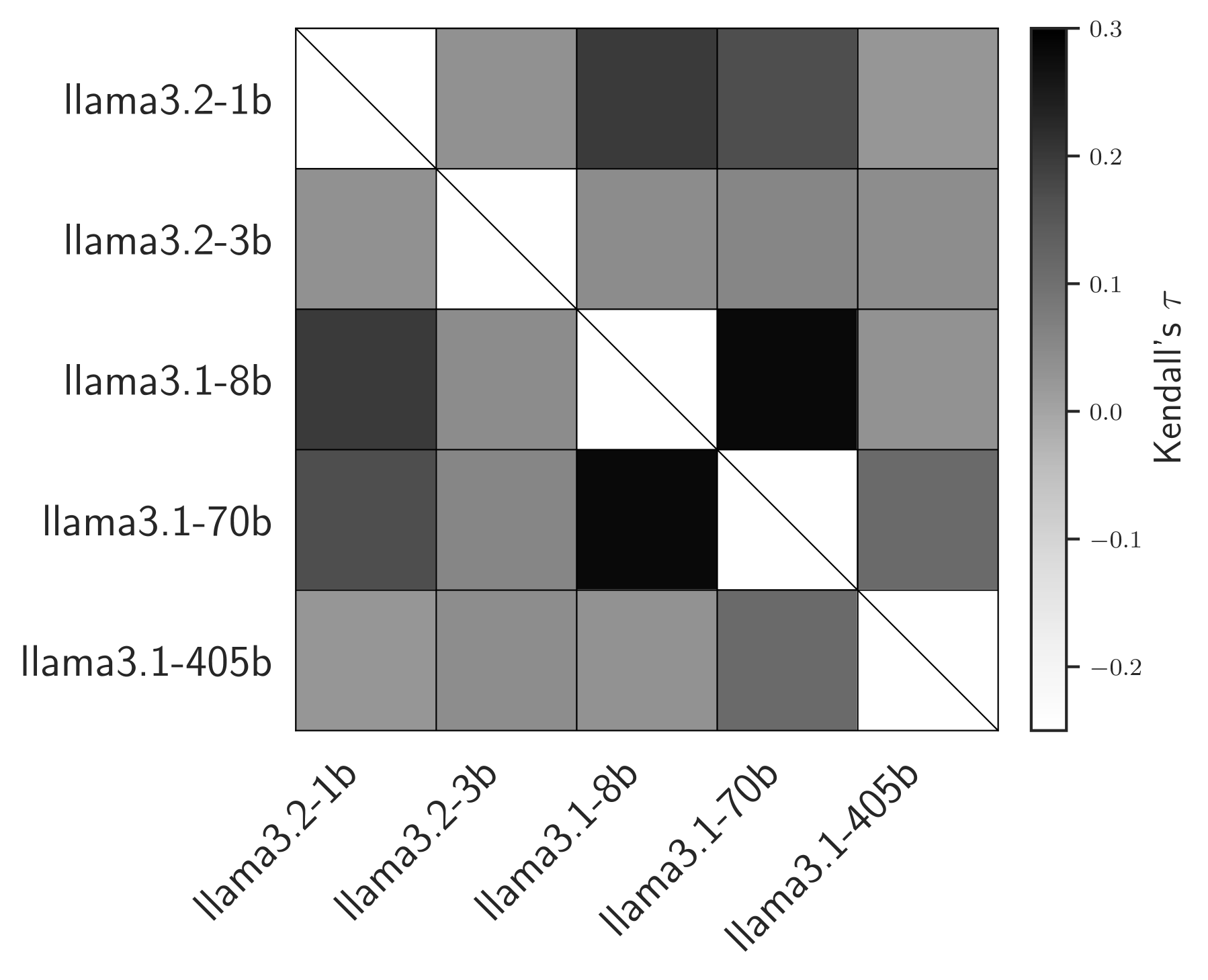
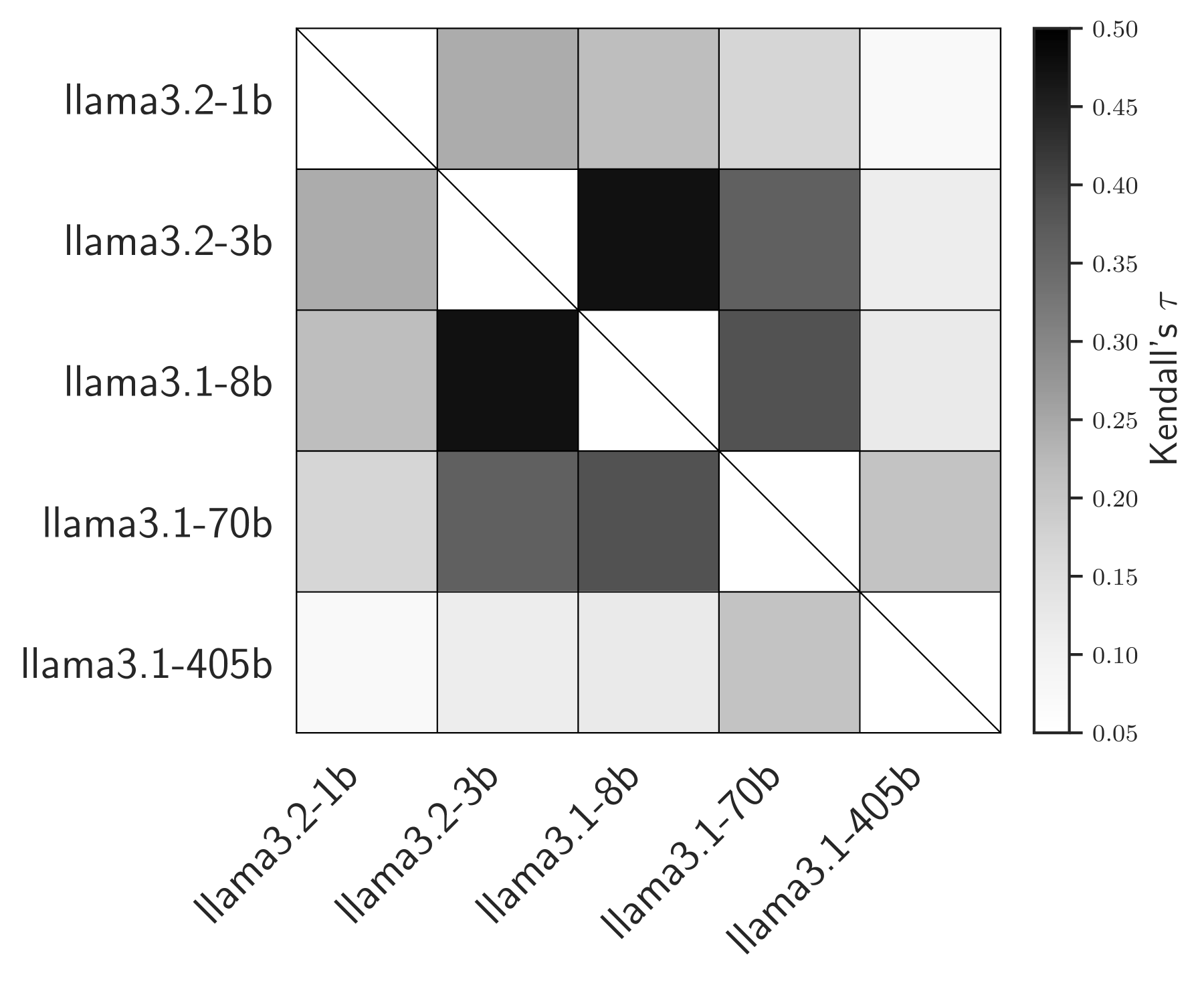
📊 实验亮点
实验结果表明,使用Markov-copula模型的错误-成本权衡平均提高了4.3%,在低样本情况下的提升幅度达到10.2%。这些结果显示了该模型在优化LLM级联性能方面的有效性,尤其是在样本稀缺的情况下。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和文本生成等。通过优化LLM级联的性能,可以提高这些系统在实际应用中的可靠性和效率,进而推动智能助手、自动翻译等技术的发展。未来,该方法可能在多模态学习和复杂系统分析中发挥更大作用。
📄 摘要(原文)
Understanding the reliability of large language models (LLMs) has recently garnered significant attention. Given LLMs' propensity to hallucinate, as well as their high sensitivity to prompt design, it is already challenging to predict the performance of an individual LLM. However, the problem becomes more complex for compound LLM systems such as cascades, where in addition to each model's standalone performance, we must understand how the error rates of different models interact. In this paper, we present a probabilistic model for the joint performance distribution of a sequence of LLMs, which enables a framework for rationally tuning the confidence thresholds of a LLM cascade using continuous optimization. Compared to selecting confidence thresholds using Bayesian optimization, our parametric Markov-copula model yields more favorable error-cost trade-offs, improving the area under the error-cost curve by 4.3% on average for cascades with $k\geq 3$ models. In the low-sample regime with $n \leq 30$ training examples, the performance improvement widens to 10.2%, suggesting that our framework's inductive assumptions about the interactions between the error rates of different LLMs enhance sample efficiency. Overall, our Markov-copula model provides a rational basis for tuning LLM cascade performance and points to the potential of probabilistic methods in analyzing systems of LLMs.