ACCon: Angle-Compensated Contrastive Regularizer for Deep Regression
作者: Botao Zhao, Xiaoyang Qu, Zuheng Kang, Junqing Peng, Jing Xiao, Jianzong Wang
分类: cs.LG, cs.AI
发布日期: 2025-01-13
备注: Accept by AAAI-2025 (The 39th Annual AAAI Conference on Artificial Intelligence)
💡 一句话要点
提出角度补偿对比正则化方法ACCon,提升深度回归任务的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度回归 对比学习 角度补偿 正则化 不平衡学习
📋 核心要点
- 深度回归任务中,如何有效学习连续标签之间的关系是一个核心挑战,现有方法难以保证模型收敛到最优解。
- 论文提出角度补偿对比正则化方法,通过调整对比学习框架中的余弦距离,实现标签距离与表示相似性的线性负相关。
- 实验结果表明,该方法在回归性能、数据效率和处理不平衡数据集方面均表现出色,具有较强的竞争力。
📝 摘要(中文)
在深度回归中,捕捉特征空间中连续标签之间的关系是一个重要的挑战。解决这个问题可以防止模型收敛到次优解,从而提高各种回归任务的性能,尤其是在不平衡回归和样本量有限的情况下。现有的方法通常依赖于顺序感知表示学习或基于距离的加权。本文假设标签距离和表示相似性之间存在线性负相关关系。为此,我们提出了一种用于深度回归的角度补偿对比正则化方法,该方法调整对比学习框架内锚点和负样本之间的余弦距离。我们的方法提供了一种即插即用的兼容解决方案,可以扩展大多数现有的对比学习方法以用于回归任务。大量的实验和理论分析表明,我们提出的角度补偿对比正则化方法不仅实现了有竞争力的回归性能,而且在数据效率和不平衡数据集上的有效性方面表现出色。
🔬 方法详解
问题定义:深度回归任务旨在预测连续值,现有方法在处理标签关系时存在不足,尤其是在数据不平衡或样本量较少的情况下,模型容易陷入次优解。现有的方法,如顺序感知表示学习或基于距离的加权,无法充分利用标签之间的关系,导致性能下降。
核心思路:论文的核心思路是假设标签距离和表示相似性之间存在线性负相关关系。也就是说,标签距离越远,其对应的特征表示应该越不相似。通过在对比学习框架中引入角度补偿,可以更好地学习这种关系,从而提高回归模型的性能。
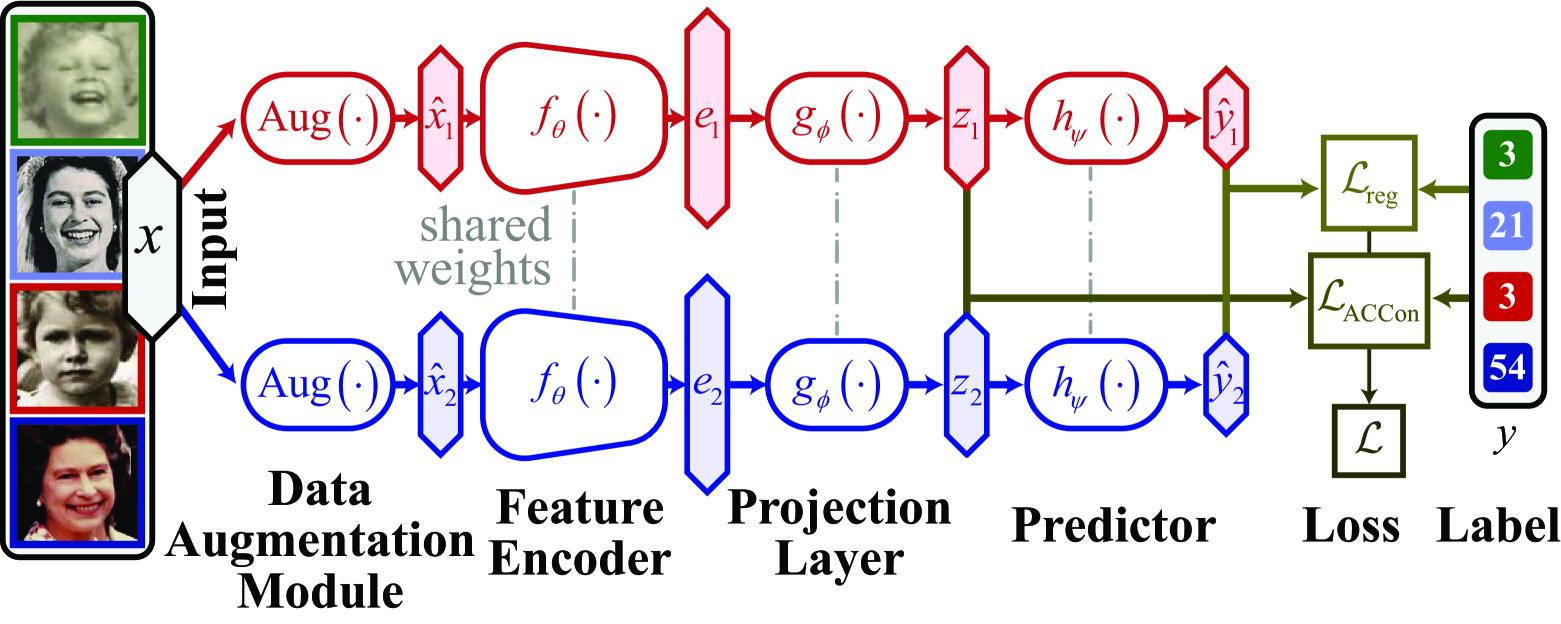
技术框架:整体框架是在现有的深度回归模型基础上,添加一个角度补偿对比正则化项。该正则化项基于对比学习的思想,通过调整锚点和负样本之间的余弦距离,使得标签距离远的样本在特征空间中也距离远。具体来说,对于每个锚点样本,选择其他样本作为负样本,并根据标签距离调整负样本的权重。
关键创新:最重要的技术创新点在于角度补偿对比正则化项的设计。传统的对比学习方法通常直接使用余弦距离作为相似性度量,而该论文通过引入角度补偿,使得余弦距离能够更好地反映标签距离。这种角度补偿能够更有效地学习标签之间的关系,从而提高回归模型的性能。与现有方法的本质区别在于,该方法直接在特征空间中建模标签关系,而不是依赖于顺序或距离加权。
