Human-Inspired Multi-Level Reinforcement Learning
作者: Mingkang Wu, Devin White, Vernon Lawhern, Nicholas R. Waytowich, Yongcan Cao
分类: cs.LG, cs.AI
发布日期: 2025-01-13 (更新: 2025-11-22)
备注: Accepted to the Aligning Reinforcement Learning Experimentalists and Theorists Workshop at NeurIPS 2025
💡 一句话要点
提出一种受人类启发的多层次强化学习方法,提升决策优化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 多层次学习 人类启发 策略优化 奖励信号 方向信息 决策优化
📋 核心要点
- 传统强化学习平等对待所有经验,忽略了不同失败经验的差异,这与人类的学习方式不同。
- 该论文提出一种多层次强化学习方法,通过提取多层次信息,区分不同水平的经验,从而优化决策。
- 该方法结合低层次的奖励信号和高层次的方向信息,引导智能体改进策略,实现奖励和策略的双重提升。
📝 摘要(中文)
强化学习(RL)是决策中的常用工具,它基于累积回报/奖励从各种经验中学习控制策略,而没有区别对待这些经验。相反,人类通常学会区分离散的性能水平,并提取潜在的见解/信息(超越奖励信号)以优化决策。例如,在学习打网球时,人类球员不会同等对待所有不成功的尝试。完全没击中球比击出界外表明了更严重的错误(尽管两种情况的累积奖励可能相似)。从多层次经验中有效学习对于人类决策至关重要。这促使我们开发一种新颖的多层次强化学习方法,通过提取多层次信息来从多层次经验中学习。在低层次信息提取方面,我们利用现有的基于评级的强化学习来推断内在的奖励信号,这些信号相应地说明了状态或状态-动作对的价值。在高层次信息提取方面,我们建议从不同层次的经验中提取重要的方向信息,以便可以根据与这些不同层次经验的期望偏差来更新策略。具体来说,我们提出了一种新的策略损失函数,该函数惩罚当前策略与不同层次经验之间的分布相似性,并根据性能水平为惩罚项分配不同的权重。此外,两个层次的整合朝着多层次强化学习的方向发展,引导智能体朝着有利于奖励改进和策略改进的策略改进,从而产生类似于人类的学习机制。
🔬 方法详解
问题定义:现有强化学习方法在学习过程中,通常将所有经验一视同仁,无法区分不同质量的经验。例如,在游戏学习中,一次糟糕的操作和一次接近成功的操作,在奖励上可能没有显著差异,但蕴含的信息价值却不同。这种忽略经验差异的学习方式,限制了强化学习的效率和效果。
核心思路:该论文的核心思路是模拟人类的学习方式,将经验划分为多个层次,并从不同层次的经验中提取不同的信息。低层次提取奖励信号,高层次提取方向信息,从而更有效地指导策略学习。通过区分不同层次的经验,可以更准确地评估状态和动作的价值,并引导策略朝着期望的方向改进。
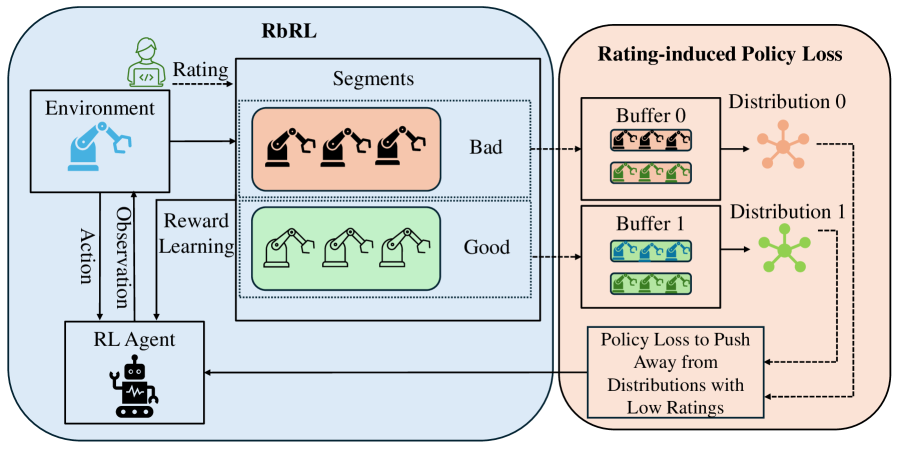
技术框架:该方法包含两个主要的信息提取层次:低层次信息提取和高层次信息提取。在低层次,利用基于评级的强化学习方法,推断内在的奖励信号,评估状态或状态-动作对的价值。在高层次,从不同层次的经验中提取方向信息,指导策略更新。整体框架通过整合这两个层次的信息,实现多层次强化学习。
关键创新:该论文的关键创新在于提出了多层次信息提取的概念,并设计了相应的技术框架。与传统强化学习方法不同,该方法能够区分不同层次的经验,并从中提取不同的信息,从而更有效地指导策略学习。此外,提出的策略损失函数,能够惩罚当前策略与不同层次经验之间的分布相似性,并根据性能水平分配不同的权重,进一步提升了学习效果。
关键设计:在高层次信息提取中,设计了一个新的策略损失函数,用于惩罚当前策略与不同层次经验之间的分布相似性。该损失函数包含多个惩罚项,每个惩罚项对应一个经验层次,并根据该层次的性能水平分配不同的权重。权重越高,表示该层次的经验越重要,对策略更新的影响也越大。此外,论文可能还涉及到一些网络结构的设计,例如用于提取奖励信号和方向信息的网络结构。
🖼️ 关键图片
📊 实验亮点
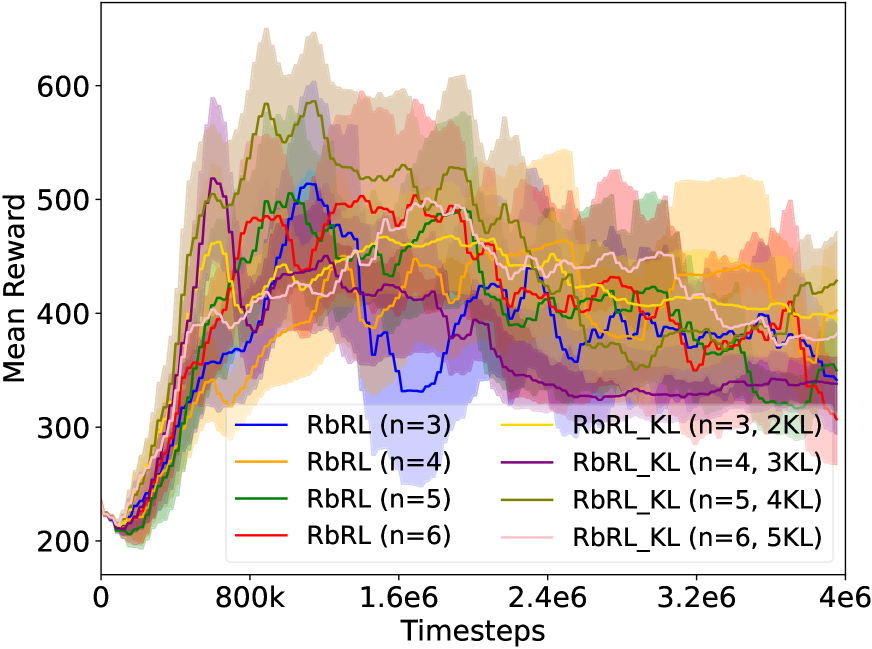
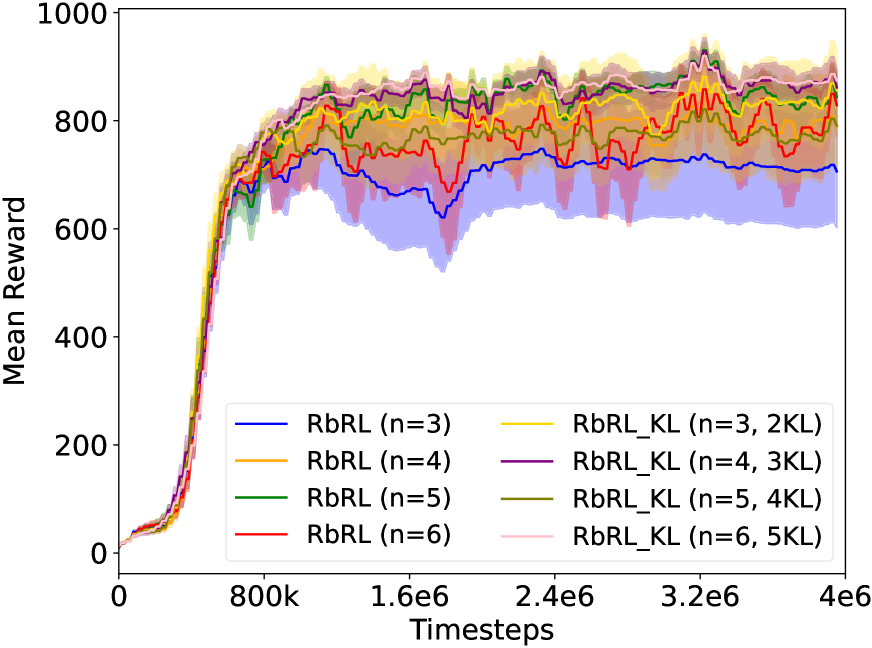
