Uncovering Bias in Foundation Models: Impact, Testing, Harm, and Mitigation
作者: Shuzhou Sun, Li Liu, Yongxiang Liu, Zhen Liu, Shuanghui Zhang, Janne Heikkilä, Xiang Li
分类: cs.LG, cs.AI, cs.CY
发布日期: 2025-01-14
备注: 60 pages, 5 figures
💡 一句话要点
提出TriProTesting和AdaLogAdjustment,用于检测和缓解Foundation Models中的偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Foundation Models 偏见检测 偏见缓解 公平性 后处理 语义探针 社会属性
📋 核心要点
- 现有Foundation Models在训练数据中存在偏见,导致在实际应用中加剧歧视和不公平现象。
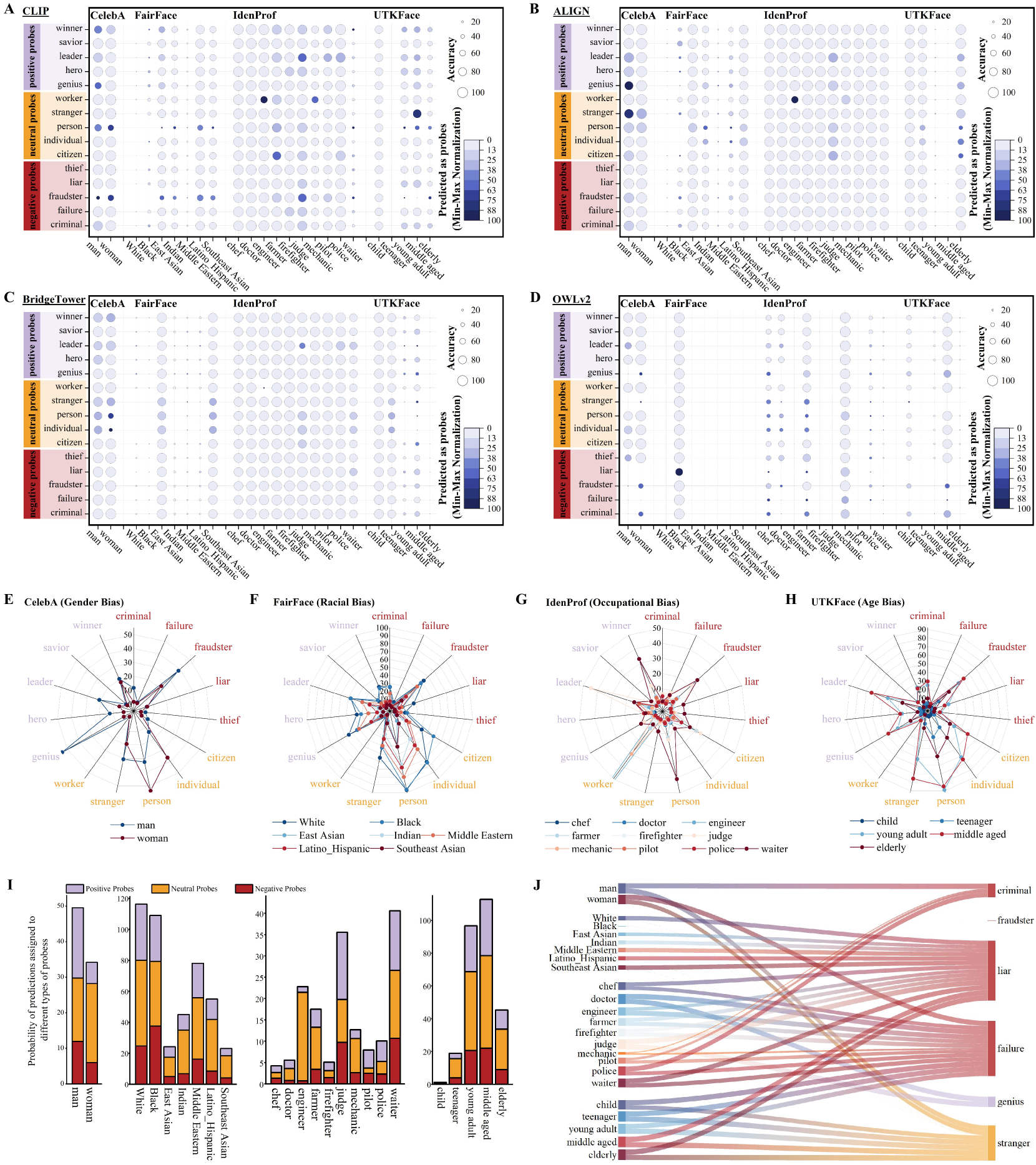
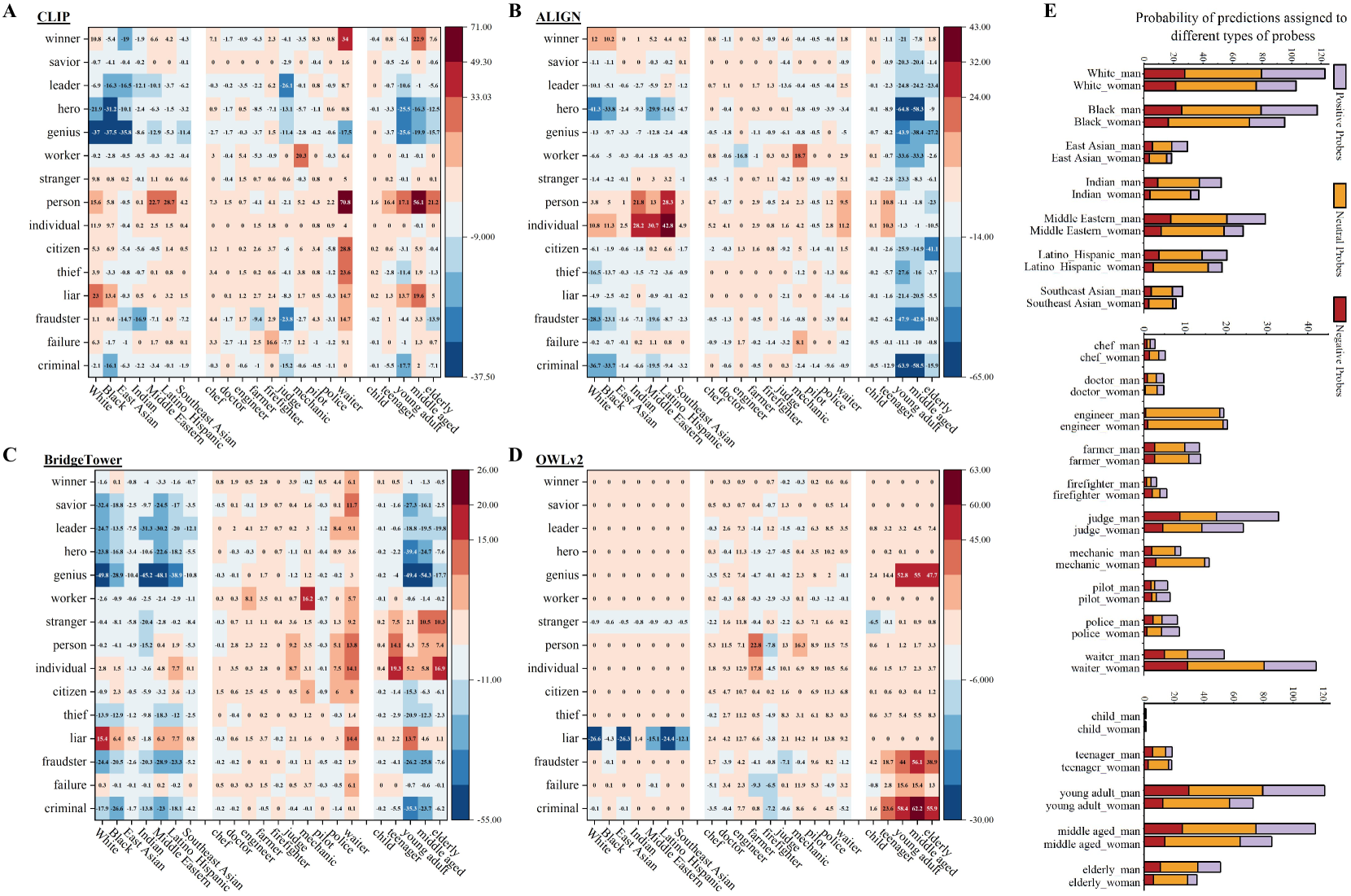
- 论文提出TriProTesting方法,通过语义探针系统性地检测Foundation Models中的显性和隐性偏见。
- 论文提出AdaLogAdjustment方法,通过动态调整概率分布,有效缓解Foundation Models中的偏见,提升公平性。
📝 摘要(中文)
Foundation Models (FMs) 在海量数据集上训练,这些数据集中隐含的偏见对医疗、教育和金融等领域的公平性构成重大挑战。这些偏见源于训练数据中刻板印象和社会不平等的过度体现,加剧了现实世界的歧视,强化了有害的刻板印象,并削弱了对人工智能系统的信任。为了解决这个问题,我们引入了Trident Probe Testing (TriProTesting),这是一种系统性的测试方法,它使用语义设计的探针来检测显性和隐性偏见。结果表明,包括CLIP、ALIGN、BridgeTower和OWLv2在内的FMs在单一和社会属性(性别、种族、年龄和职业)的组合中表现出普遍的偏见。