SWSC: Shared Weight for Similar Channel in LLM
作者: Binrui Zeng, Yongtao Tang, Xiaodong Liu, Xiaopeng Li
分类: cs.LG, cs.CL
发布日期: 2025-01-15
备注: 5pages, 3 figures, work in progress
💡 一句话要点
提出SWSC方法,通过共享相似通道权重有效压缩LLM并保持性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 权重共享 K-Means聚类 奇异值分解 模型优化 低精度量化 通道剪枝
📋 核心要点
- LLM参数量巨大,带来存储和计算负担,模型压缩是关键。
- SWSC通过K-Means聚类相似通道权重,共享代表性向量以减少参数。
- 对压缩误差进行奇异值分解,保留重要奇异值补偿精度损失。
📝 摘要(中文)
大型语言模型(LLM)推动了多个行业的发展。然而,其参数数量的增长带来了巨大的存储和计算负担,因此探索模型压缩技术以减少参数和简化部署至关重要。我们提出了一种基于相似通道共享权重的LLM压缩方法SWSC。该方法使用K-Means聚类算法逐通道地对模型权重进行聚类,生成每个簇内具有高度相似向量的簇。从每个簇中选择一个代表性向量来近似替换簇中的所有向量,从而显著减少模型权重参数的数量。然而,近似恢复不可避免地会对模型的性能造成损害。为了解决这个问题,我们对压缩前后权重误差值进行奇异值分解,并保留较大的奇异值及其对应的奇异向量,以补偿精度。实验结果表明,即使在低精度条件下,我们的方法也能有效保证压缩后的LLM的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)参数量过大,导致存储和计算资源消耗过高的问题。现有模型压缩方法在降低参数量的同时,往往会显著降低模型性能,尤其是在低精度条件下。因此,如何在保证模型性能的前提下,有效地压缩LLM是本研究要解决的核心问题。
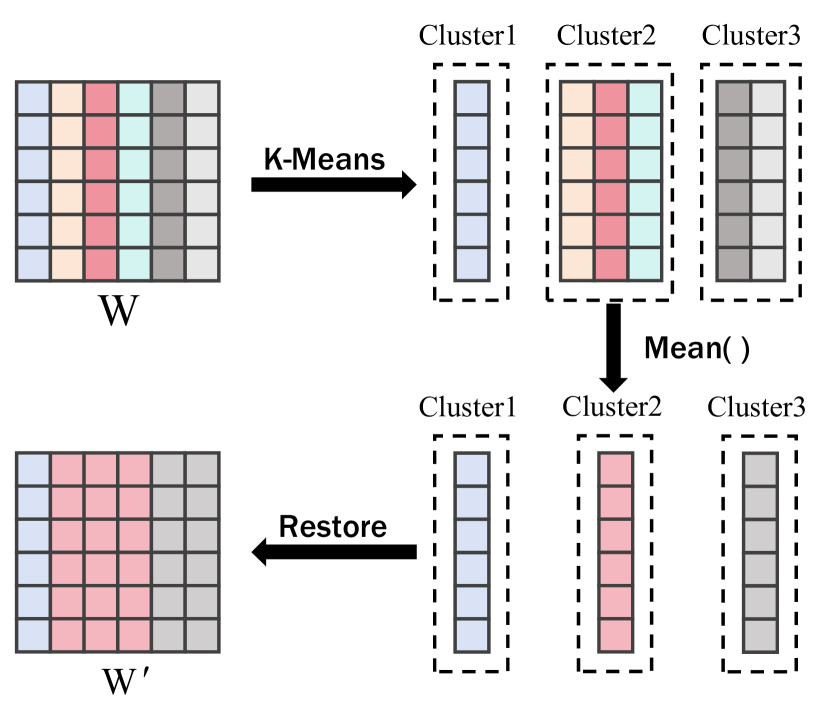
核心思路:论文的核心思路是观察到LLM中存在大量相似的通道权重,因此可以通过共享这些相似通道的权重来减少参数量。具体来说,将相似的通道权重聚类到同一个簇中,并用一个代表性的权重向量来代替该簇中的所有权重向量。这样,只需要存储代表性权重向量,而不需要存储每个通道的权重向量,从而达到压缩的目的。为了弥补压缩带来的性能损失,论文还提出对压缩误差进行补偿。
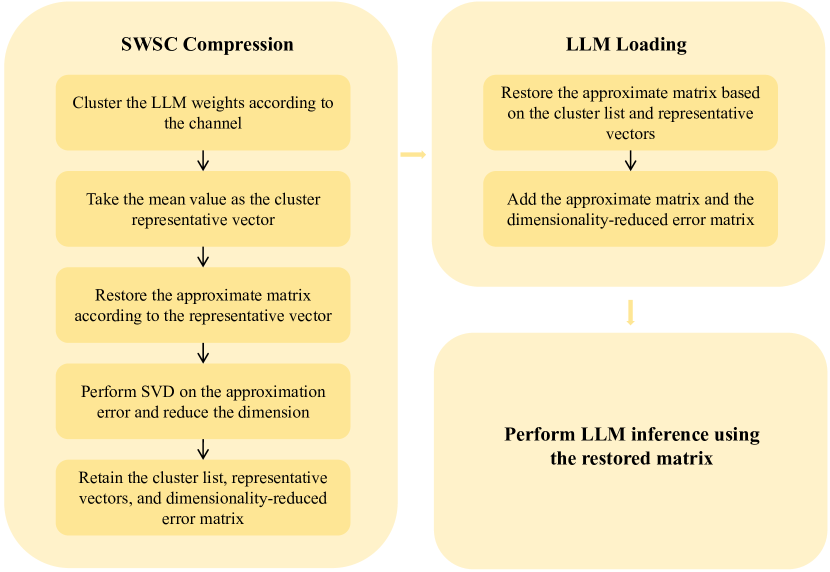
技术框架:SWSC方法的整体框架包括以下几个主要阶段:1. 权重聚类:使用K-Means算法对LLM的权重矩阵进行逐通道的聚类,将相似的通道权重划分到同一个簇中。2. 权重共享:对于每个簇,选择一个代表性的权重向量(例如,簇的中心点)来代替该簇中的所有权重向量。3. 误差补偿:对压缩前后权重误差值进行奇异值分解(SVD),保留较大的奇异值及其对应的奇异向量,用于补偿压缩带来的精度损失。4. 模型微调(可选):在压缩后,可以对模型进行微调,以进一步提高模型的性能。
关键创新:SWSC方法的关键创新在于:1. 相似通道权重共享:利用LLM中通道权重的冗余性,通过聚类和共享权重来减少参数量。2. 奇异值分解误差补偿:通过对压缩误差进行奇异值分解,保留重要的奇异值和奇异向量,有效地补偿了压缩带来的精度损失。与现有方法相比,SWSC方法能够在保证模型性能的前提下,实现更高的压缩率。
