Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
作者: Muru Zhang, Mayank Mishra, Zhongzhu Zhou, William Brandon, Jue Wang, Yoon Kim, Jonathan Ragan-Kelley, Shuaiwen Leon Song, Ben Athiwaratkun, Tri Dao
分类: cs.LG, cs.CL, cs.DC
发布日期: 2025-01-11 (更新: 2025-06-19)
备注: ICML 2025
💡 一句话要点
提出Ladder Residual架构,通过通信重叠加速大模型并行推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型并行 分布式推理 通信重叠 Ladder Residual Transformer 大语言模型 架构优化
📋 核心要点
- 模型并行推理受限于GPU间通信瓶颈,降低了扩展设备带来的性能提升。
- Ladder Residual通过架构修改解耦通信与计算,实现通信延迟隐藏。
- 实验表明,Ladder Residual在70B模型上实现了29%的推理加速,且训练的Ladder Transformer性能与基线相当。
📝 摘要(中文)
大型语言模型推理在内存和时间上都非常密集,通常需要分布式算法来有效扩展。多GPU训练和推理中使用各种模型并行策略,以在多个设备上划分计算,从而减少内存负载和计算时间。然而,使用模型并行需要GPU之间的信息通信,这是一个主要的瓶颈,限制了扩展设备数量所获得的收益。我们引入了Ladder Residual,这是一种适用于所有基于残差模型的简单架构修改,可以实现直接的重叠,从而有效地隐藏通信的延迟。我们的见解是,除了系统优化之外,还可以重新设计模型架构,以将通信与计算分离。虽然Ladder Residual可以在传统的并行模式中实现通信-计算解耦,但本文重点关注张量并行,它尤其受到大量通信的瓶颈。对于具有70B参数的Transformer模型,将Ladder Residual应用于其所有层可以在推理时通过在8个设备上进行TP分片来实现29%的端到端挂钟加速。我们将生成的Transformer模型称为Ladder Transformer。我们从头开始训练了一个1B和3B的Ladder Transformer,并观察到与标准密集Transformer基线相当的性能。我们还表明,通过仅重新训练3B个token,可以将Llama-3.1 8B模型的部分转换为我们的Ladder Residual架构,且精度下降最小。我们发布了用于训练和推理的代码,以便更容易地复制实验。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型在分布式推理时,由于模型并行引入的GPU间通信开销过大,导致推理速度受限的问题。现有方法主要集中在系统优化层面,而忽略了模型架构本身对通信效率的影响。
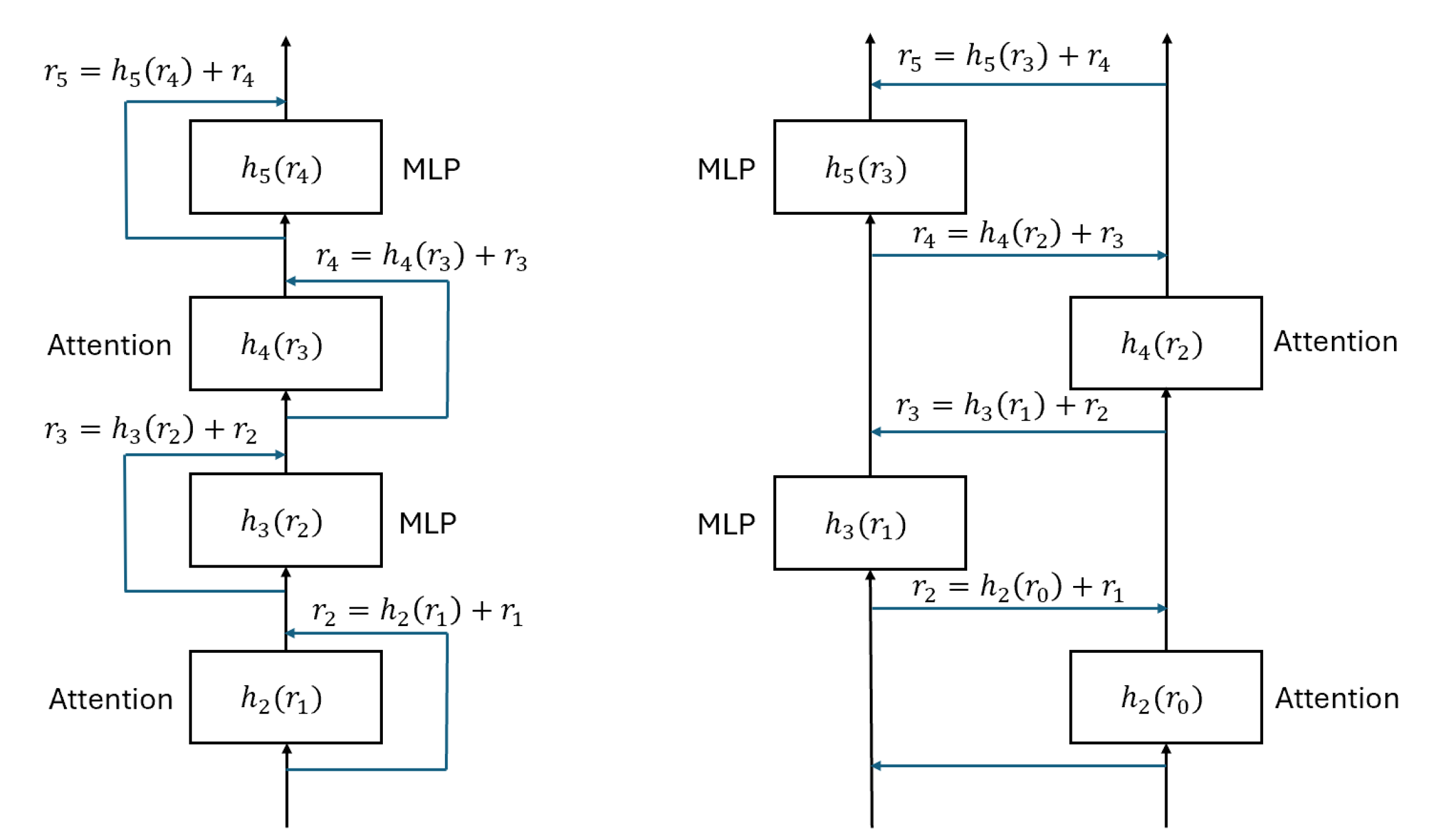
核心思路:论文的核心思路是通过修改模型架构,将通信操作与计算操作解耦,从而允许通信与计算并行执行,隐藏通信延迟。Ladder Residual架构通过引入额外的残差连接,使得部分计算可以在通信完成之前开始,从而实现通信重叠。
技术框架:Ladder Residual可以应用于任何基于残差连接的模型,特别是Transformer模型。在Transformer中,每个Transformer层都会被修改为Ladder Residual结构。具体来说,原始的残差连接被拆分为两个部分,一部分直接连接到下一层,另一部分通过一个额外的线性层后再连接到下一层。这种结构允许一部分计算在接收到所有输入之前开始。
关键创新:论文的关键创新在于提出了Ladder Residual架构,这是一种简单而有效的模型架构修改,可以显著减少分布式推理中的通信开销。与传统的系统优化方法相比,Ladder Residual从模型架构层面入手,实现了通信与计算的解耦。
关键设计:Ladder Residual的关键设计在于残差连接的拆分。通过将残差连接拆分为两部分,一部分直接连接到下一层,另一部分通过一个额外的线性层后再连接到下一层,从而允许一部分计算在接收到所有输入之前开始。线性层的参数需要进行训练,以保证模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在具有70B参数的Transformer模型上,应用Ladder Residual架构后,使用8个GPU进行张量并行推理时,端到端推理速度提升了29%。此外,从头训练的1B和3B Ladder Transformer模型与标准Transformer模型相比,性能相当。通过少量数据(3B tokens)的微调,可以将Llama-3.1 8B模型的部分层转换为Ladder Residual架构,且精度损失很小。
