Improving DeFi Accessibility through Efficient Liquidity Provisioning with Deep Reinforcement Learning
作者: Haonan Xu, Alessio Brini
分类: q-fin.CP, cs.LG
发布日期: 2025-01-13
备注: 9 pages, 5 figures. Accepted at AI for Social Impact: Bridging Innovations in Finance, Social Media, and Crime Prevention Workshop at AAAI 2025
💡 一句话要点
提出基于深度强化学习的流动性提供策略,优化Uniswap v3的DeFi可访问性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 DeFi 流动性提供 Uniswap v3 自动化做市商 PPO 无常损失
📋 核心要点
- 现有流动性提供策略缺乏对市场动态的自适应性,导致收益受损和无常损失。
- 利用深度强化学习,构建智能代理动态调整流动性头寸,平衡收益与风险。
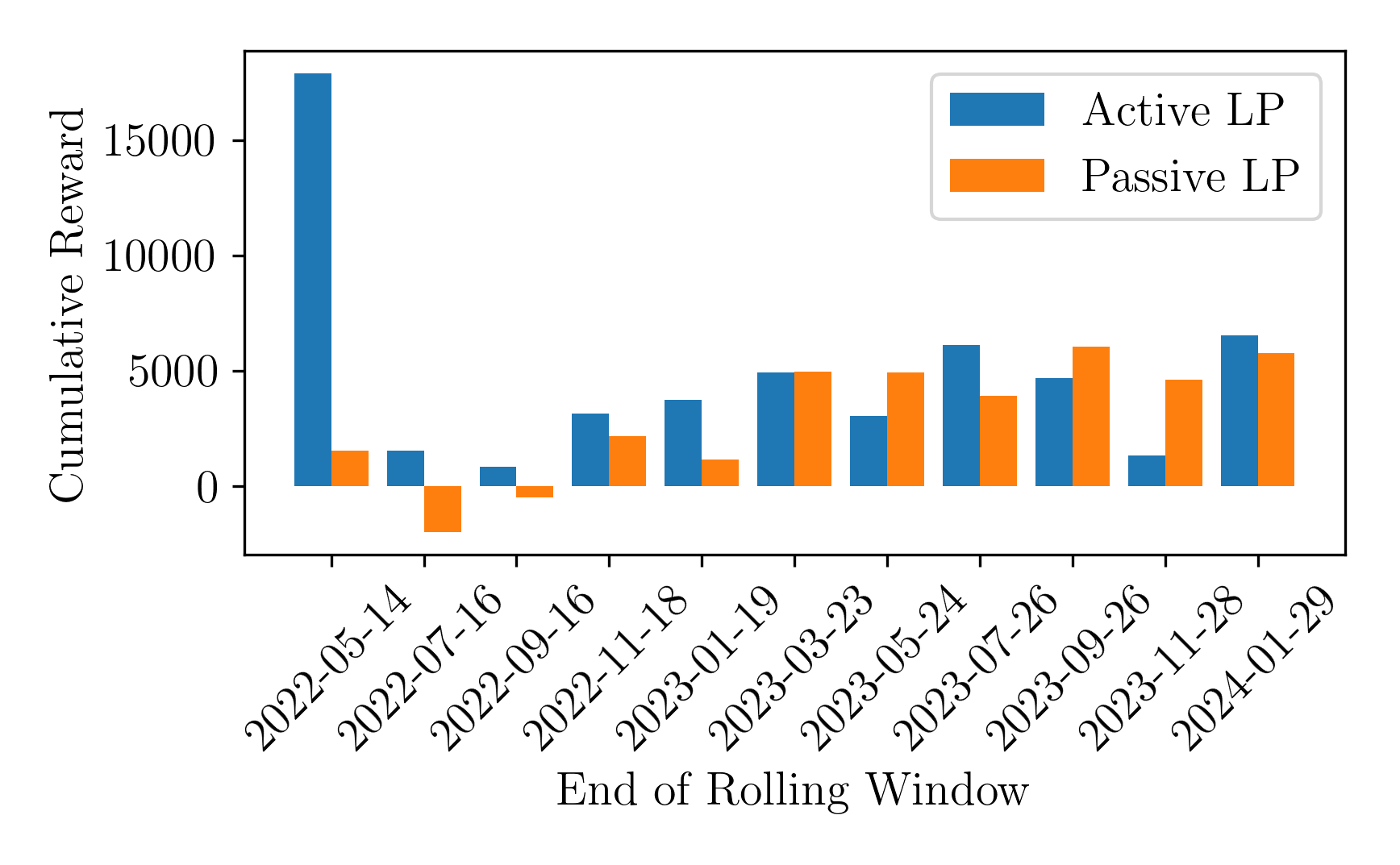
- 实验表明,该策略优于传统启发式方法,提升了流动性管理的效率。
📝 摘要(中文)
本文应用深度强化学习(DRL)来优化去中心化金融(DeFi)协议Uniswap v3中的流动性提供,Uniswap v3采用具有集中流动性的自动化做市商(AMM)模型。我们将流动性提供任务建模为马尔可夫决策过程(MDP),并使用近端策略优化(PPO)算法训练主动流动性提供者(LP)代理。该代理通过使用价格动态信息动态调整流动性头寸,以平衡费用最大化和无常损失缓解。我们使用滚动窗口方法进行训练和测试,反映了实际的市场条件和机制转变。