摘要中没有提供具体的实验结果和性能数据,因此无法总结实验亮点。需要查阅论文全文才能了解具体的实验设置、对比基线和性能提升幅度。目前只能推测实验可能在一些经典的强化学习环境中进行,并与现有的强化学习算法进行比较,以验证所提出方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要决策优化的领域,例如游戏AI、机器人控制、自动驾驶等。通过模拟人类的学习方式,可以提升智能体在复杂环境中的学习效率和决策能力。未来,该方法有望在更多实际场景中得到应用,例如智能制造、金融交易等。
📄 摘要(原文)
Reinforcement learning (RL), a common tool in decision making, learns control policies from various experiences based on the associated cumulative return/rewards without treating them differently. Humans, on the contrary, often learn to distinguish from discrete levels of performance and extract the underlying insights/information (beyond reward signals) towards their decision optimization. For instance, when learning to play tennis, a human player does not treat all unsuccessful attempts equally. Missing the ball completely signals a more severe mistake than hitting it out of bounds (although the cumulative rewards can be similar for both cases). Learning effectively from multi-level experiences is essential in human decision making. This motivates us to develop a novel multi-level RL method that learns from multi-level experiences via extracting multi-level information. At the low level of information extraction, we utilized the existing rating-based reinforcement learning to infer inherent reward signals that illustrate the value of states or state-action pairs accordingly. At the high level of information extraction, we propose to extract important directional information from different-level experiences so that policies can be updated towards desired deviation from these different levels of experiences. Specifically, we propose a new policy loss function that penalizes distribution similarities between the current policy and different-level experiences, and assigns different weights to the penalty terms based on the performance levels. Furthermore, the integration of the two levels towards multi-level RL guides the agent toward policy improvements that benefit both reward improvement and policy improvement, hence yielding a similar learning mechanism as humans.