Combining LLM decision and RL action selection to improve RL policy for adaptive interventions
作者: Karine Karine, Benjamin M. Marlin
分类: cs.LG, cs.AI
发布日期: 2025-01-13
💡 一句话要点
结合LLM决策与RL动作选择,提升自适应干预的RL策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 自适应干预 个性化推荐 人机协作
📋 核心要点
- 强化学习在医疗健康领域的个性化自适应干预中应用日益广泛,但现有方法难以快速适应用户偏好。
- 该论文提出一种混合方法,结合LLM的决策能力和RL的动作选择,利用用户文本偏好实时更新RL策略。
- 通过模拟环境验证,该方法能够有效整合用户偏好,并在改进RL策略的同时,提升自适应干预的个性化水平。
📝 摘要(中文)
本文提出了一种混合方法,旨在通过结合大型语言模型(LLM)的响应和强化学习(RL)的动作选择来改进RL策略,从而加速个性化自适应干预。该方法利用基于文本的用户偏好来实时影响动作选择,从而立即整合用户偏好。LLM在典型的RL动作选择中充当过滤器,通过包含用户偏好的提示来引导动作选择。论文探讨了不同的提示策略和动作选择策略。为了评估该方法,作者实现了一个模拟环境,该环境生成基于文本的用户偏好并模拟影响行为动态的约束。实验结果表明,该方法能够考虑基于文本的用户偏好,同时改进RL策略,从而提高自适应干预的个性化程度。
🔬 方法详解
问题定义:现有强化学习方法在自适应干预中,难以快速有效地整合用户的个性化偏好,导致策略调整速度慢,无法及时响应用户需求。传统的RL方法通常依赖于历史数据进行学习,对于新出现的、基于文本的用户偏好信息难以直接利用。
核心思路:该论文的核心思路是将大型语言模型(LLM)作为RL策略的辅助决策模块,利用LLM强大的自然语言理解和生成能力,将用户的文本偏好转化为对RL动作选择的指导。通过LLM对RL动作进行过滤或调整,使得最终的动作选择能够更好地满足用户的个性化需求。
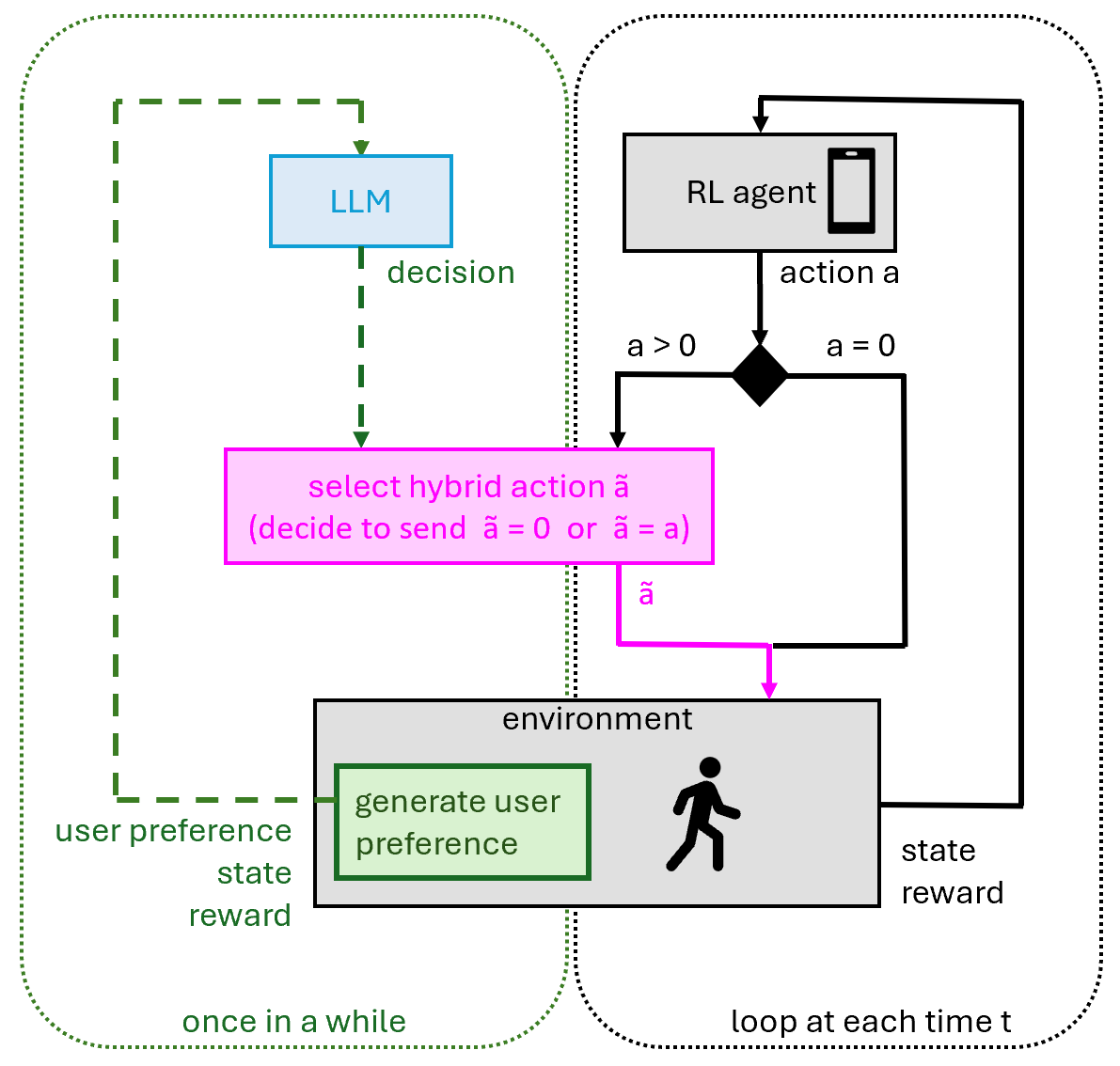
技术框架:整体框架包含以下几个主要模块:1) 用户偏好输入模块:接收用户输入的文本偏好信息。2) LLM决策模块:根据用户偏好,利用预设的prompt策略生成对动作选择的建议。3) RL动作选择模块:基于当前状态和RL策略,生成候选动作。4) 混合决策模块:结合LLM的建议和RL的动作选择,最终确定执行的动作。5) 环境交互模块:执行动作并获得环境反馈,用于更新RL策略。
关键创新:该方法最重要的创新点在于将LLM与RL相结合,利用LLM的文本理解能力来增强RL策略的个性化适应能力。与传统的RL方法相比,该方法能够直接利用用户的文本偏好信息,实现更快速、更灵活的策略调整。
关键设计:论文中涉及的关键设计包括:1) Prompt策略:设计不同的prompt,引导LLM生成有效的动作选择建议。2) 动作选择策略:设计不同的策略,将LLM的建议与RL的动作选择相结合,例如,LLM作为过滤器,只允许符合用户偏好的动作被选择。3) 模拟环境:构建一个能够生成基于文本的用户偏好并模拟行为动态的仿真环境,用于评估该方法的性能。
🖼️ 关键图片
📊 实验亮点
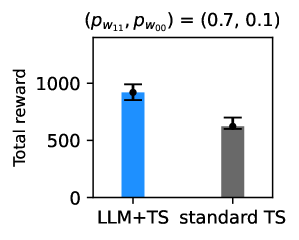
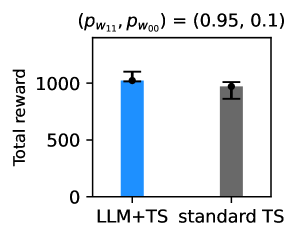