本研究将基于DRL策略的数据驱动性能与小型零售LP参与者采用的常见启发式方法进行比较,这些参与者不会系统地修改其流动性头寸。通过促进更有效的流动性管理,这项工作旨在使DeFi市场对于更广泛的参与者而言更易于访问和包容。通过数据驱动的流动性管理方法,这项工作旨在为更高效和用户友好的DeFi市场的持续发展做出贡献。
🔬 方法详解
问题定义:论文旨在解决Uniswap v3中流动性提供者(LP)如何有效管理其流动性头寸的问题。现有方法,特别是小型零售LP采用的静态或简单启发式策略,无法充分利用Uniswap v3集中流动性的优势,难以适应快速变化的市场条件,导致收益降低和无常损失增加。
核心思路:论文的核心思路是将流动性提供任务建模为一个马尔可夫决策过程(MDP),并使用深度强化学习(DRL)训练一个智能代理。该代理能够根据市场价格动态信息,动态调整流动性头寸,从而在最大化交易费用收入和最小化无常损失之间取得平衡。这种数据驱动的方法旨在克服传统策略的局限性,提高流动性管理的效率。
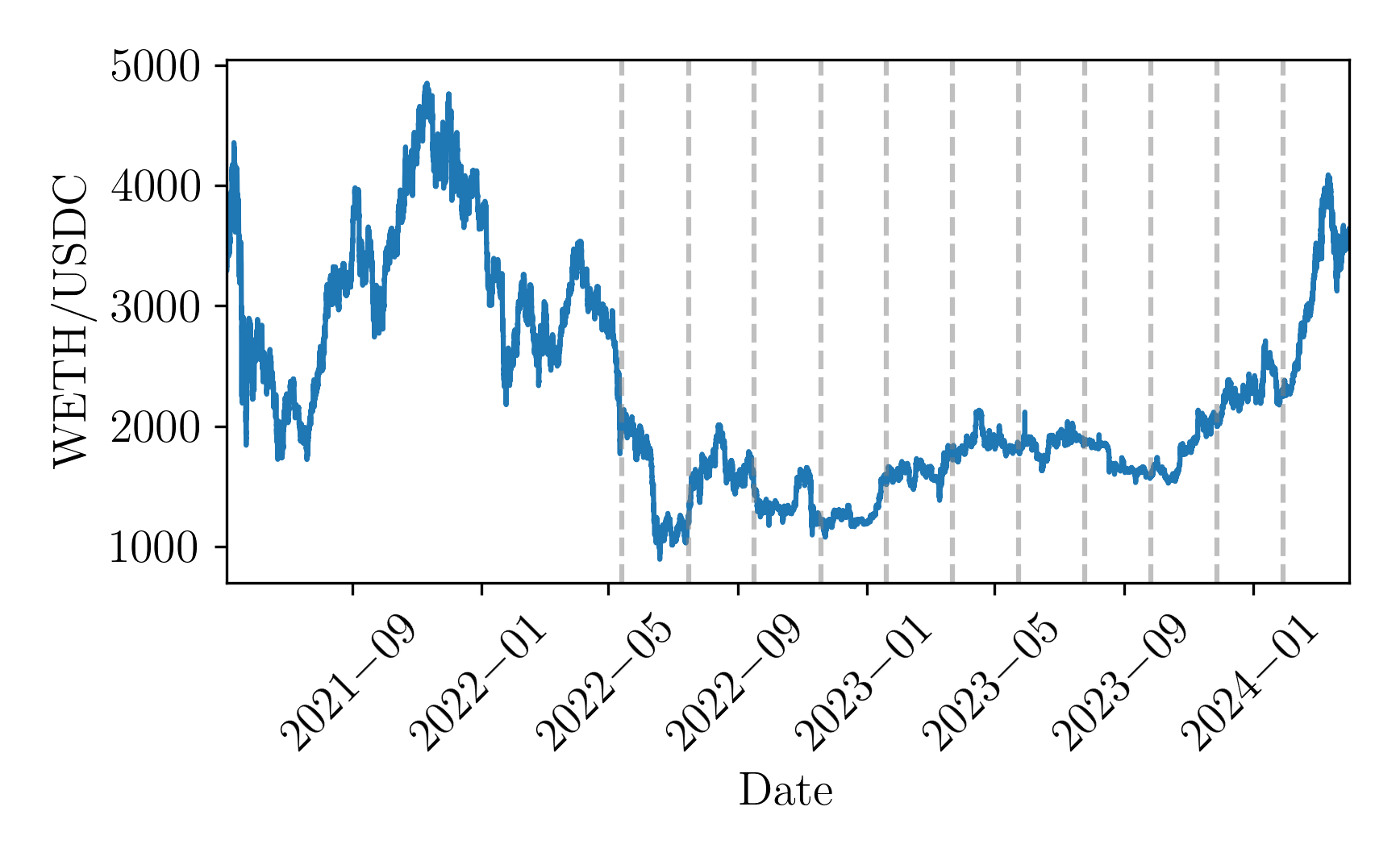
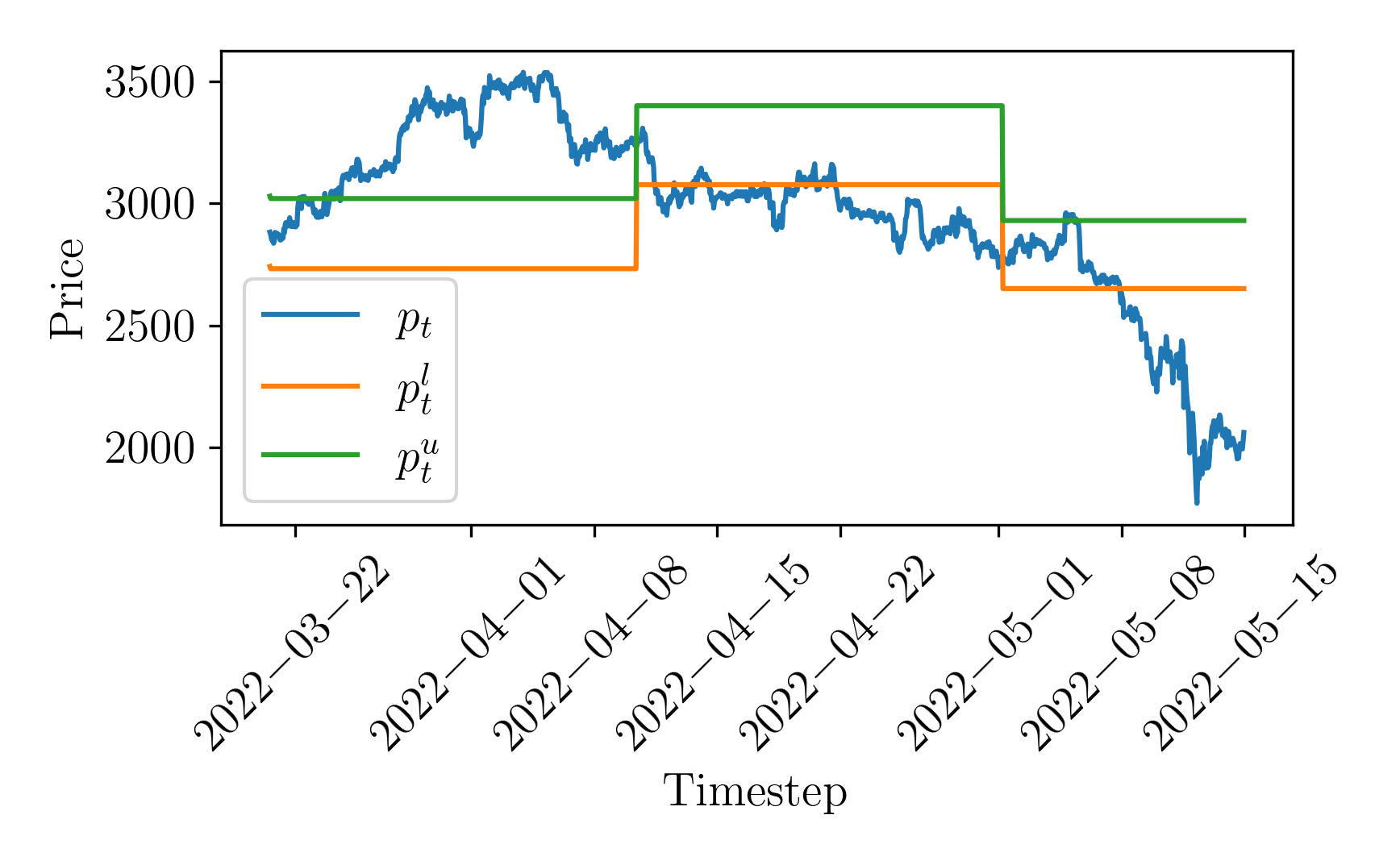
技术框架:整体框架包括以下几个主要部分:1) 环境建模:将Uniswap v3的市场环境建模为MDP,包括状态空间(例如,价格、交易量)、动作空间(例如,调整流动性范围)和奖励函数(例如,费用收入减去无常损失)。2) 代理训练:使用近端策略优化(PPO)算法训练LP代理,使其能够学习最优的流动性管理策略。3) 滚动窗口测试:使用滚动窗口方法对训练好的代理进行测试,以评估其在不同市场条件下的性能。
关键创新:最重要的技术创新点在于将深度强化学习应用于DeFi流动性提供。与传统的静态或启发式策略相比,DRL代理能够根据实时市场数据进行自适应调整,从而更有效地管理流动性。此外,使用滚动窗口方法进行训练和测试,能够更好地模拟真实的市场环境和机制转变。