🎯 应用场景
Ladder Residual架构可广泛应用于需要大规模模型并行推理的场景,例如在线对话系统、机器翻译、文本生成等。该方法能够有效提升推理速度,降低延迟,从而改善用户体验。此外,该架构还有助于降低推理成本,使得大规模语言模型能够更广泛地部署在资源受限的环境中。
📄 摘要(原文)
Large language model inference is both memory-intensive and time-consuming, often requiring distributed algorithms to efficiently scale. Various model parallelism strategies are used in multi-gpu training and inference to partition computation across multiple devices, reducing memory load and computation time. However, using model parallelism necessitates communication of information between GPUs, which has been a major bottleneck and limits the gains obtained by scaling up the number of devices. We introduce Ladder Residual, a simple architectural modification applicable to all residual-based models that enables straightforward overlapping that effectively hides the latency of communication. Our insight is that in addition to systems optimization, one can also redesign the model architecture to decouple communication from computation. While Ladder Residual can allow communication-computation decoupling in conventional parallelism patterns, we focus on Tensor Parallelism in this paper, which is particularly bottlenecked by its heavy communication. For a Transformer model with 70B parameters, applying Ladder Residual to all its layers can achieve 29% end-to-end wall clock speed up at inference time with TP sharding over 8 devices. We refer the resulting Transformer model as the Ladder Transformer. We train a 1B and 3B Ladder Transformer from scratch and observe comparable performance to a standard dense transformer baseline. We also show that it is possible to convert parts of the Llama-3.1 8B model to our Ladder Residual architecture with minimal accuracy degradation by only retraining for 3B tokens. We release our code for training and inference for easier replication of experiments.