Foundation Models at Work: Fine-Tuning for Fairness in Algorithmic Hiring
作者: Buse Sibel Korkmaz, Rahul Nair, Elizabeth M. Daly, Evangelos Anagnostopoulos, Christos Varytimidis, Antonio del Rio Chanona
分类: cs.LG
发布日期: 2025-01-13
备注: Accepted to AAAI 2025, AI Governance Workshop
💡 一句话要点
提出AutoRefine,通过强化学习微调基础模型,解决算法招聘中的公平性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 算法公平性 强化学习 基础模型微调 算法招聘 语言偏差
📋 核心要点
- 算法招聘平台中的语言偏差会影响推荐系统的公平性,导致候选人匹配结果不够多样化。
- AutoRefine利用强化学习,通过下游任务的性能反馈,有针对性地微调基础模型,无需大量人工标注。
- 实验表明,AutoRefine能有效检测和调节职位描述中的偏差,提升招聘结果的多样性和公平性。
📝 摘要(中文)
基础模型需要经过微调,以确保其生成输出与特定任务的预期结果相符。自动执行此微调过程具有挑战性,因为它通常需要昂贵的人工反馈。我们提出了AutoRefine,一种利用强化学习进行有针对性微调的方法,它利用来自特定下游任务中可衡量的性能改进的直接反馈。我们展示了该方法在算法招聘平台中出现的问题,其中语言偏差会影响推荐系统。在这种情况下,生成模型试图重写给定的职位说明,以从将职位与候选人匹配的推荐引擎中获得更多样化的候选人匹配。我们的模型检测并调节职位描述中的偏差,以满足多样性和公平性标准。在公共招聘数据集和真实招聘平台上的实验表明,大型语言模型如何帮助识别和减轻现实世界中的偏差。
🔬 方法详解
问题定义:论文旨在解决算法招聘中由于职位描述的语言偏差导致推荐系统匹配到的候选人不够多样化和公平的问题。现有方法通常依赖人工反馈进行微调,成本高昂且效率低下。
核心思路:论文的核心思路是利用强化学习自动微调基础模型,使其能够生成更公平、更具多样性的职位描述。通过将下游任务(即推荐系统的匹配结果)的性能反馈作为奖励信号,引导模型学习如何消除职位描述中的偏差。
技术框架:AutoRefine框架包含以下主要模块:1) 职位描述生成模型(基于大型语言模型);2) 推荐引擎(用于匹配职位和候选人);3) 强化学习代理(负责根据推荐结果调整生成模型的策略)。整体流程是:生成模型生成职位描述,推荐引擎根据描述匹配候选人,强化学习代理根据匹配结果(例如,候选人的多样性指标)计算奖励,并更新生成模型的参数。
关键创新:最重要的技术创新点在于利用强化学习自动微调基础模型,无需人工干预。与传统的监督学习方法相比,AutoRefine能够直接优化下游任务的性能指标,从而更好地解决实际问题。
关键设计:论文中,奖励函数的设计至关重要,它需要能够准确衡量候选人的多样性和公平性。具体的奖励函数可能包含多个指标,例如不同种族、性别等群体的候选人比例。此外,强化学习算法的选择和参数设置也会影响模型的性能。论文可能采用了某种策略梯度算法,并对学习率、折扣因子等参数进行了调整。