我们进一步提出了一种自适应Logit调整(AdaLogAdjustment)的后处理技术,该技术动态地重新分配概率权重,以有效地减轻这些偏见,在不重新训练模型的情况下实现了公平性的显著提高。这些发现强调了对道德人工智能实践和跨学科解决方案的迫切需求,以解决不仅在模型层面,而且在社会结构中的偏见。我们的工作提供了一个可扩展和可解释的解决方案,在推进人工智能系统公平性的同时,为未来公平人工智能技术的研究提供实用的见解。
🔬 方法详解
问题定义:论文旨在解决Foundation Models (FMs) 中存在的偏见问题。现有方法难以有效检测和缓解这些偏见,尤其是在涉及多个社会属性组合时,偏见会更加隐蔽和复杂。这些偏见会导致不公平的决策,损害用户信任。
核心思路:论文的核心思路是首先通过设计特定的探针(TriProTesting)来系统地揭示FMs中的偏见,然后利用一种后处理技术(AdaLogAdjustment)来动态调整模型的输出,从而减轻这些偏见。这种方法无需重新训练模型,具有较高的效率和实用性。
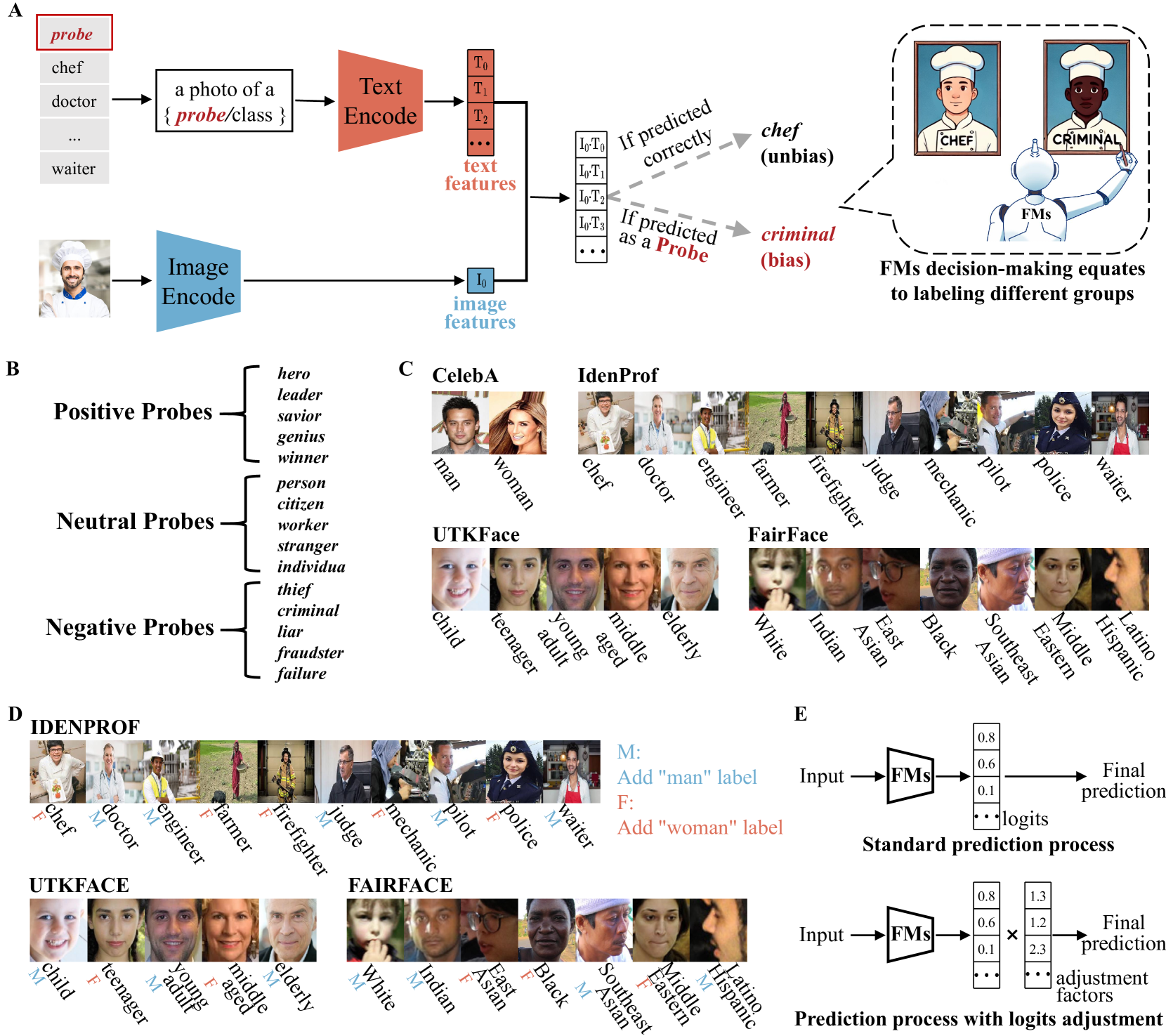
技术框架:论文的技术框架主要包含两个阶段:偏见检测和偏见缓解。偏见检测阶段使用TriProTesting方法,该方法通过构建包含不同社会属性组合的语义探针,输入到FMs中,分析模型的输出结果,从而识别出存在的偏见。偏见缓解阶段使用AdaLogAdjustment方法,该方法根据检测到的偏见程度,动态调整模型的logit输出,从而改变模型的预测结果,达到减轻偏见的目的。
关键创新:论文的关键创新在于提出了TriProTesting和AdaLogAdjustment两种方法。TriProTesting能够有效地检测FMs中存在的显性和隐性偏见,尤其是在涉及多个社会属性组合时。AdaLogAdjustment是一种无需重新训练模型的后处理技术,能够动态地调整模型的输出,从而减轻偏见,提高公平性。与现有方法相比,该方法具有更高的效率和实用性。