关键设计:关键设计包括:1) 状态空间的设计,需要包含足够的信息来反映市场动态,同时避免维度过高。2) 奖励函数的设计,需要平衡费用收入和无常损失,以引导代理学习最优策略。3) PPO算法的参数设置,例如学习率、折扣因子等,需要进行仔细调整以获得最佳性能。4) 网络结构的选择,需要根据状态空间和动作空间的维度进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于深度强化学习的流动性提供策略在Uniswap v3上显著优于传统的启发式方法。该策略能够更有效地平衡费用收入和无常损失,从而获得更高的投资回报。具体性能数据(例如,年化收益率、夏普比率)和与基线的对比结果(例如,提升幅度)在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于各种DeFi协议中,提升流动性提供效率,降低用户参与门槛。通过智能化的流动性管理,可以吸引更多用户参与DeFi市场,提高市场流动性和稳定性,促进DeFi生态系统的发展。此外,该方法还可以扩展到其他金融领域的自动化交易和风险管理。
📄 摘要(原文)
This paper applies deep reinforcement learning (DRL) to optimize liquidity provisioning in Uniswap v3, a decentralized finance (DeFi) protocol implementing an automated market maker (AMM) model with concentrated liquidity. We model the liquidity provision task as a Markov Decision Process (MDP) and train an active liquidity provider (LP) agent using the Proximal Policy Optimization (PPO) algorithm. The agent dynamically adjusts liquidity positions by using information about price dynamics to balance fee maximization and impermanent loss mitigation. We use a rolling window approach for training and testing, reflecting realistic market conditions and regime shifts. This study compares the data-driven performance of the DRL-based strategy against common heuristics adopted by small retail LP actors that do not systematically modify their liquidity positions. By promoting more efficient liquidity management, this work aims to make DeFi markets more accessible and inclusive for a broader range of participants. Through a data-driven approach to liquidity management, this work seeks to contribute to the ongoing development of more efficient and user-friendly DeFi markets.