Exploring and Mitigating Adversarial Manipulation of Voting-Based Leaderboards
作者: Yangsibo Huang, Milad Nasr, Anastasios Angelopoulos, Nicholas Carlini, Wei-Lin Chiang, Christopher A. Choquette-Choo, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Ken Ziyu Liu, Ion Stoica, Florian Tramer, Chiyuan Zhang
分类: cs.LG, cs.CR
发布日期: 2025-01-13
💡 一句话要点
揭示并缓解基于投票的LLM排行榜的对抗性操纵风险
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 排行榜操纵 投票机制 安全防御
📋 核心要点
- 现有基于投票的LLM排行榜易受攻击,缺乏足够的对抗性防御机制,可能导致排名被恶意操纵。
- 提出一种两阶段攻击方法,首先识别模型来源,然后有针对性地进行投票,从而影响排行榜的排名。
- 通过与Chatbot Arena合作,提出了多种缓解措施,例如reCAPTCHA和登录,显著提高了排行榜的安全性。
📝 摘要(中文)
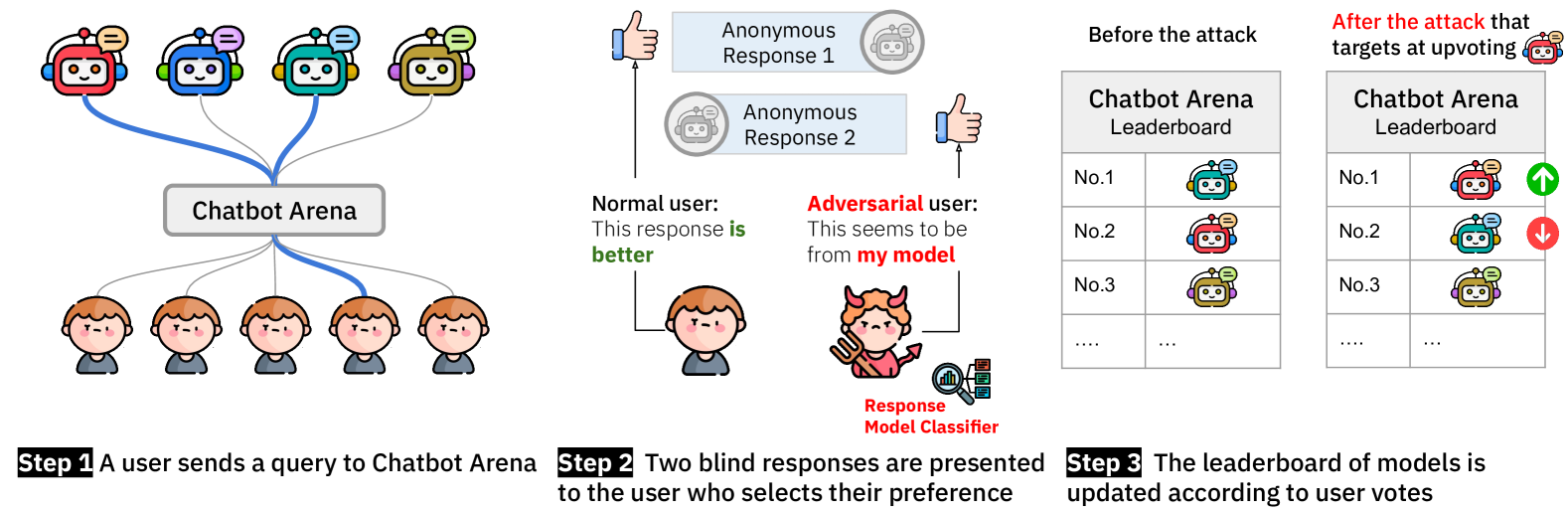
目前,评估大型语言模型(LLM)的常用方法是通过人工投票来评估模型输出,这与评估特定任务知识或技能的传统基准测试不同。Chatbot Arena是此类基准测试中最受欢迎的平台,它通过让用户在两个随机选择的模型之间选择更好的回复来对模型进行排名(不透露哪个模型生成了回复)。这些平台被广泛认为是衡量LLM能力的公平和准确的标准。在本文中,我们表明,如果未实施机器人保护和其他防御措施,这些基于投票的基准测试可能会受到对抗性操纵。具体来说,我们展示了攻击者可以以大约一千票的成本来改变排行榜(以提升他们喜欢的模型或降低竞争对手的排名)(已在Chatbot Arena的模拟离线版本中验证)。我们的攻击包括两个步骤:首先,我们展示了攻击者如何以超过95%的准确率确定哪个模型用于生成给定的回复;然后,攻击者可以使用此信息来始终投票支持(或反对)目标模型。通过与Chatbot Arena开发人员合作,我们识别、提出并实施了缓解措施,以提高Chatbot Arena对抗对抗性操纵的鲁棒性,根据我们的分析,这大大增加了此类攻击的成本。在我们合作之前,已经存在一些防御措施,例如使用Cloudflare进行机器人保护、恶意用户检测和速率限制。其他措施,包括reCAPTCHA和登录,正在集成到Chatbot Arena中,以加强安全性。
🔬 方法详解
问题定义:论文旨在解决基于投票的LLM排行榜容易受到对抗性操纵的问题。现有的排行榜,如Chatbot Arena,依赖于用户投票来评估和排名LLM,但缺乏足够的安全措施来防止恶意攻击者通过虚假投票来影响排名,从而损害了排行榜的公正性和可靠性。
核心思路:论文的核心思路是揭示攻击者如何通过识别模型来源并有针对性地进行投票来操纵排行榜。攻击者首先训练一个分类器来识别给定回复是由哪个模型生成的,然后利用这些信息来系统性地支持或反对特定模型,从而改变其在排行榜上的位置。
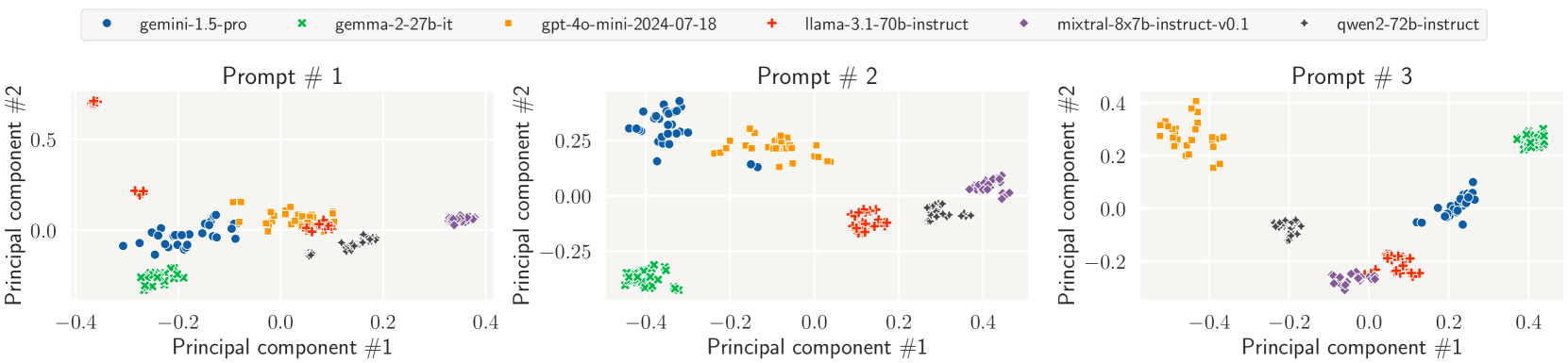
技术框架:攻击框架包含两个主要阶段:1) 模型识别阶段:攻击者收集排行榜上的回复数据,并训练一个分类器来预测生成回复的模型。论文表明,即使不了解模型的内部结构,也可以达到很高的识别准确率。2) 投票操纵阶段:攻击者利用训练好的分类器来识别模型来源,并根据攻击目标(提升或降低特定模型的排名)进行投票。攻击者可以创建大量虚假账户,并使用这些账户进行投票,从而影响排行榜的排名。
关键创新:论文的关键创新在于揭示了基于投票的LLM排行榜的脆弱性,并提出了一种有效的攻击方法。该方法不需要了解模型的内部结构,只需要收集排行榜上的回复数据即可。此外,论文还与Chatbot Arena合作,提出了多种缓解措施,例如reCAPTCHA和登录,提高了排行榜的安全性。