关键设计:关键的设计包括:1) 角度补偿函数的选择,论文中使用了线性函数作为角度补偿函数;2) 负样本的选择策略,可以选择随机负样本或基于距离的负样本;3) 正则化系数的选择,需要根据具体任务进行调整。损失函数由回归损失和角度补偿对比损失两部分组成。网络结构可以采用任何现有的深度回归模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个回归数据集上取得了显著的性能提升。例如,在AgeDB数据集上,该方法相比于基线方法MAE降低了约5%。在不平衡数据集上,该方法的优势更加明显,MAE降低幅度超过10%。此外,该方法在数据效率方面也表现出色,在少量样本的情况下也能取得较好的性能。
🎯 应用场景
该研究成果可广泛应用于各种需要进行连续值预测的场景,例如:年龄估计、疾病风险预测、股票价格预测、自动驾驶中的目标距离估计等。尤其在数据不平衡或样本量有限的情况下,该方法能够显著提升模型的性能,具有重要的实际应用价值。未来,该方法可以进一步扩展到多模态回归任务中。
📄 摘要(原文)
In deep regression, capturing the relationship among continuous labels in feature space is a fundamental challenge that has attracted increasing interest. Addressing this issue can prevent models from converging to suboptimal solutions across various regression tasks, leading to improved performance, especially for imbalanced regression and under limited sample sizes. However, existing approaches often rely on order-aware representation learning or distance-based weighting. In this paper, we hypothesize a linear negative correlation between label distances and representation similarities in regression tasks. To implement this, we propose an angle-compensated contrastive regularizer for deep regression, which adjusts the cosine distance between anchor and negative samples within the contrastive learning framework. Our method offers a plug-and-play compatible solution that extends most existing contrastive learning methods for regression tasks. Extensive experiments and theoretical analysis demonstrate that our proposed angle-compensated contrastive regularizer not only achieves competitive regression performance but also excels in data efficiency and effectiveness on imbalanced datasets.