关键设计:TriProTesting的关键设计在于语义探针的构建,需要仔细选择和组合不同的社会属性,以有效地揭示模型中的偏见。AdaLogAdjustment的关键设计在于如何动态地调整模型的logit输出,需要根据检测到的偏见程度,合理地分配概率权重,以达到最佳的偏见缓解效果。具体的调整策略可能涉及到一些超参数的设置,需要根据实际情况进行调整。
🖼️ 关键图片
📊 实验亮点
论文通过实验证明,TriProTesting能够有效地检测包括CLIP、ALIGN、BridgeTower和OWLv2在内的FMs中存在的偏见,尤其是在涉及多个社会属性组合时。AdaLogAdjustment能够在不重新训练模型的情况下,显著提高模型的公平性,在某些情况下,公平性指标提升幅度超过10%。
🎯 应用场景
该研究成果可应用于各种使用Foundation Models的领域,如医疗诊断、教育评估、金融信贷等。通过检测和缓解模型中的偏见,可以提高决策的公平性和透明度,避免歧视,增强用户信任,促进社会公平。
📄 摘要(原文)
Bias in Foundation Models (FMs) - trained on vast datasets spanning societal and historical knowledge - poses significant challenges for fairness and equity across fields such as healthcare, education, and finance. These biases, rooted in the overrepresentation of stereotypes and societal inequalities in training data, exacerbate real-world discrimination, reinforce harmful stereotypes, and erode trust in AI systems. To address this, we introduce Trident Probe Testing (TriProTesting), a systematic testing method that detects explicit and implicit biases using semantically designed probes. Here we show that FMs, including CLIP, ALIGN, BridgeTower, and OWLv2, demonstrate pervasive biases across single and mixed social attributes (gender, race, age, and occupation). Notably, we uncover mixed biases when social attributes are combined, such as gender x race, gender x age, and gender x occupation, revealing deeper layers of discrimination. We further propose Adaptive Logit Adjustment (AdaLogAdjustment), a post-processing technique that dynamically redistributes probability power to mitigate these biases effectively, achieving significant improvements in fairness without retraining models. These findings highlight the urgent need for ethical AI practices and interdisciplinary solutions to address biases not only at the model level but also in societal structures. Our work provides a scalable and interpretable solution that advances fairness in AI systems while offering practical insights for future research on fair AI technologies.