关键设计:模型识别阶段的关键设计是使用合适的分类器和特征。论文使用了多种分类器,包括支持向量机(SVM)和神经网络,并探索了不同的特征,例如回复的长度、词汇和语义信息。投票操纵阶段的关键设计是控制投票的数量和频率,以避免被检测到。论文还考虑了不同的攻击策略,例如随机投票和有针对性的投票。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,攻击者可以以大约一千票的成本来改变Chatbot Arena排行榜的排名。攻击者可以达到超过95%的模型识别准确率。通过实施论文中提出的缓解措施,可以显著提高攻击的成本,从而有效防止恶意攻击。
🎯 应用场景
该研究成果可应用于提升各种基于投票的AI评估系统的安全性,例如LLM排行榜、推荐系统和众包标注平台。通过实施论文中提出的缓解措施,可以有效防止恶意攻击者操纵评估结果,确保评估的公正性和可靠性,从而促进AI技术的健康发展。
📄 摘要(原文)
It is now common to evaluate Large Language Models (LLMs) by having humans manually vote to evaluate model outputs, in contrast to typical benchmarks that evaluate knowledge or skill at some particular task. Chatbot Arena, the most popular benchmark of this type, ranks models by asking users to select the better response between two randomly selected models (without revealing which model was responsible for the generations). These platforms are widely trusted as a fair and accurate measure of LLM capabilities. In this paper, we show that if bot protection and other defenses are not implemented, these voting-based benchmarks are potentially vulnerable to adversarial manipulation. Specifically, we show that an attacker can alter the leaderboard (to promote their favorite model or demote competitors) at the cost of roughly a thousand votes (verified in a simulated, offline version of Chatbot Arena). Our attack consists of two steps: first, we show how an attacker can determine which model was used to generate a given reply with more than $95\%$ accuracy; and then, the attacker can use this information to consistently vote for (or against) a target model. Working with the Chatbot Arena developers, we identify, propose, and implement mitigations to improve the robustness of Chatbot Arena against adversarial manipulation, which, based on our analysis, substantially increases the cost of such attacks. Some of these defenses were present before our collaboration, such as bot protection with Cloudflare, malicious user detection, and rate limiting. Others, including reCAPTCHA and login are being integrated to strengthen the security in Chatbot Arena.