关键设计:1. K-Means聚类:使用K-Means算法进行权重聚类,需要选择合适的簇的数量K。K的选择会影响压缩率和模型性能之间的平衡。2. 奇异值分解:对压缩误差进行奇异值分解,需要选择保留的奇异值的数量。保留的奇异值越多,补偿的精度越高,但计算成本也越高。3. 微调策略:如果进行模型微调,需要选择合适的学习率、优化器和训练数据。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SWSC方法能够在保证LLM性能的前提下,有效地压缩模型大小。具体来说,在多个LLM模型上进行了实验,结果表明,在低精度条件下,SWSC方法能够在保持模型性能基本不变的情况下,将模型大小压缩到原来的1/4甚至更小。与现有的模型压缩方法相比,SWSC方法在压缩率和模型性能之间取得了更好的平衡。
🎯 应用场景
SWSC方法可应用于各种需要部署大型语言模型的场景,例如移动设备、边缘计算设备等资源受限的环境。通过压缩模型大小,可以降低存储和计算成本,提高推理速度,从而使LLM能够在更广泛的场景中得到应用。此外,该方法还可以用于模型加速和模型蒸馏等任务。
📄 摘要(原文)
Large language models (LLMs) have spurred development in multiple industries. However, the growing number of their parameters brings substantial storage and computing burdens, making it essential to explore model compression techniques for parameter reduction and easier deployment. We propose SWSC, an LLM compression method based on the concept of Shared Weight for Similar Channel. It uses the K-Means clustering algorithm to cluster model weights channel-by-channel, generating clusters with highly similar vectors within each. A representative vector from each cluster is selected to approximately replace all vectors in the cluster, significantly reducing the number of model weight parameters. However, approximate restoration will inevitably cause damage to the performance of the model. To tackle this issue, we perform singular value decomposition on the weight error values before and after compression and retain the larger singular values and their corresponding singular vectors to compensate for the accuracy. The experimental results show that our method can effectively ensure the performance of the compressed LLM even under low-precision conditions.