该论文通过模拟实验验证了所提出方法的有效性。实验结果表明,该方法能够有效地整合用户的文本偏好,并在改进RL策略的同时,提升自适应干预的个性化水平。具体的性能数据和对比基线(如传统RL方法)的提升幅度在论文中进行了详细展示,但具体数值未知。
🎯 应用场景
该研究成果可应用于个性化医疗健康干预、智能推荐系统、人机协作等领域。例如,在慢性病管理中,可以根据患者的饮食偏好和运动习惯,结合LLM和RL,制定个性化的治疗方案。在智能家居领域,可以根据用户的舒适度偏好,调整室内温度和光照,提升用户体验。该方法具有广泛的应用前景和实际价值。
📄 摘要(原文)
Reinforcement learning (RL) is increasingly being used in the healthcare domain, particularly for the development of personalized health adaptive interventions. Inspired by the success of Large Language Models (LLMs), we are interested in using LLMs to update the RL policy in real time, with the goal of accelerating personalization. We use the text-based user preference to influence the action selection on the fly, in order to immediately incorporate the user preference. We use the term "user preference" as a broad term to refer to a user personal preference, constraint, health status, or a statement expressing like or dislike, etc. Our novel approach is a hybrid method that combines the LLM response and the RL action selection to improve the RL policy. Given an LLM prompt that incorporates the user preference, the LLM acts as a filter in the typical RL action selection. We investigate different prompting strategies and action selection strategies. To evaluate our approach, we implement a simulation environment that generates the text-based user preferences and models the constraints that impact behavioral dynamics. We show that our approach is able to take into account the text-based user preferences, while improving the RL policy, thus improving personalization in adaptive intervention.