🖼️ 关键图片

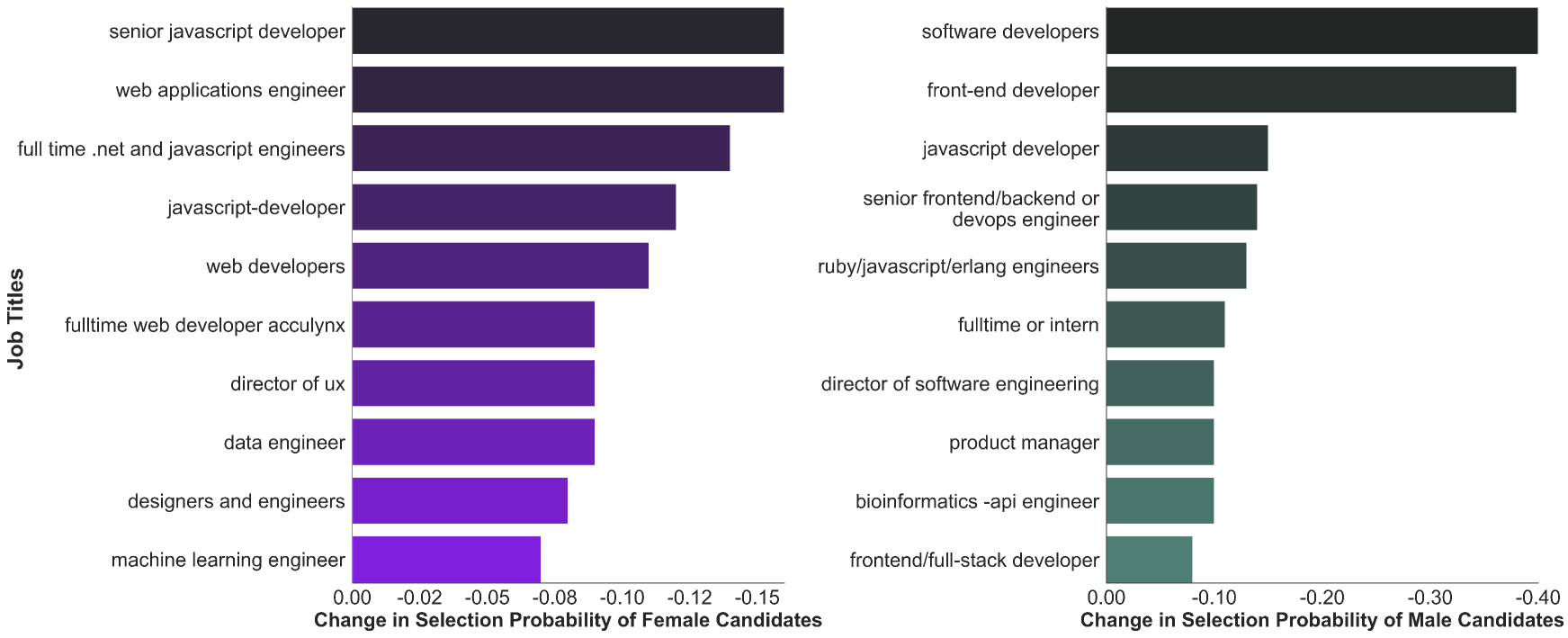
📊 实验亮点
论文在公共招聘数据集和真实招聘平台上进行了实验,验证了AutoRefine的有效性。实验结果表明,AutoRefine能够显著提升推荐结果的多样性和公平性,具体性能数据(如多样性指标的提升幅度)未知,但整体效果优于现有方法。
🎯 应用场景
该研究成果可应用于各种算法招聘平台,帮助企业消除招聘过程中的偏差,提升招聘结果的多样性和公平性。此外,该方法还可以推广到其他领域,例如内容推荐、广告投放等,以解决算法歧视和公平性问题,具有广泛的应用前景。
📄 摘要(原文)
Foundation models require fine-tuning to ensure their generative outputs align with intended results for specific tasks. Automating this fine-tuning process is challenging, as it typically needs human feedback that can be expensive to acquire. We present AutoRefine, a method that leverages reinforcement learning for targeted fine-tuning, utilizing direct feedback from measurable performance improvements in specific downstream tasks. We demonstrate the method for a problem arising in algorithmic hiring platforms where linguistic biases influence a recommendation system. In this setting, a generative model seeks to rewrite given job specifications to receive more diverse candidate matches from a recommendation engine which matches jobs to candidates. Our model detects and regulates biases in job descriptions to meet diversity and fairness criteria. The experiments on a public hiring dataset and a real-world hiring platform showcase how large language models can assist in identifying and mitigation biases in the real world.