Clone-Robust AI Alignment
作者: Ariel D. Procaccia, Benjamin Schiffer, Shirley Zhang
分类: cs.LG, cs.AI, cs.GT
发布日期: 2025-01-16
💡 一句话要点
提出加权MLE算法,增强RLHF在非均匀数据集下的克隆鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RLHF 人工智能对齐 克隆鲁棒性 最大似然估计 奖励函数学习
📋 核心要点
- 现有RLHF算法在非均匀数据集上表现不佳,对近似克隆缺乏鲁棒性,导致奖励函数不稳定。
- 论文提出加权MLE算法,通过对相似备选项进行加权,提高算法对近似克隆的鲁棒性。
- 理论分析和实验结果表明,加权MLE算法在保证克隆鲁棒性的同时,保留了原算法的优良性质。
📝 摘要(中文)
在训练大型语言模型(LLM)时,一个关键挑战是如何使其与人类偏好对齐。基于人类反馈的强化学习(RLHF)利用人工标注者提供的成对比较来训练奖励函数,并已成为一种流行的对齐方法。然而,RLHF中的输入数据集在问题和答案的类型上不一定是平衡的。因此,我们希望RLHF算法即使在备选项集合不是均匀分布的情况下也能表现良好。借鉴社会选择理论的见解,我们引入了对近似克隆的鲁棒性,这是RLHF算法的一个理想属性,它要求添加近似重复的备选项不会显著改变学习到的奖励函数。我们首先证明了基于正则化最大似然估计(MLE)的标准RLHF算法未能满足此属性。然后,我们提出了一种新的RLHF算法,即加权MLE,它通过基于备选项与其他备选项的相似性对其进行加权来修改标准正则化MLE。这种新算法保证了对近似克隆的鲁棒性,同时保留了理想的理论性质。
🔬 方法详解
问题定义:论文旨在解决RLHF算法在训练数据集中存在大量近似重复样本(克隆)时,学习到的奖励函数不稳定,泛化能力下降的问题。现有的基于正则化最大似然估计(MLE)的RLHF算法对这种克隆数据非常敏感,添加或删除少量克隆样本可能导致奖励函数发生显著变化。
核心思路:论文的核心思路是借鉴社会选择理论中的思想,通过对备选项进行加权,降低克隆样本对奖励函数的影响。具体来说,对于与其它备选项相似的样本,降低其权重;对于独特的样本,提高其权重。这样可以使得算法更加关注具有代表性的样本,从而提高对克隆数据的鲁棒性。
技术框架:论文提出的加权MLE算法是在标准正则化MLE算法的基础上进行改进的。整体框架与标准RLHF算法类似,包括以下步骤:1) 收集人类反馈数据(成对比较);2) 计算备选项之间的相似度;3) 根据相似度计算每个备选项的权重;4) 使用加权后的数据进行最大似然估计,学习奖励函数。
关键创新:论文最重要的技术创新点在于提出了加权MLE算法,通过对备选项进行加权,有效地解决了RLHF算法对克隆数据敏感的问题。与标准MLE算法相比,加权MLE算法能够学习到更加稳定和泛化的奖励函数。
关键设计:关键设计包括:1) 相似度度量:可以使用各种相似度度量方法,例如余弦相似度、编辑距离等。论文中具体使用的相似度度量方法未知。2) 权重计算:根据备选项的相似度计算权重,可以使用各种加权策略。论文中具体使用的加权策略未知。3) 正则化项:为了防止过拟合,仍然需要使用正则化项。正则化项的具体形式与标准MLE算法相同。
🖼️ 关键图片
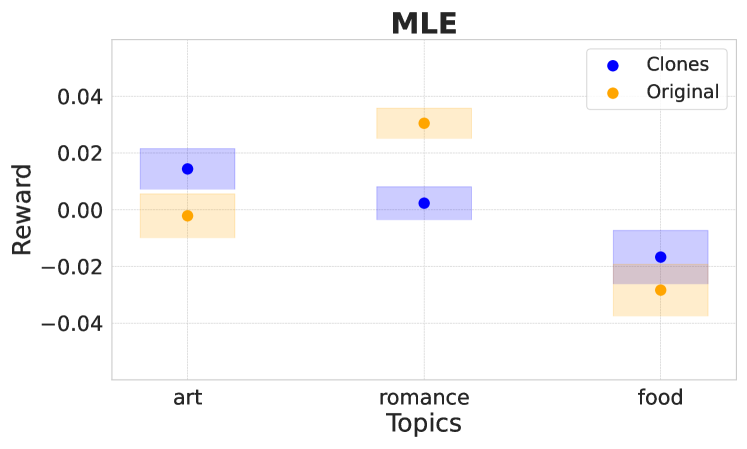
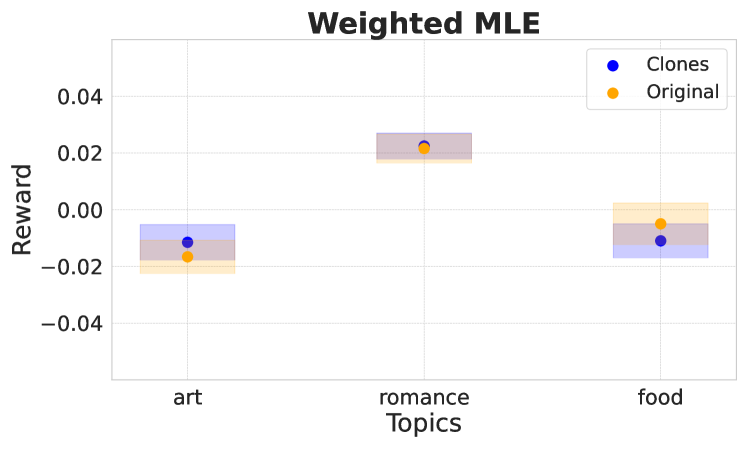

📊 实验亮点
论文证明了标准RLHF算法对近似克隆缺乏鲁棒性,并提出了加权MLE算法作为解决方案。理论分析表明,加权MLE算法在保证克隆鲁棒性的同时,保留了原算法的优良性质。具体的实验结果未知,但论文声称该算法能够有效地提高模型在非均匀数据集上的性能。
🎯 应用场景
该研究成果可应用于各种需要使用RLHF进行模型对齐的场景,例如大型语言模型、对话系统、推荐系统等。通过提高算法对克隆数据的鲁棒性,可以减少对训练数据质量的依赖,降低人工标注成本,并提高模型的泛化能力。
📄 摘要(原文)
A key challenge in training Large Language Models (LLMs) is properly aligning them with human preferences. Reinforcement Learning with Human Feedback (RLHF) uses pairwise comparisons from human annotators to train reward functions and has emerged as a popular alignment method. However, input datasets in RLHF are not necessarily balanced in the types of questions and answers that are included. Therefore, we want RLHF algorithms to perform well even when the set of alternatives is not uniformly distributed. Drawing on insights from social choice theory, we introduce robustness to approximate clones, a desirable property of RLHF algorithms which requires that adding near-duplicate alternatives does not significantly change the learned reward function. We first demonstrate that the standard RLHF algorithm based on regularized maximum likelihood estimation (MLE) fails to satisfy this property. We then propose the weighted MLE, a new RLHF algorithm that modifies the standard regularized MLE by weighting alternatives based on their similarity to other alternatives. This new algorithm guarantees robustness to approximate clones while preserving desirable theoretical properties.