Disentangling Exploration of Large Language Models by Optimal Exploitation
作者: Tim Grams, Patrick Betz, Sascha Marton, Stefan Lüdtke, Christian Bartelt
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-15 (更新: 2025-08-24)
💡 一句话要点
通过最优利用解耦大语言模型中的探索能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 探索与利用 强化学习 上下文学习 信息增益
📋 核心要点
- 现有方法难以有效评估大型语言模型在部分隐藏状态空间中的探索能力,因为回报率不足以区分探索和利用。
- 论文提出将探索作为唯一目标,通过分解缺失回报为探索和利用两部分,基于最优可实现回报来评估探索性能。
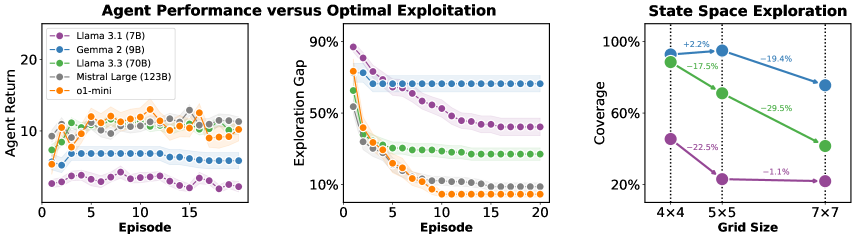
- 实验表明,多数模型探索能力不足,但探索性能与推理能力正相关,该分解方法可用于优化提示工程。
📝 摘要(中文)
探索是未知环境中上下文强化学习的关键技能。然而,大型语言模型是否能有效地探索部分隐藏的状态空间仍不清楚。本文将探索作为唯一目标,让智能体收集信息以提高未来的回报。在此框架内,我们认为仅测量智能体的回报不足以进行公平的评估。因此,我们基于最优可实现的回报,将缺失的回报分解为探索和利用两个组成部分。对各种模型的实验表明,大多数模型难以探索状态空间,且探索能力不足。尽管如此,我们发现探索性能和推理能力之间存在正相关关系。我们的分解可以深入了解由提示工程驱动的行为差异,为改进探索性任务的性能提供有价值的工具。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在上下文强化学习中,如何有效探索部分隐藏状态空间的问题。现有方法仅依赖智能体的回报来评估探索能力,无法区分回报的缺失是由于探索不足还是利用不足造成的,因此无法公平地评估模型的探索性能。
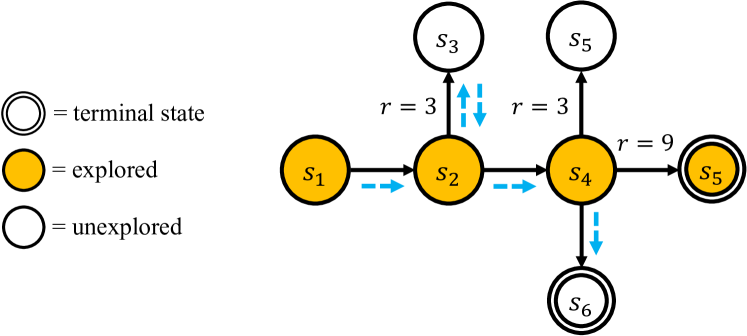
核心思路:论文的核心思路是将探索任务独立出来,将其作为智能体的唯一目标,即最大化未来回报的信息增益。通过这种方式,可以将总回报分解为由探索带来的回报和由利用带来的回报,从而更准确地评估模型的探索能力。同时,论文基于最优可实现的回报,来衡量智能体在探索和利用方面的表现。
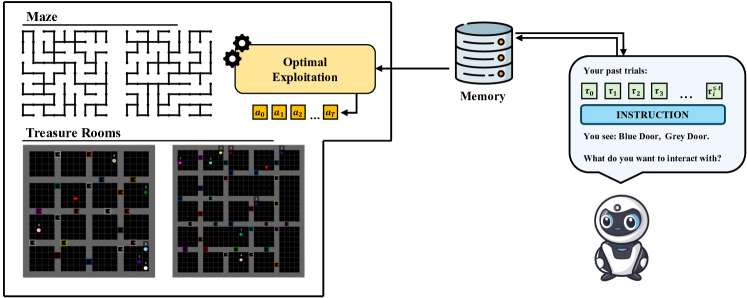
技术框架:论文的技术框架主要包含以下几个步骤:1) 定义一个部分隐藏的状态空间环境;2) 将探索作为智能体的唯一目标,即最大化未来回报的信息增益;3) 智能体与环境交互,收集信息并采取行动;4) 基于最优可实现的回报,将智能体的总回报分解为探索回报和利用回报;5) 使用不同的大型语言模型作为智能体,在不同的环境下进行实验,评估其探索性能。
关键创新:论文的关键创新在于提出了一种将探索与利用解耦的评估方法。通过将探索作为唯一目标,并基于最优可实现的回报来分解总回报,可以更准确地评估大型语言模型在复杂环境中的探索能力。这种方法可以帮助研究人员更好地理解大型语言模型的行为,并改进其在探索性任务中的性能。
关键设计:论文的关键设计包括:1) 使用部分隐藏的状态空间环境,模拟真实世界中信息不完全的情况;2) 定义了信息增益作为探索的奖励函数,鼓励智能体探索未知的状态;3) 使用最优可实现的回报作为基准,来衡量智能体在探索和利用方面的表现;4) 通过实验,研究了不同的大型语言模型在不同环境下的探索性能,并分析了探索性能与推理能力之间的关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,大多数大型语言模型在探索状态空间方面存在困难,且探索能力不足。然而,研究发现探索性能与推理能力之间存在正相关关系,表明提高模型的推理能力可能有助于提高其探索能力。此外,论文提出的分解方法可以有效区分由提示工程驱动的行为差异,为优化探索性任务的性能提供了有价值的工具。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等领域,帮助智能体在未知或部分未知的环境中进行有效的探索和学习。通过解耦探索和利用,可以更好地理解和优化智能体的行为,提高其在复杂环境中的适应性和决策能力。此外,该方法还可以用于评估和比较不同大型语言模型的探索能力,为模型选择和优化提供依据。
📄 摘要(原文)
Exploration is a crucial skill for in-context reinforcement learning in unknown environments. However, it remains unclear if large language models can effectively explore a partially hidden state space. This work isolates exploration as the sole objective, tasking an agent with gathering information that enhances future returns. Within this framework, we argue that measuring agent returns is not sufficient for a fair evaluation. Hence, we decompose missing rewards into their exploration and exploitation components based on the optimal achievable return. Experiments with various models reveal that most struggle to explore the state space, and weak exploration is insufficient. Nevertheless, we found a positive correlation between exploration performance and reasoning capabilities. Our decomposition can provide insights into differences in behaviors driven by prompt engineering, offering a valuable tool for refining performance in exploratory tasks.