Transfer Learning of Tabular Data by Finetuning Large Language Models
作者: Shourav B. Rabbani, Ibna Kowsar, Manar D. Samad
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-12
💡 一句话要点
通过微调大型语言模型实现表格数据的迁移学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据 迁移学习 大型语言模型 微调 分类 自然语言处理 深度学习
📋 核心要点
- 深度学习在表格数据上表现不佳,主要原因是表格数据的异构性和缺乏有效的迁移学习方法。
- 该论文提出了一种端到端的LLM微调方法,利用大型语言模型进行表格数据的迁移学习。
- 实验结果表明,该方法在小特征表格数据集上优于现有的机器学习和深度学习方法,且计算成本更低。
📝 摘要(中文)
尽管人工智能(AI)取得了革命性进展,但由于异构特征空间和有限的样本量,且缺乏可行的迁移学习方法,深度学习在表格数据方面尚未取得显著成功。生成式AI的新时代,由大型语言模型(LLM)驱动,为多样化的数据和领域带来了前所未有的学习机会。本文研究了LLM应用程序编程接口(API)和LLM迁移学习在表格数据分类中的有效性。LLM API通过token化的数据和指令响应输入文本提示,而迁移学习则微调LLM以适应目标分类任务。本文提出了一种端到端的LLM微调方法,以展示在缺乏大型预训练表格数据模型来促进迁移学习时,跨十个基准数据集的数据迁移学习。所提出的LLM微调方法在特征数量少于十个的表格数据上优于最先进的机器学习和深度学习方法——这是表格数据集的标准特征大小。与其他基于深度学习或API的解决方案相比,该迁移学习方法使用的计算成本更低,同时确保了具有竞争力的或更优越的分类性能。
🔬 方法详解
问题定义:论文旨在解决表格数据分类中,由于数据异构性和样本量有限,深度学习模型难以有效训练的问题。现有方法,如传统的机器学习模型,在处理复杂关系时能力有限;而深度学习模型又需要大量数据,且难以进行有效的迁移学习。
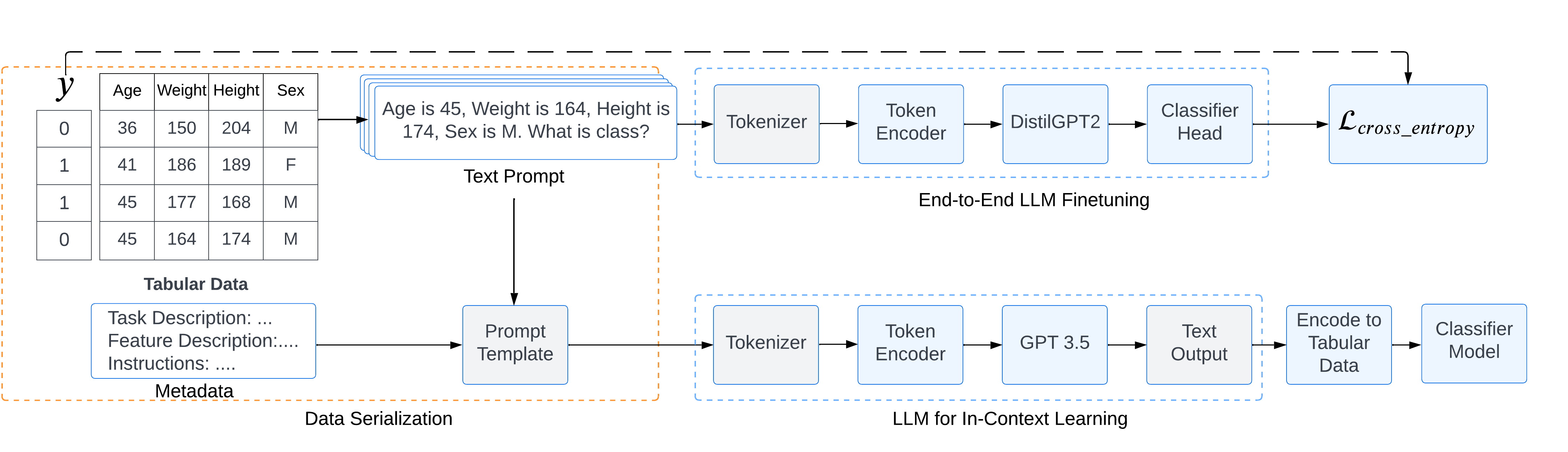
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,将表格数据转换为文本提示,然后通过微调LLM来学习表格数据的特征表示,从而实现迁移学习。这种方法避免了直接在表格数据上训练深度学习模型,降低了对数据量的需求,并利用了LLM的预训练知识。
技术框架:整体框架包括以下几个步骤:1) 将表格数据转换为文本提示;2) 使用预训练的LLM对文本提示进行编码;3) 在编码后的表示上添加一个分类层;4) 使用目标表格数据集对整个模型进行微调。该框架是一个端到端的流程,可以直接从原始表格数据到分类结果。
关键创新:最重要的创新点在于将LLM应用于表格数据分类,并提出了一种有效的微调方法。与传统的表格数据处理方法相比,该方法利用了LLM的预训练知识,从而在小数据集上也能取得良好的性能。此外,该方法还避免了手动特征工程,降低了人工成本。
关键设计:关键设计包括:1) 如何将表格数据转换为有效的文本提示,例如使用自然语言描述每个特征和值;2) 选择合适的预训练LLM,例如BERT或GPT系列;3) 设计合适的分类层,例如一个简单的线性层;4) 选择合适的微调策略,例如冻结部分LLM参数,只微调分类层和部分LLM参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在十个基准表格数据集上取得了优于现有机器学习和深度学习方法的性能,尤其是在特征数量较少的数据集上。例如,在某个数据集上,该方法比最先进的机器学习方法提高了5%的准确率,同时计算成本显著降低。这些结果验证了该方法在表格数据迁移学习方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要处理表格数据的领域,如金融风控、医疗诊断、客户关系管理等。通过利用预训练的LLM,可以降低模型训练成本,提高模型泛化能力,从而更好地解决实际问题。未来,该方法有望扩展到更复杂的表格数据分析任务,如回归、聚类等。
📄 摘要(原文)
Despite the artificial intelligence (AI) revolution, deep learning has yet to achieve much success with tabular data due to heterogeneous feature space and limited sample sizes without viable transfer learning. The new era of generative AI, powered by large language models (LLM), brings unprecedented learning opportunities to diverse data and domains. This paper investigates the effectiveness of an LLM application programming interface (API) and transfer learning of LLM in tabular data classification. LLM APIs respond to input text prompts with tokenized data and instructions, whereas transfer learning finetunes an LLM for a target classification task. This paper proposes an end-to-end finetuning of LLM to demonstrate cross-data transfer learning on ten benchmark data sets when large pre-trained tabular data models do not exist to facilitate transfer learning. The proposed LLM finetuning method outperforms state-of-the-art machine and deep learning methods on tabular data with less than ten features - a standard feature size for tabular data sets. The transfer learning approach uses a fraction of the computational cost of other deep learning or API-based solutions while ensuring competitive or superior classification performance.